En el momento de la publicación de este artículo, Amazon Web Services está sufriendo una importante interrupción que vuelve a poner en jaque la infraestructura cripto. Desde aproximadamente las 8:00 (hora británica) de hoy, los problemas de AWS en la región US-EAST-1 (centros de datos en Virginia del Norte) han dejado fuera de servicio a Coinbase junto a decenas de grandes plataformas de criptomonedas, entre ellas Robinhood, Infura, Base y Solana.
AWS ha reconocido “un aumento en la tasa de errores” que afecta a Amazon DynamoDB y EC2, los servicios centrales de bases de datos y computación de los que dependen miles de compañías. Este corte en tiempo real valida de manera inmediata y contundente la tesis central del artículo: la dependencia de la infraestructura cripto respecto a proveedores centralizados de la nube genera vulnerabilidades sistémicas que se repiten una y otra vez bajo situaciones de estrés.
La coyuntura es especialmente reveladora. Apenas diez días después de la cascada de liquidaciones de 19 300 millones de dólares que dejó al descubierto fallos de infraestructura a nivel de exchange, la caída de AWS hoy demuestra que el problema trasciende las plataformas concretas y alcanza la capa fundamental de la infraestructura en la nube. Cuando AWS falla, el efecto dominó impacta en exchanges centralizados, plataformas «descentralizadas» con dependencias críticas y en innumerables servicios de forma simultánea.
No es un incidente aislado, sino un patrón recurrente. El análisis siguiente documenta interrupciones similares de AWS en abril de 2025, diciembre de 2021 y marzo de 2017, cada una de las cuales paralizó grandes servicios cripto. La cuestión no es si se producirá el próximo fallo de infraestructura, sino cuándo y qué lo desencadenará.
Cascada de liquidaciones del 10-11 de octubre de 2025: caso de estudio
La cascada de liquidaciones del 10 y 11 de octubre de 2025 constituye un caso de estudio revelador sobre los modos de fallo de la infraestructura. A las 20:00 (UTC), un anuncio geopolítico de gran impacto desencadenó ventas masivas en el mercado. En solo una hora, se liquidaron 6 000 millones de dólares. Cuando abrieron los mercados asiáticos, 19 300 millones de dólares en posiciones apalancadas habían desaparecido en 1,6 millones de cuentas de traders.
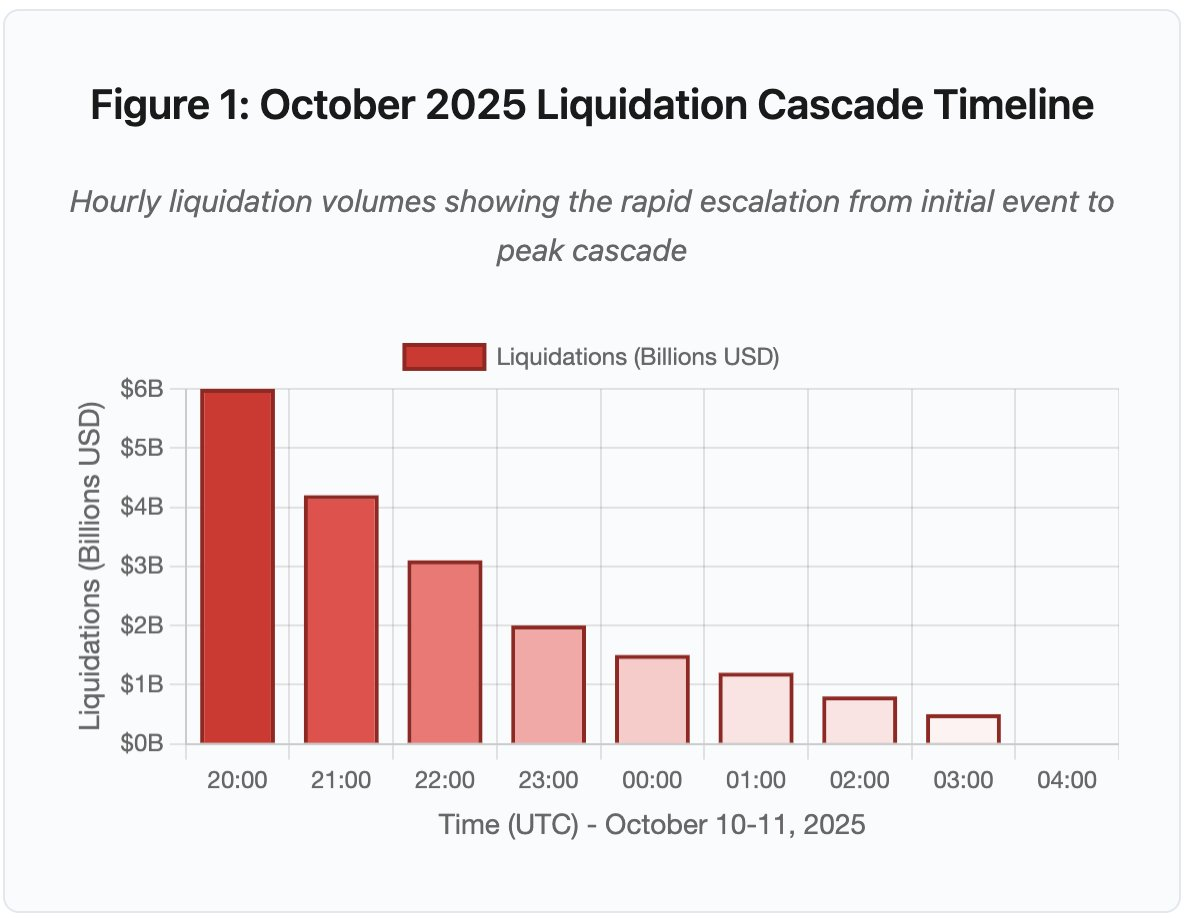
Figura 1: Cronología de la cascada de liquidaciones en octubre de 2025
El gráfico interactivo de la cronología muestra la evolución dramática de las liquidaciones hora a hora. Solo en la primera hora se evaporaron 6 000 millones de dólares, seguidos de una segunda hora aún más intensa a medida que la cascada se aceleraba. La visualización revela:
- 20:00-21:00: Choque inicial - 6 000 M$ liquidados (zona roja)
- 21:00-22:00: Pico de la cascada - 4 200 M$ con inicio de limitación de API
- 22:00-04:00: Degradación prolongada - 9 100 M$ en mercados poco líquidos
- Puntos clave de inflexión: límites en la API, retirada de creadores de mercado, agotamiento de los libros de órdenes
La magnitud supera cualquier evento previo en el mercado cripto al menos en un orden de magnitud. La comparación histórica muestra el carácter abrupto de este suceso:
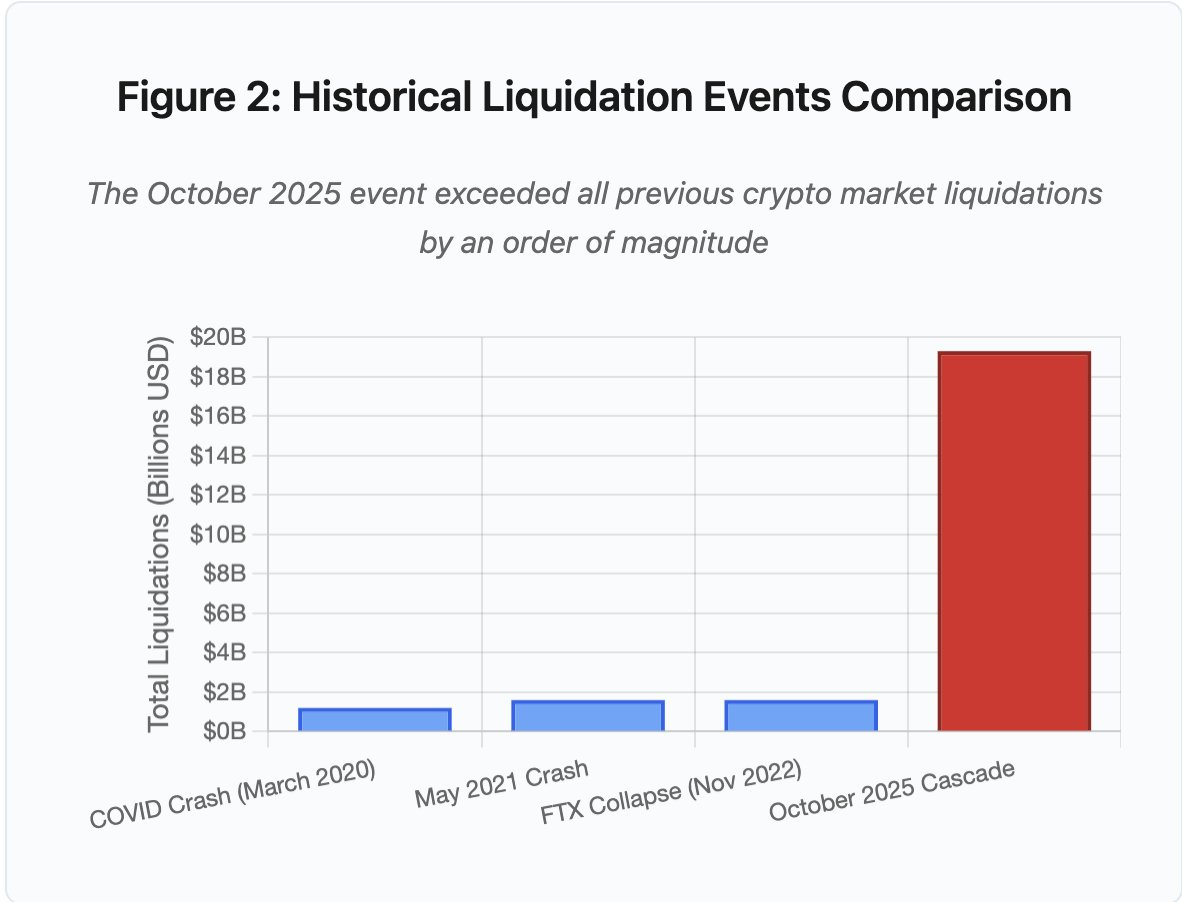
Figura 2: Comparativa de eventos históricos de liquidación
El gráfico de barras ilustra de forma contundente cómo octubre de 2025 destaca sobre el resto:
- Marzo de 2020 (COVID): 1 200 M$
- Mayo de 2021 (Crash): 1 600 M$
- Noviembre de 2022 (FTX): 1 600 M$
- Octubre de 2025: 19 300 M$ ⚠️ 16 veces superior al récord anterior
Sin embargo, las cifras de liquidación solo muestran una parte de la historia. La cuestión relevante es el mecanismo: ¿cómo los eventos externos del mercado desencadenaron este modo específico de fallo? La respuesta revela debilidades sistemáticas tanto en la infraestructura de exchanges centralizados como en el diseño de los protocolos blockchain.
Fallos off-chain: arquitectura de exchange centralizado
Sobrecarga de infraestructura y límites de velocidad
Las APIs de los exchanges aplican límites de velocidad para evitar abusos y gestionar la carga de los servidores. En condiciones normales, estos límites permiten el trading legítimo y bloquean posibles ataques. Sin embargo, en situaciones de volatilidad extrema, cuando miles de traders intentan simultáneamente ajustar sus posiciones, estos mismos límites se convierten en cuellos de botella.
Los CEX limitan las notificaciones de liquidación a una orden por segundo, incluso cuando procesan miles por segundo. Durante la cascada de octubre, esto generó opacidad. Los usuarios no podían determinar la gravedad de la cascada en tiempo real. Herramientas externas mostraban cientos de liquidaciones por minuto mientras los feeds oficiales reflejaban muchas menos.
Los límites en la API impidieron que los traders modificaran sus posiciones durante la crucial primera hora. Las solicitudes de conexión expiraban. El envío de órdenes fallaba. Las órdenes stop-loss no se ejecutaban. Las consultas de posiciones devolvían datos obsoletos. Este cuello de botella transformó un evento de mercado en una crisis operativa.
Los exchanges tradicionales dimensionan la infraestructura para cargas normales con un margen de seguridad. Pero la carga habitual difiere enormemente de la carga en situaciones de estrés. El volumen medio de trading diario predice mal las necesidades máximas. En cascadas, el volumen de transacciones puede multiplicarse por 100 o más. Las consultas de posición aumentan por 1 000, ya que cada usuario comprueba su cuenta al mismo tiempo.
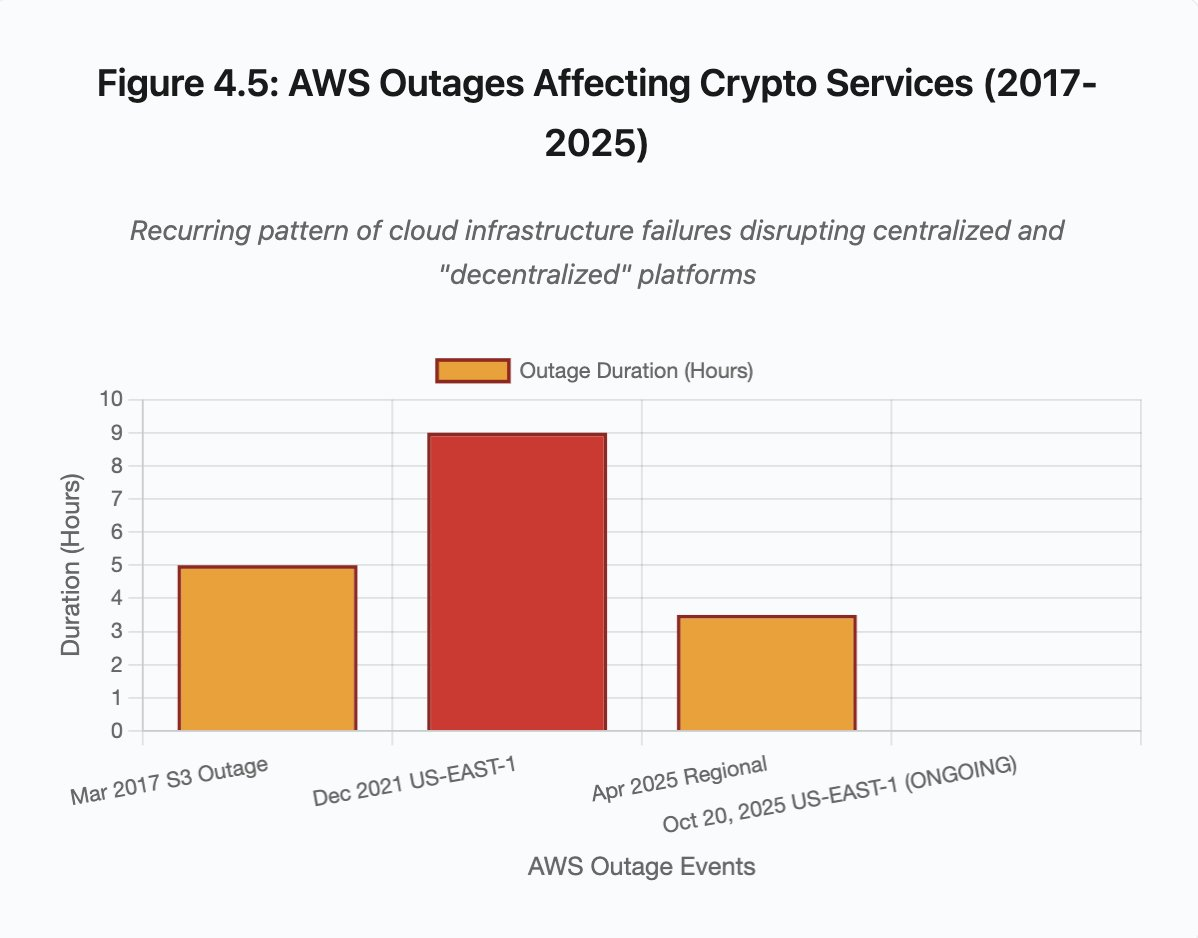
Figura 4.5: Interrupciones de AWS que afectan a servicios cripto
La infraestructura en la nube con escalado automático ayuda, pero no responde de manera instantánea. Crear réplicas adicionales de la base de datos lleva minutos. Generar nuevas instancias de pasarela API también lleva minutos. Durante esos minutos, los sistemas de margen continúan valorando posiciones en base a precios corruptos de libros de órdenes saturados.
Manipulación de oráculos y vulnerabilidades de precios
Durante la cascada de octubre, se evidenció una decisión crítica en el diseño de los sistemas de margen: algunos exchanges calculaban el valor del colateral según los precios internos del mercado spot, en vez de alimentarse de oráculos externos. En condiciones normales, los arbitrajistas mantienen la alineación de precios entre mercados. Pero cuando la infraestructura está bajo presión, ese acoplamiento se desmorona.
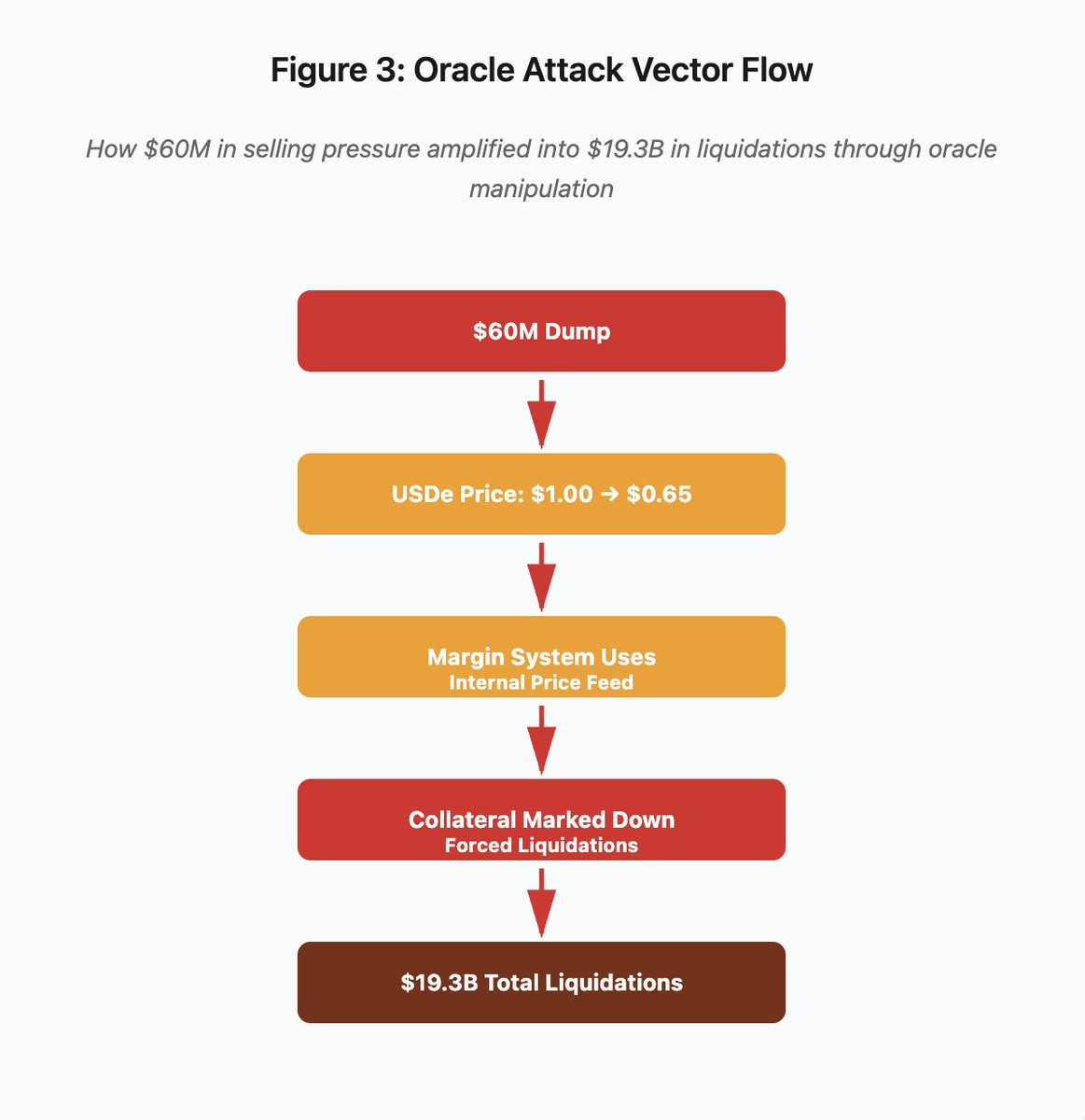
Figura 3: Diagrama de flujo de manipulación de oráculos
El gráfico interactivo muestra el vector de ataque en cinco etapas:
- Dump inicial: presión vendedora de 60 M$ en USDe
- Manipulación de precios: USDe cae de 1,00 $ a 0,65 $ en un solo exchange
- Fallo del oráculo: el sistema de margen usa un feed interno de precios corrupto
- Desencadenante de la cascada: el colateral se devalúa y comienzan las liquidaciones forzadas
- Amplificación: 19 300 M$ en liquidaciones totales (amplificación de 322x)
El ataque explotó el uso de precios spot por parte de Binance para colateral sintético envuelto. Cuando un atacante vendió 60 millones de USDe en libros de órdenes poco líquidos, el precio spot cayó de 1,00 $ a 0,65 $. El sistema de margen, configurado para valorar el colateral al precio spot, revalorizó a la baja todas las posiciones colateralizadas en USDe en un 35 %. Esto activó llamadas de margen y liquidaciones forzadas en miles de cuentas.
Las liquidaciones obligaron a vender aún más en un mercado ilíquido, lo que deprimió aún más los precios. El sistema de margen observó los nuevos precios bajos y volvió a devaluar más posiciones. El bucle de retroalimentación amplificó 60 millones en presión vendedora hasta 19 300 millones en liquidaciones forzadas.

Figura 4: Bucle de retroalimentación de la cascada de liquidación
El diagrama circular ilustra la naturaleza auto-reforzante de la cascada:
Caída de precio → activación de liquidaciones → ventas forzadas → nueva caída de precio → [el ciclo se repite]
Este mecanismo no habría funcionado con un sistema de oráculos bien diseñado. Si Binance hubiera utilizado precios medios ponderados por tiempo (TWAP) en varios exchanges, la manipulación momentánea no habría afectado la valoración del colateral. Si se hubieran empleado feeds agregados de Chainlink u otros oráculos multisource, el ataque habría fracasado.
El incidente de wBETH cuatro días antes demostró una vulnerabilidad similar. Wrapped Binance ETH (wBETH) debería mantener una relación de conversión 1:1 con ETH. Durante la cascada, la liquidez desapareció y el mercado spot wBETH/ETH reflejó un descuento del 20 %. El sistema de margen devaluó el colateral wBETH en consecuencia, provocando liquidaciones en posiciones que realmente estaban totalmente colateralizadas por el ETH subyacente.
Mecanismos de Auto-Deleveraging (ADL)
Cuando las liquidaciones no pueden ejecutarse al precio de mercado actual, los exchanges emplean Auto-Deleveraging para socializar las pérdidas entre los traders con posiciones rentables. El ADL cierra forzosamente posiciones rentables al precio vigente para cubrir el déficit de las posiciones liquidadas.
Durante la cascada de octubre, Binance ejecutó ADL en varios pares de trading. Traders con posiciones largas y rentables vieron sus operaciones cerradas de forma forzosa, no por fallos propios en la gestión del riesgo, sino porque otras posiciones ajenas se volvieron insolventes.
El ADL refleja una decisión arquitectónica fundamental en el trading de derivados centralizado. Los exchanges garantizan no perder dinero. Esto implica que las pérdidas deben ser absorbidas por:
- Fondos de seguro (capital reservado por el exchange para cubrir déficits de liquidación)
- ADL (forzando el cierre de posiciones rentables)
- Pérdida socializada (repartiendo las pérdidas entre todos los usuarios)
El tamaño del fondo de seguros respecto al interés abierto determina la frecuencia de ADL. El fondo de Binance sumaba unos 2 000 millones en octubre de 2025. Frente a 4 000 millones de interés abierto en futuros perpetuos BTC, ETH y BNB, esto supone una cobertura del 50 %. Pero durante la cascada de octubre, el interés abierto superó los 20 000 millones en todos los pares. El fondo de seguros no pudo cubrir el déficit.
Tras el evento de octubre, Binance anunció que garantizaría la ausencia de ADL en los contratos USDⓈ-M de BTC, ETH y BNB mientras el interés abierto total permanezca por debajo de 4 000 millones. Esto crea un incentivo: los exchanges pueden mantener fondos de seguro más grandes para evitar el ADL, pero esto inmoviliza capital que podría utilizarse de forma más rentable.
Fallos on-chain: limitaciones de los protocolos blockchain
El gráfico de barras compara el tiempo de inactividad en distintos incidentes:
- Solana (feb 2024): 5 horas - cuello de botella en el throughput de votaciones
- Polygon (mar 2024): 11 horas - desajuste de versiones entre validadores
- Optimism (jun 2024): 2,5 horas - sobrecarga del secuenciador (airdrop)
- Solana (sep 2024): 4,5 horas - ataque de spam de transacciones
- Arbitrum (dic 2024): 1,5 horas - fallo del proveedor RPC
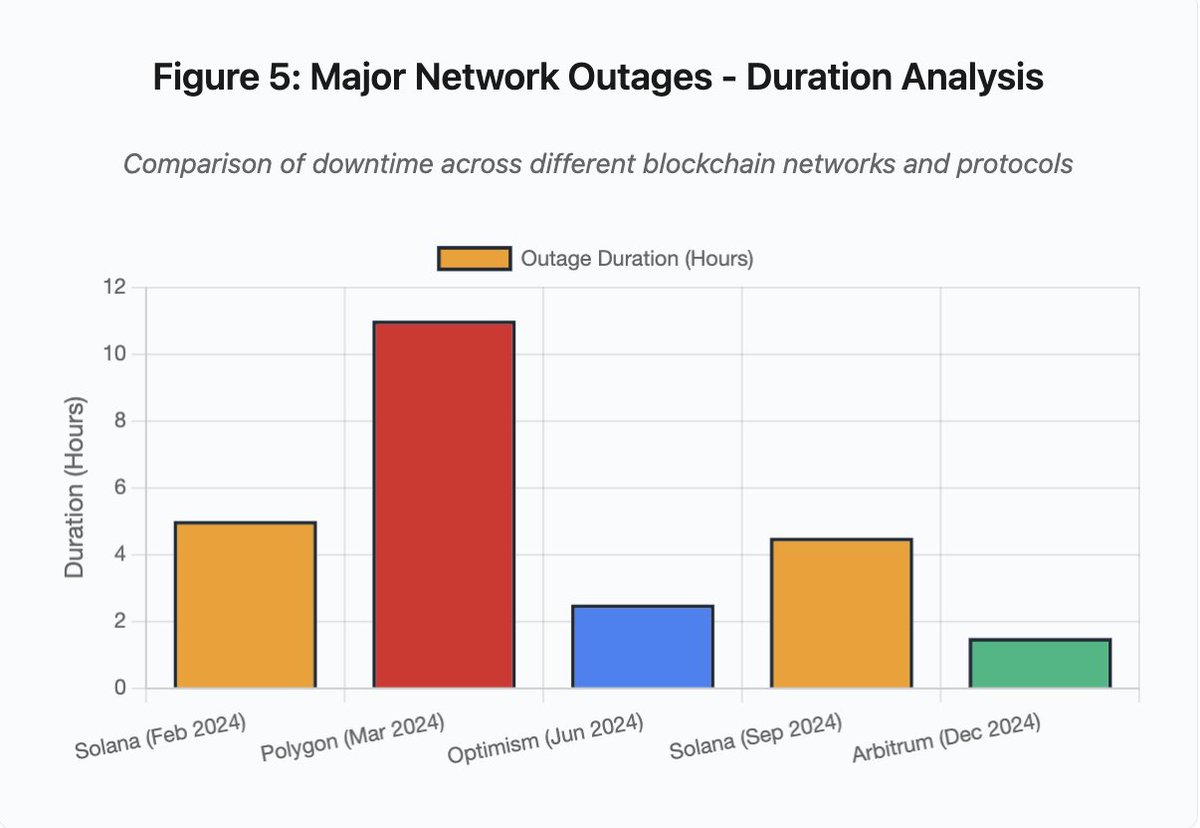
Figura 5: Principales interrupciones de red - análisis por duración
Solana: el cuello de botella del consenso
Solana sufrió varias caídas en 2024-2025. El corte de febrero de 2024 duró unas 5 horas. El de septiembre de 2024 se prolongó entre 4 y 5 horas. Estos cortes tienen causas similares: la incapacidad de la red para procesar el volumen de transacciones en ataques de spam o actividad extrema.
Detalle de la figura 5: Las interrupciones de Solana (5 horas en febrero, 4,5 horas en septiembre) ponen de manifiesto problemas recurrentes de resiliencia de la red bajo estrés.
La arquitectura de Solana optimiza para el throughput. En condiciones ideales, la red procesa entre 3 000 y 5 000 transacciones por segundo con finalización inferior a un segundo. Este rendimiento supera al de Ethereum por varios órdenes de magnitud. Pero en eventos de estrés, esta optimización genera vulnerabilidades.
El corte de septiembre de 2024 fue consecuencia de una avalancha de transacciones spam que saturó los mecanismos de votación de los validadores. Los validadores de Solana deben votar los bloques para lograr consenso. En operaciones normales, los validadores priorizan las transacciones de voto para que el consenso avance. Pero el protocolo trataba las transacciones de voto igual que las demás en el mercado de tasas.
Cuando el mempool se llenó con millones de spam, los validadores no lograban transmitir transacciones de voto. Sin votos suficientes, los bloques no se finalizaban. Sin bloques finalizados, la cadena se detenía. Las transacciones pendientes quedaban atascadas en el mempool y las nuevas fracasaban al enviarse.
StatusGator documentó varias interrupciones de Solana en 2024-2025 que la propia Solana nunca reconoció oficialmente. Esto genera asimetría informativa. Los usuarios no distinguen entre problemas locales de conectividad y fallos globales de red. Los servicios de monitorización externos aportan transparencia, pero las plataformas deberían mantener páginas de estado exhaustivas.
Ethereum: la explosión de tasas de gas
Ethereum experimentó picos extremos en las tasas de gas durante el boom DeFi de 2021. Las tasas de transacción superaron los 100 dólares para operaciones simples. Las interacciones complejas con smart contracts costaban entre 500 y 1 000 dólares. Estas tasas hacían la red inutilizable para operaciones pequeñas y habilitaban un nuevo vector de ataque: la extracción de MEV.
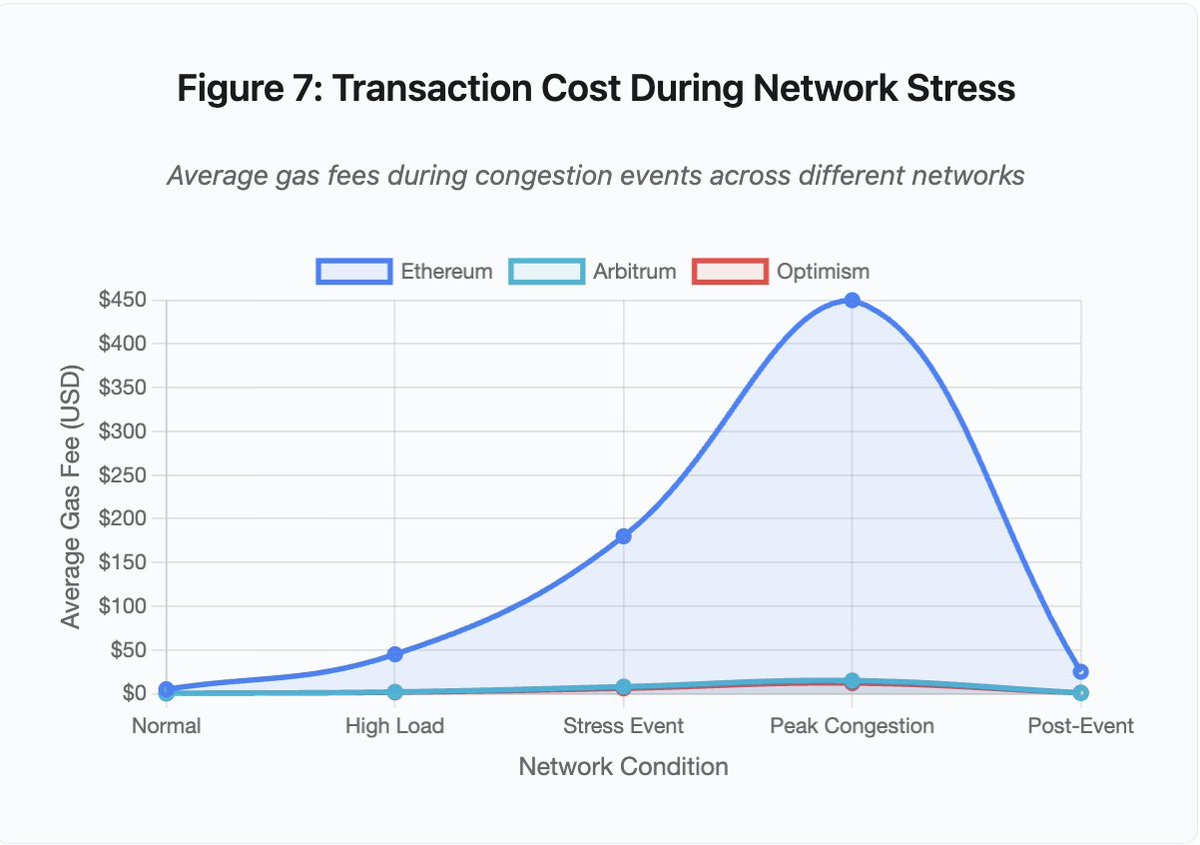
Figura 7: Coste de transacción durante estrés de red
Este gráfico de líneas muestra de forma contundente la escalada de tasas de gas en distintas redes durante eventos de estrés:
- Ethereum: 5 $ (normal) → 450 $ (máxima congestión) - incremento de 90x
- Arbitrum: 0,50 $ → 15 $ - incremento de 30x
- Optimism: 0,30 $ → 12 $ - incremento de 40x
La visualización muestra que incluso las soluciones de Capa 2 sufren aumentos significativos en las tasas, aunque parten de valores mucho menores.
Maximal Extractable Value (MEV) describe los beneficios que los validadores pueden extraer al reordenar, incluir o excluir transacciones. En entornos de tasas de gas elevadas, el MEV resulta especialmente lucrativo. Los arbitrajistas compiten por adelantarse a grandes operaciones en DEX. Los bots de liquidación compiten por liquidar primero posiciones subcolateralizadas. Esta competencia se traduce en guerras de pujas por la tasa de gas.
Los usuarios que quieren garantizar la inclusión de sus transacciones en momentos de congestión deben superar las pujas de los bots de MEV. Esto crea escenarios en los que la tasa de transacción supera el valor transferido. ¿Quieres reclamar tu airdrop de 100 dólares? Paga 150 dólares de gas. ¿Necesitas añadir colateral para evitar la liquidación? Compite con bots que pagan 500 dólares por prioridad.
El gas limit de Ethereum restringe el cómputo total por bloque. En congestión, los usuarios pujan por espacio de bloque escaso. El mercado de tasas funciona como está diseñado: las pujas más altas tienen prioridad. Pero este diseño encarece la red justo cuando más se necesita.
Las soluciones de Capa 2 intentaron resolver este problema moviendo el cómputo fuera de la cadena y heredando la seguridad de Ethereum mediante liquidaciones periódicas. Optimism, Arbitrum y otros acumuladores procesan miles de transacciones off-chain y luego envían pruebas comprimidas a Ethereum. Esta arquitectura reduce los costes por transacción en operaciones normales.
Capa 2: el cuello de botella del secuenciador
Pero las soluciones de Capa 2 introducen nuevos cuellos de botella. Optimism sufrió una caída cuando 250 000 direcciones reclamaron airdrops simultáneamente en junio de 2024. El secuenciador—el componente que ordena las transacciones antes de enviarlas a Ethereum—se saturó. Los usuarios no pudieron enviar transacciones durante varias horas.
Este corte reveló que mover el cómputo fuera de la cadena no elimina las exigencias de infraestructura. Los secuenciadores deben procesar transacciones entrantes, ordenarlas, ejecutarlas y generar pruebas de fraude o ZK para liquidación en Ethereum. Bajo tráfico extremo, los secuenciadores enfrentan los mismos retos de escalabilidad que las blockchains independientes.
Es necesario disponer de varios proveedores RPC. Si falla el principal, los usuarios deben poder conmutar automáticamente a alternativas. Durante la caída de Optimism, algunos proveedores RPC siguieron funcionando mientras otros fallaban. Los usuarios con wallets configuradas por defecto en proveedores caídos no podían interactuar con la cadena, aunque esta siguiera operativa.
Las interrupciones de AWS han evidenciado reiteradamente el riesgo de concentración de infraestructura en el ecosistema cripto:
- 20 de octubre de 2025 (hoy): corte en la región US-EAST-1 que afecta a Coinbase, Venmo, Robinhood y Chime. AWS reconoce mayor tasa de errores en DynamoDB y EC2.
- Abril de 2025: corte regional que afecta a Binance, KuCoin y MEXC simultáneamente. Varias exchanges importantes quedaron inaccesibles cuando fallaron sus componentes alojados en AWS.
- Diciembre de 2021: el corte en US-EAST-1 derribó Coinbase, Binance.US y el exchange «descentralizado» dYdX durante 8-9 horas, afectando incluso a almacenes de Amazon y servicios de streaming.
- Marzo de 2017: el corte de S3 impidió el acceso a Coinbase y GDAX durante cinco horas, con una interrupción generalizada de Internet.
El patrón es claro: estos exchanges alojan componentes críticos en AWS. Cuando AWS sufre cortes regionales, múltiples exchanges y servicios importantes quedan inaccesibles al mismo tiempo. Los usuarios no pueden acceder a fondos, ejecutar operaciones ni modificar posiciones durante las interrupciones—precisamente cuando la volatilidad exige acciones inmediatas.
Polygon: el desajuste de versiones en el consenso
Polygon (antes Matic) sufrió una interrupción de 11 horas en marzo de 2024. El origen fue un desajuste de versiones entre validadores. Algunos ejecutaban versiones antiguas del software mientras otros ya lo habían actualizado. Estas versiones calculaban las transiciones de estado de forma diferente.
Detalle de la figura 5: El corte de Polygon (11 horas) fue el más largo de los incidentes analizados, lo que pone de relieve la gravedad de los fallos de consenso.
Cuando los validadores llegaron a conclusiones diferentes sobre el estado correcto, el consenso falló. La cadena dejó de producir bloques porque los validadores no se ponían de acuerdo sobre su validez. Esto generó un bloqueo: los validadores con software antiguo rechazaban los bloques de los actualizados y viceversa.
La resolución exigió actualizar coordinadamente los validadores. Pero coordinar actualizaciones durante una interrupción lleva tiempo. Cada operador debe ser contactado, instalar la versión correcta y reiniciar su validador. En una red descentralizada con cientos de validadores independientes, la coordinación puede llevar horas o días.
Los hard forks suelen emplear triggers por altura de bloque. Todos los validadores actualizan para un bloque concreto, garantizando la activación simultánea. Pero esto exige coordinación previa. Las actualizaciones incrementales, en las que los validadores adoptan nuevas versiones gradualmente, pueden causar precisamente el desajuste que provocó el corte de Polygon.
Compromisos arquitectónicos
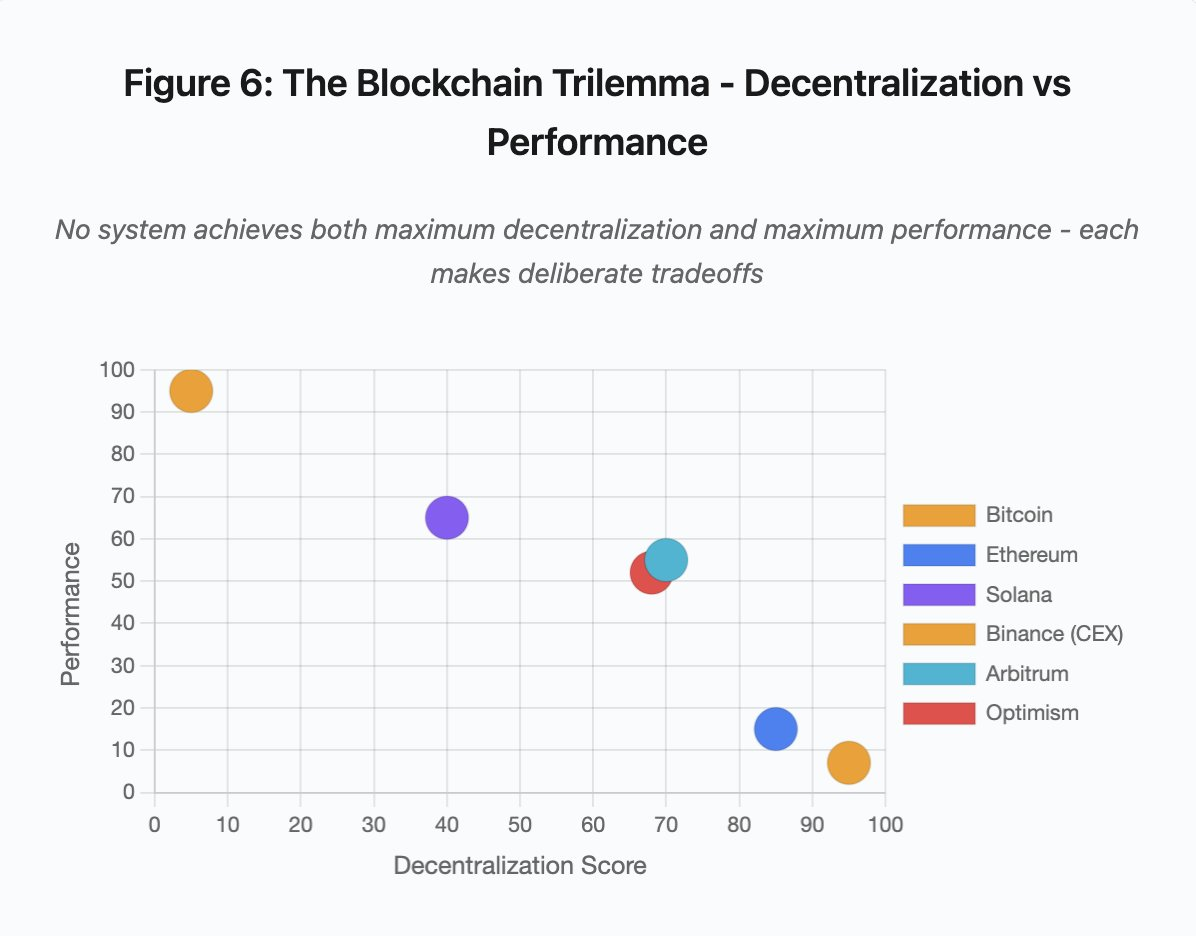
Figura 6: El trilema de blockchain - descentralización frente a rendimiento
Esta visualización sitúa distintos sistemas según dos dimensiones clave:
- Bitcoin: alta descentralización, bajo rendimiento
- Ethereum: alta descentralización, rendimiento moderado
- Solana: descentralización media, rendimiento alto
- Binance (CEX): mínima descentralización, rendimiento máximo
- Arbitrum/Optimism: descentralización media-alta, rendimiento medio
Conclusión clave: ningún sistema alcanza simultáneamente la máxima descentralización y el máximo rendimiento. Cada diseño implica compromisos para distintos usos.
Los exchanges centralizados logran baja latencia gracias a la simplicidad arquitectónica. Los motores de emparejamiento procesan órdenes en microsegundos. El estado reside en bases de datos centrales. No hay protocolos de consenso que añadan sobrecarga. Pero esta simplicidad crea puntos únicos de fallo. Cuando la infraestructura se estresa, los fallos en cascada se propagan por sistemas fuertemente acoplados.
Los protocolos descentralizados distribuyen el estado entre validadores, eliminando puntos únicos de fallo. Las redes de alto throughput mantienen esta propiedad durante caídas (no se pierden fondos, solo se compromete temporalmente la liveness). Sin embargo, lograr consenso entre validadores distribuidos añade sobrecarga computacional. Los validadores deben acordar antes de finalizar las transiciones de estado. Si ejecutan versiones incompatibles o soportan tráfico excesivo, los procesos de consenso pueden detenerse temporalmente.
Añadir réplicas mejora la tolerancia a fallos, pero incrementa los costes de coordinación. Cada validador adicional en un sistema tolerante a fallos bizantinos añade sobrecarga de comunicación. Las arquitecturas de alto rendimiento minimizan este coste mediante optimización en la comunicación entre validadores, permitiendo rendimiento superior pero generando vulnerabilidad ante ciertos patrones de ataque. Las arquitecturas centradas en la seguridad priorizan la diversidad de validadores y la robustez del consenso, limitando el throughput base mientras maximizan la resiliencia.
Las soluciones de Capa 2 buscan combinar ambas propiedades mediante un diseño jerárquico. Heredan la seguridad de Ethereum por liquidación en L1 y ofrecen throughput alto mediante cómputo off-chain. Sin embargo, introducen nuevos cuellos de botella en secuenciadores y capas RPC, demostrando que la complejidad arquitectónica genera nuevos modos de fallo incluso cuando resuelve otros.
La escalabilidad sigue siendo el problema fundamental
Estos incidentes muestran un patrón recurrente: los sistemas se dimensionan para la carga normal y luego fallan catastróficamente bajo estrés. Solana gestionó bien el tráfico rutinario pero colapsó cuando el volumen de transacciones aumentó un 10 000 %. Las tasas de gas de Ethereum se mantuvieron razonables hasta que la adopción DeFi desencadenó congestión. La infraestructura de Optimism funcionó hasta que 250 000 direcciones reclamaron airdrops simultáneos. Las APIs de Binance operaron normalmente pero se saturaron durante cascadas de liquidaciones.
El evento de octubre de 2025 evidenció esta dinámica a nivel exchange. En condiciones normales, los límites de velocidad y conexiones de base de datos de la API de Binance resultan suficientes. Bajo cascadas de liquidaciones, cuando cada trader intenta ajustar posiciones simultáneamente, esos límites se convierten en cuellos de botella. El sistema de margen, diseñado para proteger al exchange mediante liquidaciones forzadas, agravó la crisis al generar vendedores forzosos en el peor momento.
El escalado automático resulta insuficiente frente a incrementos bruscos de la carga. Poner en marcha servidores adicionales lleva minutos. Durante ese tiempo, los sistemas de margen valoran posiciones en base a precios corruptos de libros de órdenes poco líquidos. Cuando la nueva capacidad está disponible, la cascada ya se ha propagado.
Sobredimensionar para eventos raros de estrés cuesta dinero en operaciones normales. Los operadores de exchanges optimizan para la carga habitual y asumen fallos ocasionales como racionalidad económica. Los costes del downtime se trasladan a los usuarios, que sufren liquidaciones, transacciones atascadas o imposibilidad de acceder a fondos en momentos críticos de mercado.
Mejoras de infraestructura
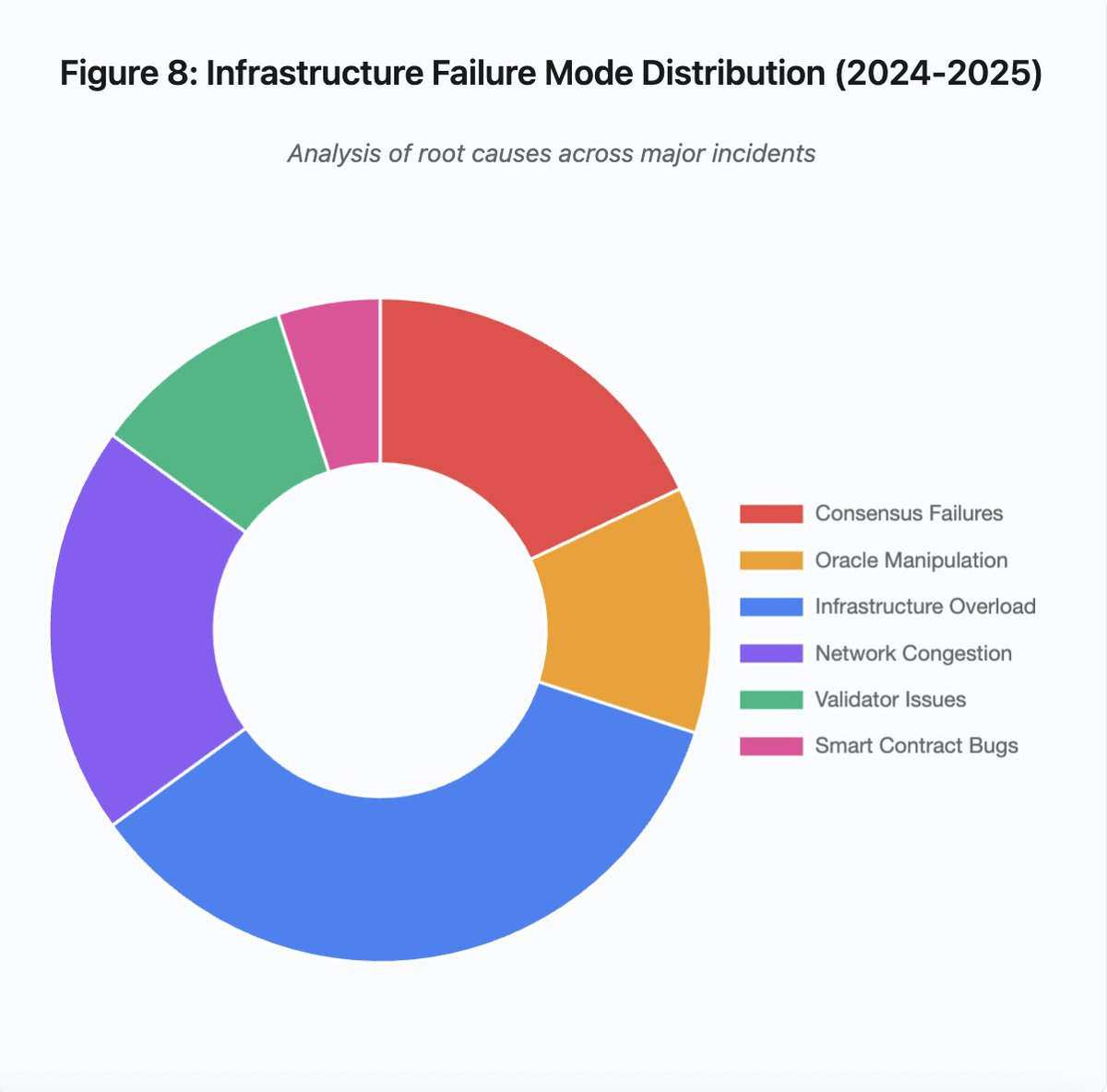
Figura 8: Distribución de modos de fallo de infraestructura (2024-2025)
El gráfico de sectores sobre las causas raíz revela:
- Sobrecarga de infraestructura: 35 % (la más frecuente)
- Congestión de red: 20 %
- Fallos de consenso: 18 %
- Manipulación de oráculos: 12 %
- Problemas de validadores: 10 %
- Errores en smart contracts: 5 %
Varias modificaciones arquitectónicas podrían reducir la frecuencia y gravedad de los fallos, aunque todas implican compromisos:
1. Separación de sistemas de precios y liquidación
El problema de octubre provino en parte de vincular los cálculos de margen a los precios spot. Usar ratios de conversión para activos envueltos en vez de precios spot habría evitado la mala valoración de wBETH. En general, los sistemas críticos de gestión de riesgo no deben depender de datos de mercado manipulables. Sistemas de oráculo independientes con agregación multisource y cálculos TWAP ofrecen fuentes de precios más robustas.
2. Sobredimensionamiento e infraestructura redundante
La interrupción de AWS de abril de 2025 que afectó a Binance, KuCoin y MEXC demostró los riesgos de dependencia concentrada en infraestructura. Ejecutar componentes críticos en varios proveedores de la nube aumenta la complejidad y el coste operativos, pero elimina fallos correlacionados. Las redes de Capa 2 pueden mantener varios proveedores RPC con conmutación automática. El gasto adicional parece innecesario en operaciones normales, pero evita caídas de horas durante picos de demanda.
3. Mejora de pruebas de estrés y planificación de capacidad
El patrón de sistemas que funcionan bien hasta que fallan sugiere pruebas insuficientes bajo estrés. Simular cargas de 100x la normal debería ser práctica habitual. Identificar cuellos de botella en desarrollo cuesta menos que descubrirlos en cortes reales. Sin embargo, las pruebas realistas son complejas. El tráfico en producción tiene patrones difíciles de replicar. Los usuarios se comportan distinto en caídas reales que en test.
El camino a seguir
El sobredimensionamiento es la solución más fiable, pero entra en conflicto con los incentivos económicos. Mantener una capacidad 10x para eventos raros cuesta dinero cada día para evitar problemas que ocurren una vez al año. Hasta que los fallos catastróficos generen costes suficientes para justificar el sobredimensionamiento, los sistemas seguirán fallando bajo presión.
La presión regulatoria podría forzar cambios. Si se exige por ley un uptime del 99,9 % o se limita el downtime tolerable, los exchanges tendrán que sobredimensionar. Pero la regulación suele llegar tras el desastre, no antes. El colapso de Mt. Gox en 2014 llevó a Japón a regular formalmente los exchanges de criptomonedas. Es probable que la cascada de octubre de 2025 propicie respuestas regulatorias similares. Queda por ver si esas respuestas fijarán resultados (máximo downtime permitido, máximo slippage en liquidaciones) o implementaciones (oráculos concretos, thresholds de circuit breakers).
El reto fundamental es que estos sistemas operan de forma continua en mercados globales, pero dependen de infraestructuras pensadas para horarios comerciales tradicionales. Cuando el estrés se produce a las 2:00, los equipos se apresuran a desplegar correcciones mientras los usuarios sufren pérdidas crecientes. Los mercados tradicionales paran la negociación durante crisis; los cripto simplemente colapsan. Que esto sea una virtud o un defecto depende de la perspectiva y posición de cada uno.
Los sistemas blockchain han alcanzado una sofisticación técnica extraordinaria en poco tiempo. Mantener consenso distribuido entre miles de nodos es un logro de ingeniería. Pero lograr fiabilidad bajo presión exige pasar de arquitecturas prototipo a infraestructuras de grado industrial. Esa transición cuesta dinero y requiere priorizar la robustez frente a la velocidad de desarrollo.
El desafío está en priorizar la robustez sobre el crecimiento en mercados alcistas, cuando todos ganan dinero y el downtime parece problema de otros. Cuando la próxima crisis someta el sistema a pruebas de estrés, emergerán nuevas debilidades. Si el sector aprende de octubre de 2025 o repite patrones similares sigue siendo una incógnita. La historia sugiere que descubriremos la próxima vulnerabilidad crítica tras otro fallo multimillonario bajo presión.
Análisis basado en datos públicos de mercado y declaraciones de plataformas. Las opiniones expresadas son únicamente mías, informadas pero no representan a ninguna entidad.
Aviso legal:
- Este artículo se ha republicado desde [yq_acc]. Todos los derechos de autor pertenecen al autor original [yq_acc]. Si tienes alguna objeción a esta republicación, contacta con el equipo de Gate Learn para que lo gestionen con prontitud.
- Descargo de responsabilidad: Las opiniones y puntos de vista expresados en este artículo corresponden únicamente al autor y no constituyen asesoramiento de inversión.
- Las traducciones del artículo a otros idiomas las realiza el equipo de Gate Learn. Salvo indicación expresa, queda prohibida la copia, distribución o plagio de los artículos traducidos.









