AI herramientas CanIRun.ai puede detectar automáticamente las especificaciones de hardware del usuario a través del navegador, estimando qué modelos LLM y velocidades de inferencia se pueden ejecutar. Los usuarios interesados pueden probarlo y conocerlo.
(Resumen previo: Clawdbot, un asistente AI 24/7 que hizo que Mac mini se agotara)
(Información adicional: No sigas ciegamente a OpenClaw, el AI de cangrejo es potente, pero no necesariamente adecuado para ti)
Índice del artículo
Toggle
- Pequeñas desventajas de Canirun.ai
- Alternativa en línea de línea de comandos: llmfit
- Lo que más desea la comunidad
¿Quieres instalar un modelo de lenguaje grande (LLM) en tu equipo? La primera duda común para los principiantes es: ¿Qué modelos puedo correr en mi computadora? Este artículo presenta una herramienta que ha generado discusión en la comunidad de Hacker News: CanIRun.ai.
CanIRun.ai es una herramienta web sencilla: solo abre el navegador y automáticamente detecta tu GPU y memoria usando la API WebGPU, luego, según la cantidad de parámetros, nivel de cuantización (Q4_K_M, Q8_0, F16, etc.) y ancho de banda de memoria, estima la viabilidad y velocidad de inferencia (tokens/segundo) de cada modelo, mostrando los resultados con una calificación de S a F.
Cubre desde modelos ultraligeros de 0.8B parámetros hasta modelos gigantes MoE (Mixture of Experts, arquitectura de expertos mezclados) de 1T parámetros, con datos provenientes de herramientas de inferencia local como llama.cpp, Ollama y LM Studio.
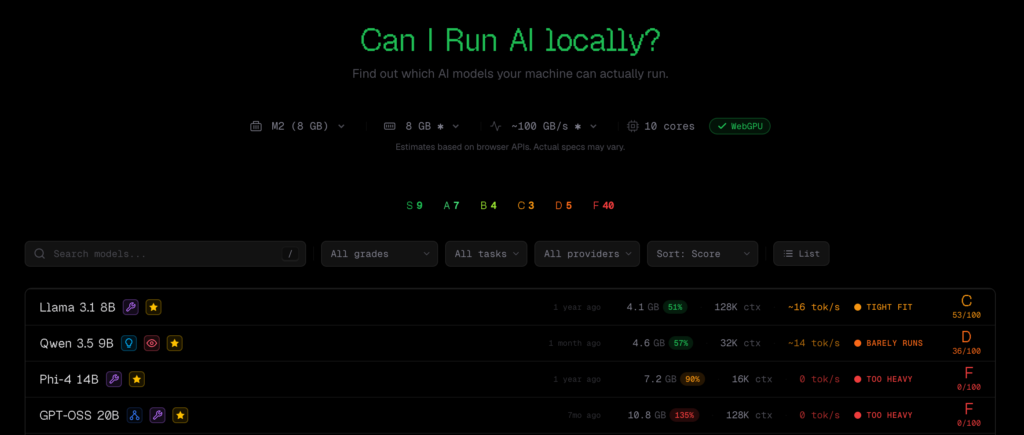
Pequeñas desventajas de Canirun.ai
Aunque la idea de la herramienta ha sido bien recibida, también hay críticas. Principalmente, en dos aspectos: cobertura de hardware incompleta y discrepancias entre estimaciones y resultados reales.
La falta de algunos modelos de hardware es un problema frecuente. No aparecen en la lista tarjetas como RTX Pro 6000, RTX 5060 Ti 16GB, ni GPUs portátiles de varias marcas. En cuanto a chips de Apple, aunque están listados, solo hasta 192GB de memoria, mientras que el M3 Ultra soporta hasta 512GB.
El problema de discrepancias en las estimaciones surge cuando algunos usuarios prueban y obtienen resultados diferentes a los que CanIRun.ai predice. Casos en los que la web dice que no se puede correr un modelo, pero en realidad sí se puede, se repiten en los foros, haciendo que algunos usuarios dejen de confiar en los resultados.
Aunque hay margen para mejorar la web, para un principiante es útil para verificar rápidamente su equipo.
Alternativa en línea de línea de comandos: llmfit
Al mismo tiempo, algunos en la comunidad recomiendan una herramienta llamada llmfit: un programa de línea de comandos que puede acceder directamente a herramientas del sistema (como nvidia-smi) para obtener información precisa de la GPU, sin depender de la API del navegador. Muchos consideran que es más práctico y preciso que la versión web.
Sin embargo, llmfit también genera un debate: algunos usuarios se sorprenden de que pueda identificar con precisión el modelo de GPU sin solicitar permisos explícitos. Esto ha puesto en alerta a la comunidad sobre la privacidad y el fingerprinting del hardware en los navegadores: si una web puede detectar tu tarjeta gráfica mediante WebGPU, ¿cómo se usa esa información?
Un usuario sugiere que la mejor opción sería integrar esa funcionalidad en Ollama, permitiendo a los usuarios, desde la línea de comandos, filtrar automáticamente los modelos compatibles según su hardware, evitando búsquedas manuales.
Lo que más desea la comunidad
Según el feedback, la principal limitación de CanIRun.ai no es solo la precisión de la estimación, sino que su evaluación es demasiado unidimensional. La verdadera pregunta de los usuarios es: ¿Cuál es el mejor modelo en calidad y velocidad en mi hardware? Actualmente, la herramienta solo responde si se puede correr o no, pero no si funciona con suficiente calidad.
La comunidad espera que en el futuro se añadan puntuaciones de rendimiento del modelo, combinadas con la estimación del hardware, para ofrecer una decisión más completa. Otras mejoras técnicas incluyen: incorporar estrategias de compartición de memoria CPU (para que GPUs con poca memoria puedan usar memoria del sistema), soporte para técnicas de descarga de KV cache, y correcciones en la lógica de cálculo de modelos MoE.
En resumen, la dirección de la herramienta es correcta y existe demanda en el mercado: la barrera para usar AI local sigue siendo alta para usuarios comunes. Poder rápidamente determinar “qué puede correr mi máquina” es una necesidad urgente. CanIRun.ai ha detectado esta problemática, aunque aún necesita perfeccionarse más.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.
