بإيجاز
- أصدرت Microsoft وضعين مختلفين لاقتران GPT وClaude بهدف رفع جودة أبحاث الذكاء الاصطناعي.
- يتيح النقد (Critique) للنماذج التعاون، بينما يجعل المجلس (Council) النماذج تعمل بالتوازي مع وجود قاضٍ ثالث يحدد التباينات.
- يصلح سير العمل المكوّن من نموذجين هذا حالات الهلوسة، وضعف الاستشهادات، وغيرها من المشكلات المرتبطة بأبحاث الذكاء الاصطناعي التي تعتمد على نموذج واحد.
يُعدّ الذكاء الاصطناعي للبحث العميق (Deep research) أحد أكثر سباقات التسلّح سخونة في مجال التكنولوجيا هذا العام. أعلنت Google عن وكيلها البحثي الخاص بـ Gemini في ديسمبر 2024، وأطلقت OpenAI وكيلها البحثي الخاص في فبراير 2025، وتبعَت xAI الخطوة، وتضاعفت Perplexity في دعمها، وبنى Claude من Anthropic قاعدة ولاء بين المهنيين الذين يحتاجون إلى إجابات تفصيلية ومدعومة بمراجع، حيث قدّم وكيله في أبريل من العام الماضي.
كانت كل شركة تحاول إقناعك بأن نموذجها الذكائي الواحد هو “الأذكى” بين الباحثين في الغرفة. قالت Microsoft للتو: لماذا تختار واحدًا فقط؟
أعلنت الشركة يوم الاثنين عن ميزتين جديدتين لأداة Researcher في Copilot—تُسمّيان Critique وCouncil—وتضعان GPT من OpenAI وClaude من Anthropic للعمل على مهمة بحث واحدة في تسلسل. وتقول نتيجة اختبار Microsoft مقارنةً بمعيار صناعي إنها تسجل درجات أعلى من كل الأنظمة المدرجة في ذلك الاختبار، بما في ذلك نماذج من كبرى شركات الذكاء الاصطناعي.
تقديم Critique، نظام بحث عميق متعدد النماذج جديد في M365 Copilot.
يمكنك استخدام عدة نماذج معًا لتوليد استجابات وتقارير مثالية. pic.twitter.com/m4RlQmCKzs
— ساتيا ناديلا (@satyanadella) 30 مارس 2026
“Critique هو نظام بحث عميق جديد متعدد النماذج مُصمم لمهام البحث المعقدة. يفصل بين عملية التوليد والتقييم ويستخدم مجموعة من النماذج من مختبرات Frontier، بما في ذلك Anthropic وOpenAI”، كما تشرح Microsoft. “يقود نموذج واحد مرحلة التوليد: يخطط للمهمة، ويتكرر عبر عملية الاسترجاع، ويُنتج مسودة أولية، بينما يركز نموذج ثانٍ على المراجعة والتحسين، ويعمل كمراجع خبير قبل إنتاج التقرير النهائي.”
تتمثل المشكلة الأساسية التي صُمم Critique لمعالجتها فيما يلي: تعمل كل أدوات البحث عن طريق الذكاء الاصطناعي بالطريقة نفسها تقريبًا اليوم. تطرح سؤالًا، فيخطط نموذج واحد للبحث، ويتفحص المصادر، ويكتب تقريرًا، ثم يعيد تقديمه لك. يقوم هذا النموذج الواحد بكل شيء دون وجود من يتحقق من عمله.
وقد يؤدي ذلك إلى تسلل بعض حالات الهلوسة، ووجود أخطاء في الاستشهادات، ومزاعم مزيفة أو غير دقيقة، إلخ.
يكسر Critique سير العمل هذا إلى جزأين. يتولى GPT المرحلة الأولى—يخطط للبحث، ويستخرج المصادر، ويكتب مسودة أولية. ثم يدخل Claude ليقوم بدور محرر صارم، إذ يراجع التقرير من حيث الدقة الواقعية وجودة الاستشهادات وما إذا كانت الإجابة قد عالجت فعلاً ما طُلب. لا يصل التقرير النهائي إلى المستخدم إلا بعد هذه المراجعة. تقول Microsoft إن الأدوار يمكن أن تعمل في الاتجاه المعاكس أيضًا في النهاية، حيث يكتب Claude بينما ينتقد GPT، لكن في الوقت الحالي يبدأ GPT أولاً.
على معيار DRACO—وهو اختبار موحّد يغطي 100 مهمة بحث معقدة عبر 10 مجالات تشمل الطب والقانون والتكنولوجيا—سجل Copilot مع Critique 57.4 نقطة. بينما حقق Claude Opus من Anthropic وحده 42.7 فقط. يتفوق النظام المدمج لدى Microsoft على أفضل نتيجة تالية بنسبة تقارب 14%.
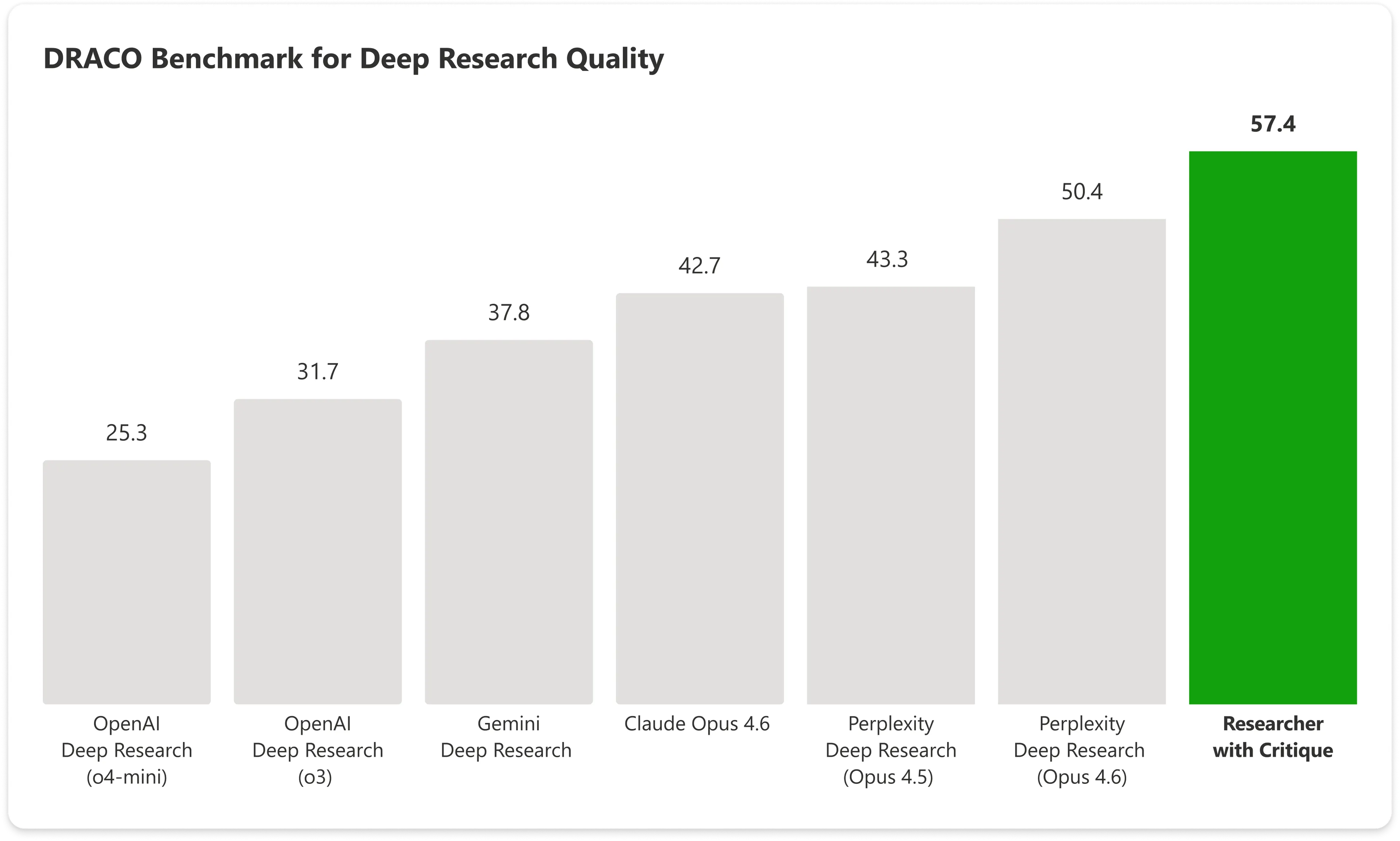
الصورة: Microsoft
أبرز الزيادات ظهرت في سعة نطاق التحليل وجودة العرض، مع تسجيل تحسنٍ كبير كذلك في الدقة الواقعية.
تأخذ الميزة الثانية، Council، نهجًا مختلفًا لحل المشكلة نفسها. بدلًا من أن يراجع نموذج عمل النموذج الآخر، يشغّل Council GPT وClaude في الوقت نفسه ويضع تقاريره الكاملة جنبًا إلى جنب. ثم يقرأ نموذج “قاضٍ” ثالث كلا التقريرين ويكتب ملخصًا يوضح أين اتفق الذكاءان الاصطناعيان، وأين اختلفا، وما هي الزوايا الفريدة التي التقطها كل واحد منهما ولم ينتبه لها الآخر. كان على المستخدمين حتى الآن مقارنة أدوات البحث الخاصة بالذكاء الاصطناعي يدويًا بأنفسهم.
في Critique، تتعاون النماذج في الأساس مع بعضها، بينما في Council تتنافس النماذج ضد بعضها.
يُعدّ Critique التجربة الافتراضية في Researcher، بينما يتطلب Council منك اختيار “Model Council” من أداة الاختيار لتفعيل وضع العرض جنبًا إلى جنب. تتوفر الميزتان حاليًا للمستخدمين المسجلين في برنامج Frontier لدى Microsoft، وهي قناة الوصول المبكر لقدرات Copilot الأحدث. يلزم ترخيص Microsoft 365 Copilot (30 دولارًا/مستخدم/شهر)، لكن يتعين أيضًا أن يكون المستخدمون مسجلين في Frontier للوصول إليهما.
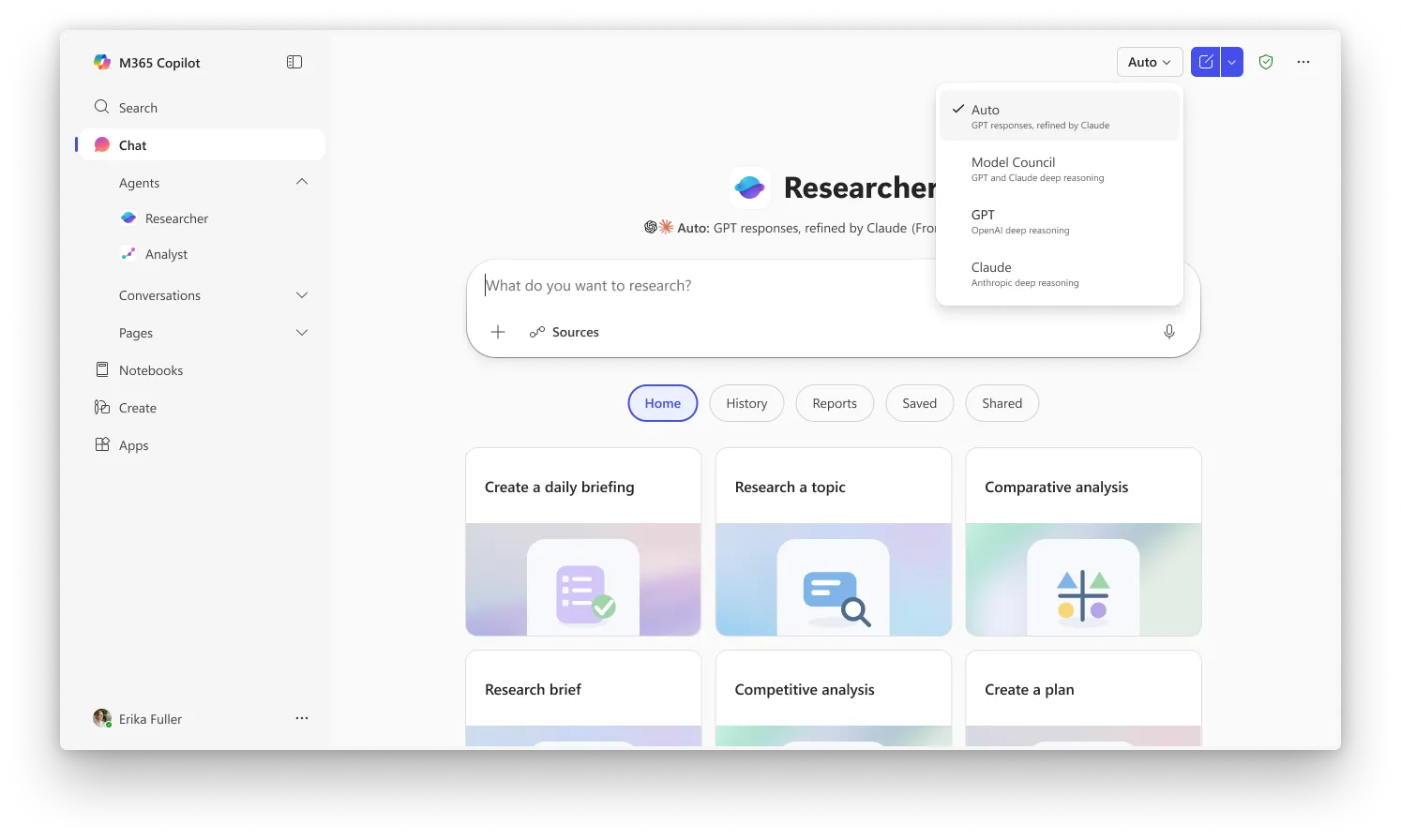
الصورة: Microsoft
لدى OpenAI وMicrosoft شراكة تمتد بمئات المليارات من الدولارات، لكن رهان Microsoft هو أنه لن يبقى أي نموذج واحد في القمة لفترة طويلة، وأن القيمة الحقيقية تكمن في طبقة التنسيق التي توجه المهام إلى أي مجموعة من النماذج تعمل بشكل أفضل.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
