
Autor: Phosphen
Compilación; Gans Gans, Observador del mercado de predicciones Bagel
Este hombre ha recopilado datos de todos los partidos profesionales de tenis de los últimos 43 años, los ha introducido en un modelo de aprendizaje automático y solo hizo una pregunta: ¿puedes predecir quién ganará?
El modelo solo respondió una palabra: sí.
Luego, en este año en el Abierto de Australia, predijo correctamente 99 de 116 partidos, con una precisión del 85%!
Son partidos que el modelo nunca había visto durante su entrenamiento, y aún así predijo el ganador final en cada uno de ellos.

Todo esto con una sola laptop, datos gratuitos y código de código abierto, creado por @theGreenCoding.
A continuación, desglosaré completamente este proyecto que convierte el talento en oro, desde los datos originales hasta el éxito en las predicciones finales. Será uno de los casos más impresionantes de IA + predicción que hayas visto.
Punto de partida: una carpeta con datos de tenis de 43 años
La historia comienza con un conjunto de datos que podría considerarse el “Santo Grial de los datos deportivos”.
Este conjunto cubre todos los registros de partidos profesionales de la ATP (Asociación de Tenis Profesional) desde 1985 hasta 2024.
Puntos de quiebre, dobles faltas, golpes de derecha, golpes de revés, altura de los jugadores, edad, clasificación, historial de enfrentamientos, tipo de cancha… Cada estadística detallada que la ATP ha registrado a lo largo de los años.
Cuatro décadas de archivos CSV, todos en una sola carpeta.
Cuando abrió el conjunto completo de datos, su computadora se bloqueó.
Pero no se rindió. Para los 95,491 partidos en los datos, calculó muchas características derivadas adicionales:
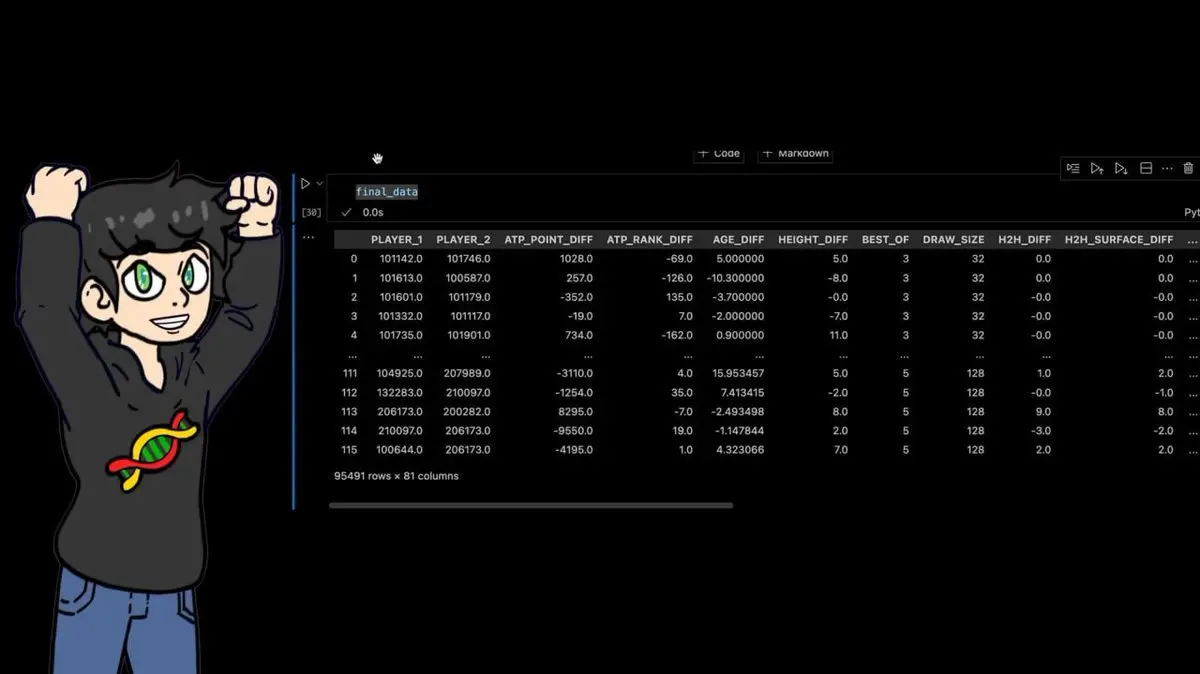
- Historial de enfrentamientos entre los dos jugadores
- Diferencia de edad y altura
- Tasa de victorias en las últimas 10, 25, 50 y 100 partidas
- Diferencia en la tasa de puntos ganados con primer saque
- Diferencia en la tasa de salvación en puntos de quiebre
- Un sistema de puntuación ELO personalizado, inspirado en el ajedrez (punto clave)
El conjunto final: 95,491 filas por 81 columnas.
Cada partido profesional de los últimos 40 años, con decenas de características calculadas manualmente.
Segundo paso: un algoritmo inspirado en Titanic

Antes de introducir los datos en un clasificador, decidió entender a fondo cómo funciona el algoritmo. Para ello, escribió desde cero un árbol de decisión usando numpy.
El árbol de decisión funciona como un juego de lógica: mediante una serie de preguntas, va acercándose a la respuesta.
Para ilustrar este concepto, eligió un conjunto de datos completamente diferente: Titanic.
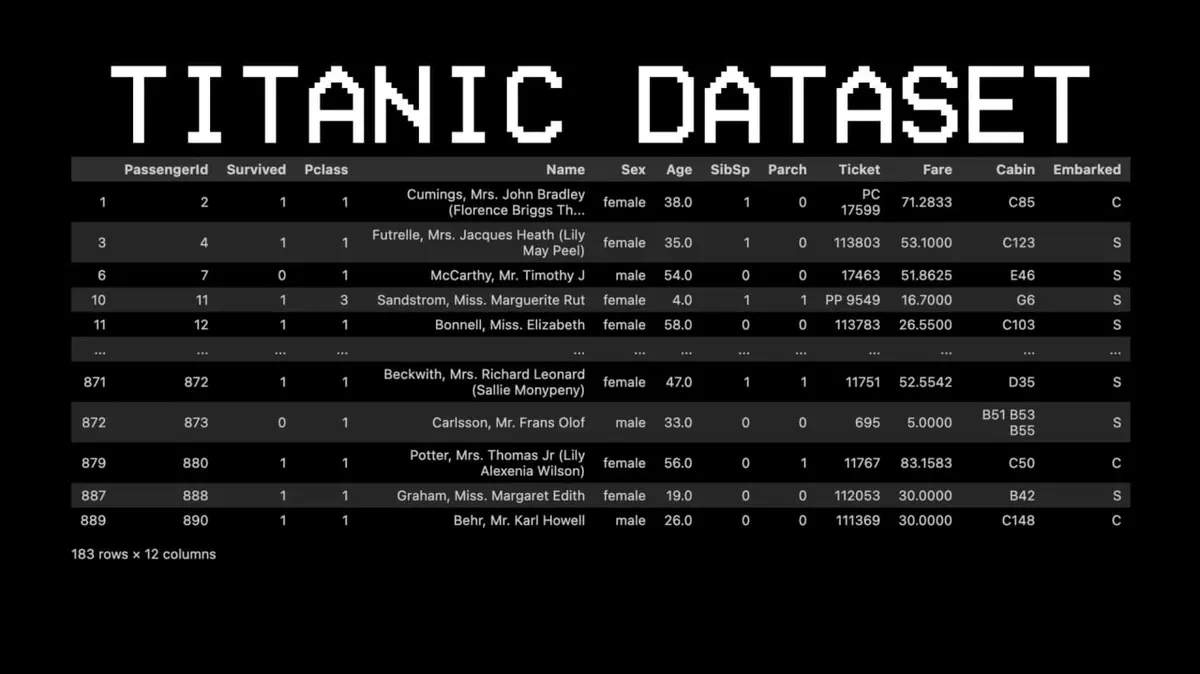
Por ejemplo: ¿Sobrevivió el pasajero número 11?
- Pregunta 1: ¿Estaba en primera clase? → Sí.
- Pregunta 2: ¿Era mujer? → Sí.
- Predicción: sobrevivió.
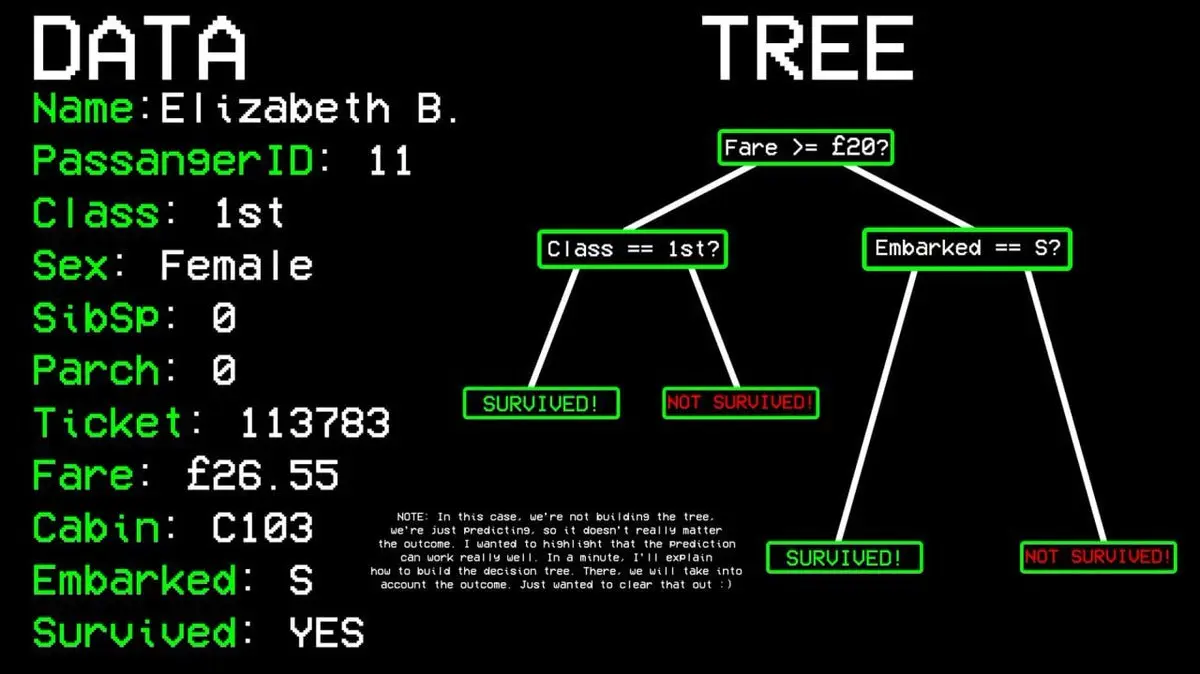
¿Cómo decide el algoritmo qué preguntas hacer?
Comienza analizando todos los datos y busca la variable que mejor diferencia entre “sobrevivió” y “no sobrevivió”. En Titanic, esa variable es la clase del pasajero. Los de primera clase van a un lado, los demás a otro.
Pero incluso en primera clase hay algunos que no sobrevivieron, lo que genera “impureza”. El algoritmo continúa buscando el mejor punto de división en otra variable: el género. Todas las mujeres en primera clase sobrevivieron, formando un “nodo puro”, y el árbol se detiene allí.
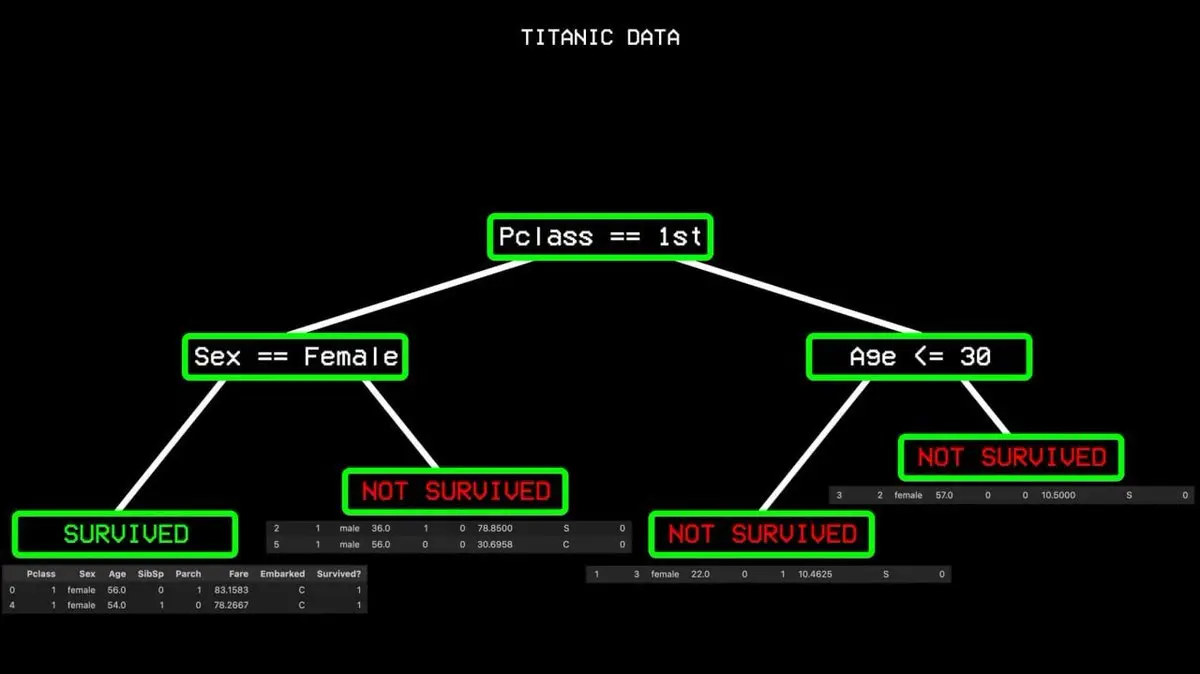
Este proceso se repite continuamente hasta construir un árbol de decisión completo que cubre todas las situaciones.
Su versión escrita en numpy funciona bien con conjuntos de datos pequeños, pero al aplicarla a los 95,000 partidos de tenis, la velocidad se vuelve insoportablemente lenta. Por eso, en la fase de entrenamiento, cambió a la versión optimizada de sklearn, que funciona con la misma lógica pero mucho más rápido.
Tercer paso: encontrar las variables clave que determinan el resultado
Antes de entrenar el modelo, trazó todas las variables en una enorme matriz de gráficos de dispersión (pairplot de seaborn), buscando patrones que puedan distinguir a los ganadores de los perdedores.

La mayoría de las características son ruido. La ID del jugador claramente no sirve. La diferencia en la tasa de victorias muestra algunos patrones, pero no es lo suficientemente clara para una clasificación confiable.
Solo una variable destaca por encima de las demás: la diferencia en puntuación ELO (ELO_DIFF).
El gráfico de dispersión de ELO_DIFF y ELO_SURFACE_DIFF muestra claramente la separación entre las dos clases, mientras que cualquier otra característica no se acerca a esa claridad.
Este hallazgo llevó a construir la parte más crucial del proyecto.
Cuarto paso: incorporar el sistema de puntuación ELO, inspirado en el ajedrez
ELO es un método para evaluar el nivel técnico de los jugadores, originalmente desarrollado para el ajedrez. Actualmente, Magnus Carlsen, número uno mundial, tiene una puntuación de 2833.

Decidió aplicar este sistema al tenis:
- Cada jugador empieza con 1500 puntos.
- Ganar un partido aumenta la puntuación; perderla la reduce.
El mecanismo central: la cantidad de puntos ganados o perdidos depende de la diferencia de puntuación con el oponente. Vencer a un oponente con puntuación más alta otorga más puntos, perder contra uno con puntuación más baja implica una penalización mayor.
Ilustró esto con la final de Wimbledon 2023: Carlos Alcaraz (2063) contra Novak Djokovic (2120). Alcaraz ganó en una remontada.

Calculando con la fórmula: Alcaraz +14 puntos, Djokovic -14 puntos.
Aunque la fórmula es sencilla, su poder en datos históricos de 43 años es sorprendente.
Quinto paso: visualización del dominio de los “Tres Grandes”
Trazó la puntuación ELO de Federer a lo largo de toda su carrera, desde su debut hasta su retiro, registrando cada partido.
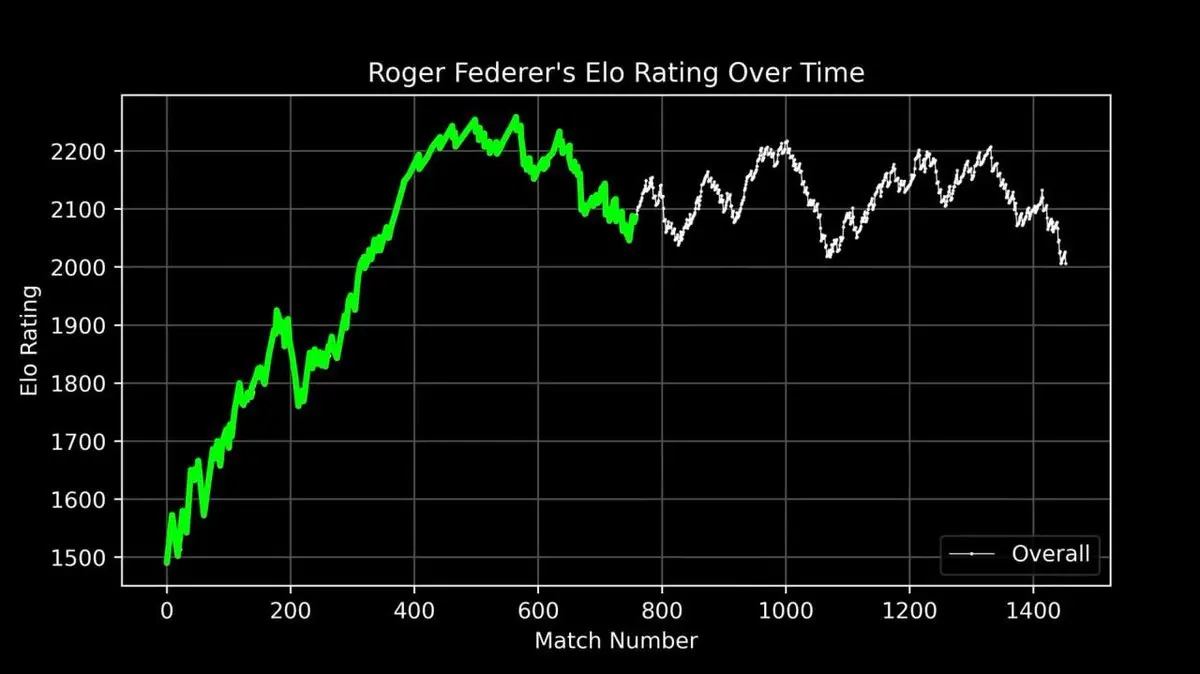
Esta curva muestra toda una leyenda: el ascenso rápido en los primeros años, el dominio absoluto en su pico (alrededor del partido 400), y las fluctuaciones en la fase final de su carrera.
Pero lo más impactante fue poner en la misma gráfica a Federer y a todos los jugadores de la ATP desde 1985:
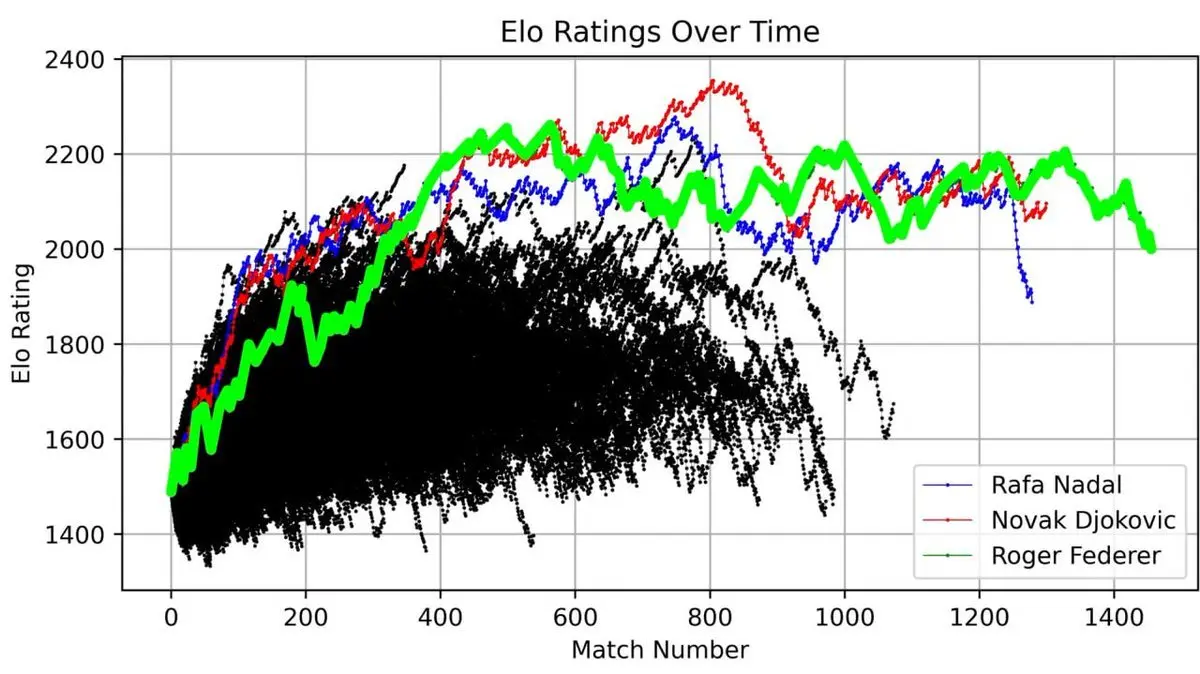
Las tres líneas se elevan por encima de todos los demás: Federer (verde), Nadal (azul) y Djokovic (rojo).
Los “Tres Grandes” no son solo un título; al visualizar 40 años de datos, su dominio se vuelve matemáticamente evidente.
Según su sistema ELO personalizado, el actual número uno mundial es Jannik Sinner con 2176 puntos, seguido por Djokovic con 2096 y Alcaraz con 2003.

Recuerda que Sinner está en primer lugar, esto será clave más adelante.
Sexto paso: el campo como variable que lo cambia todo
El tipo de superficie en el tenis puede cambiar radicalmente el juego:
- Arcilla: lento, rebote alto
- Césped: rápido, rebote bajo
- Hard court: intermedio
Un jugador que domina en una superficie puede fracasar completamente en otra.
Por eso, construyó puntuaciones ELO separadas para cada tipo de superficie: arcilla, césped y pista dura.
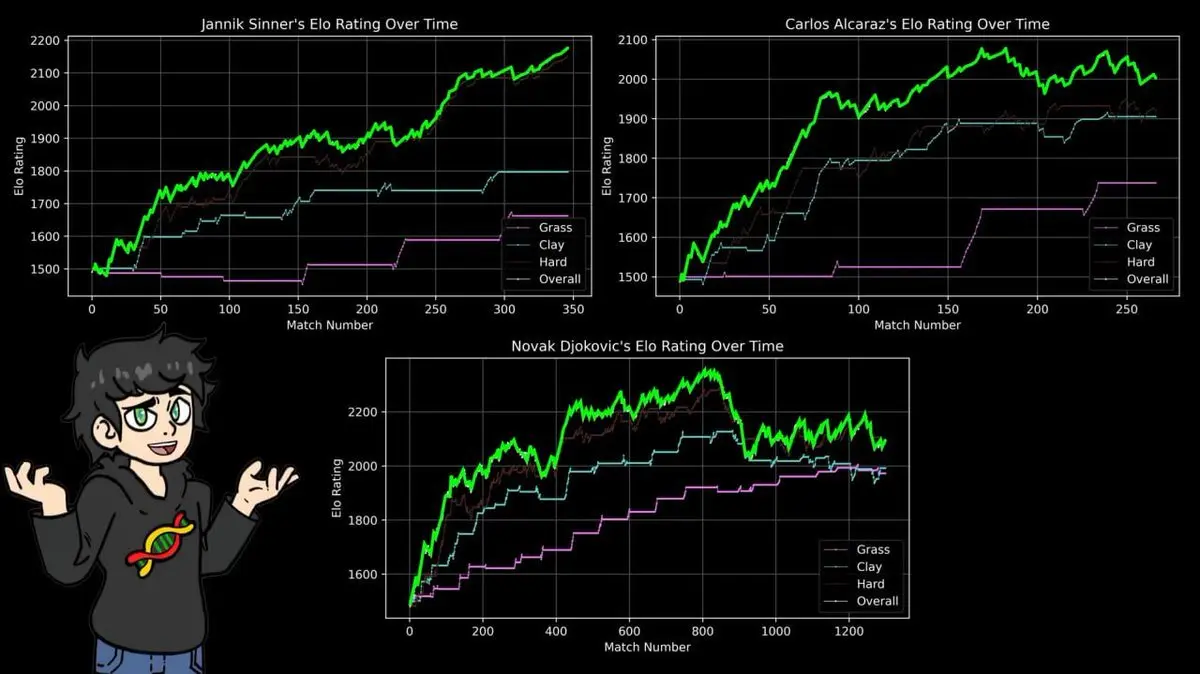
Los resultados confirmaron lo que todos los aficionados saben: la puntuación máxima de Nadal en arcilla supera la de Federer en césped, la de Djokovic en pista dura, y la de cualquier jugador en cualquier superficie en la historia.
Ganador de 14 Roland Garros, con 112 victorias y 4 derrotas en ese torneo.
La fórmula ELO no se preocupa por la narrativa ni por la fama; solo registra resultados. Y sus conclusiones coinciden exactamente con los reportes deportivos de los últimos 40 años.
Séptimo paso: enfrentando el techo
Con los datos listos y el sistema ELO en marcha, empezó a entrenar clasificadores. Este proceso muestra claramente la importancia de la elección del algoritmo.
Árbol de decisión: precisión del 74%
Un solo árbol de decisión en todo el conjunto de datos alcanza un 74% de precisión. Suena bien, hasta que descubres que solo usando la diferencia en ELO para predecir, ya alcanza un 72%.
El árbol, basado en su sistema de puntuación manual, apenas aporta mejoras.
Bosques aleatorios: precisión del 76%
El problema del árbol único es su “alta varianza”: es muy sensible a los datos específicos con los que se entrena. La solución estándar es el Random Forest: construir decenas o incluso cientos de árboles, cada uno entrenado con diferentes subconjuntos aleatorios de datos y características, y luego votar por mayoría.

94 árboles diferentes votan en cada partido.

El resultado: 76%. Mejoró, pero alcanzó un techo. Sin importar cómo ajuste los hiperparámetros, rediseñe las características o manipule los datos, la precisión no pasa del 77%.
Octavo paso: romper ese techo
Luego probó XGBoost, que llama “la versión esteroide del Random Forest”.
La diferencia clave: mientras el Random Forest construye árboles en paralelo y promedia, XGBoost construye en serie, cada árbol corrigiendo los errores de los anteriores. Incluye regularización para evitar sobreajuste y mantiene cada árbol pequeño para no memorizar los datos.
El resultado: 85% de precisión.
Frente al techo del 76% del Random Forest, esto es un avance enorme. Con los mismos datos, las mismas características, solo cambió el algoritmo.
XGBoost también identifica las tres características más importantes: diferencia en ELO, diferencia en ELO específica de superficie, y el ELO general. Este sistema de puntuación, inspirado en el ajedrez, resulta ser el predictor más fuerte entre las 81 características.
En comparación, entrenó una red neuronal con los mismos datos y alcanzó un 83%. Aunque buena, todavía queda por detrás de XGBoost. En este conjunto de datos, los métodos basados en árboles ganan.
Noveno paso: la batalla final — Abierto de Australia 2025
Todo lo anterior se entrenó con datos hasta diciembre de 2024.
El Abierto de Australia de enero de 2025 no estaba en los datos de entrenamiento, por lo que se convirtió en un escenario perfecto: ¿el modelo realmente comprende las reglas del tenis o solo memoriza patrones históricos?

Ingresó el cuadro completo del torneo en el modelo y le pidió que predijera cada partido.
El resultado: de 116 partidos, predijo correctamente 99, con solo 17 errores. Precisión del 85.3%.
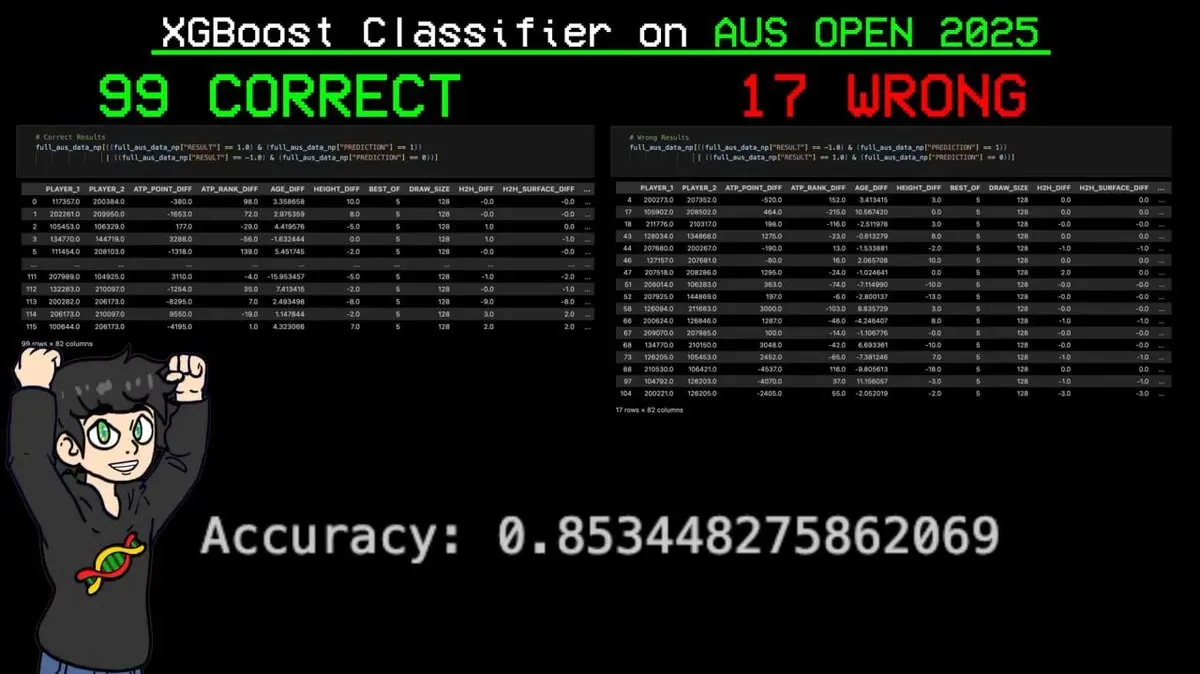
La predicción más importante: predijo con precisión cada victoria de Sinner (el jugador clasificado número uno en el sistema ELO global) durante todo el torneo.
Antes de que la pelota tocara la cancha, la IA ya había predicho al campeón de Grand Slam.
Conclusión
Una persona, una laptop, sin datos exclusivos, sin infraestructura costosa, sin un equipo de investigación — logró construir un modelo de predicción de tenis profesional con una precisión del 85%, y predijo al campeón antes de que comenzara el torneo.
Los datos de tenis están en GitHub, completamente reproducible.
Crear milagros nunca había estado tan al alcance.
La verdadera diferencia no está en los recursos, sino en si estás dispuesto a hacerlo.
