51,2 万 líneas de código, 1906 archivos, 59,8 MB de source map. En la madrugada del 31 de marzo, Chaofan Shou, de Solayer Labs, descubrió que el producto insignia de Anthropic, Claude Code, exponía el código fuente completo en un repositorio público de npm. En cuestión de horas, el código fue replicado en GitHub y el número de forks superó las 41.000.
Este no es el primer error de Anthropic. Cuando Claude Code se publicó por primera vez en febrero de 2025, ocurrió de nuevo un filtrado de source map similar. Esta vez el número de versión era v2.1.88; la causa del filtrado era la misma: la herramienta de compilación Bun genera source map de forma predeterminada, y el archivo .npmignore omitió ese archivo.
La mayoría de las coberturas repasan los huevos de pascua de lo filtrado, como un sistema de mascotas virtuales y un «modo infiltrado» para que Claude envíe código a proyectos open source de forma anónima. Pero lo realmente interesante para desmenuzar es por qué el mismo modelo de Claude se comporta tan diferente en la versión web y en Claude Code. ¿Qué están haciendo exactamente las 512.000 líneas de código?
El modelo es solo la punta del iceberg
La respuesta está en la estructura del código. Según el análisis de ingeniería inversa de la filtración de código fuente realizado por la comunidad de GitHub, de las 512.000 líneas de TypeScript, el código de interfaz que llama directamente al modelo de IA es solo de unas 8.000 líneas, es decir, el 1,6% del total.
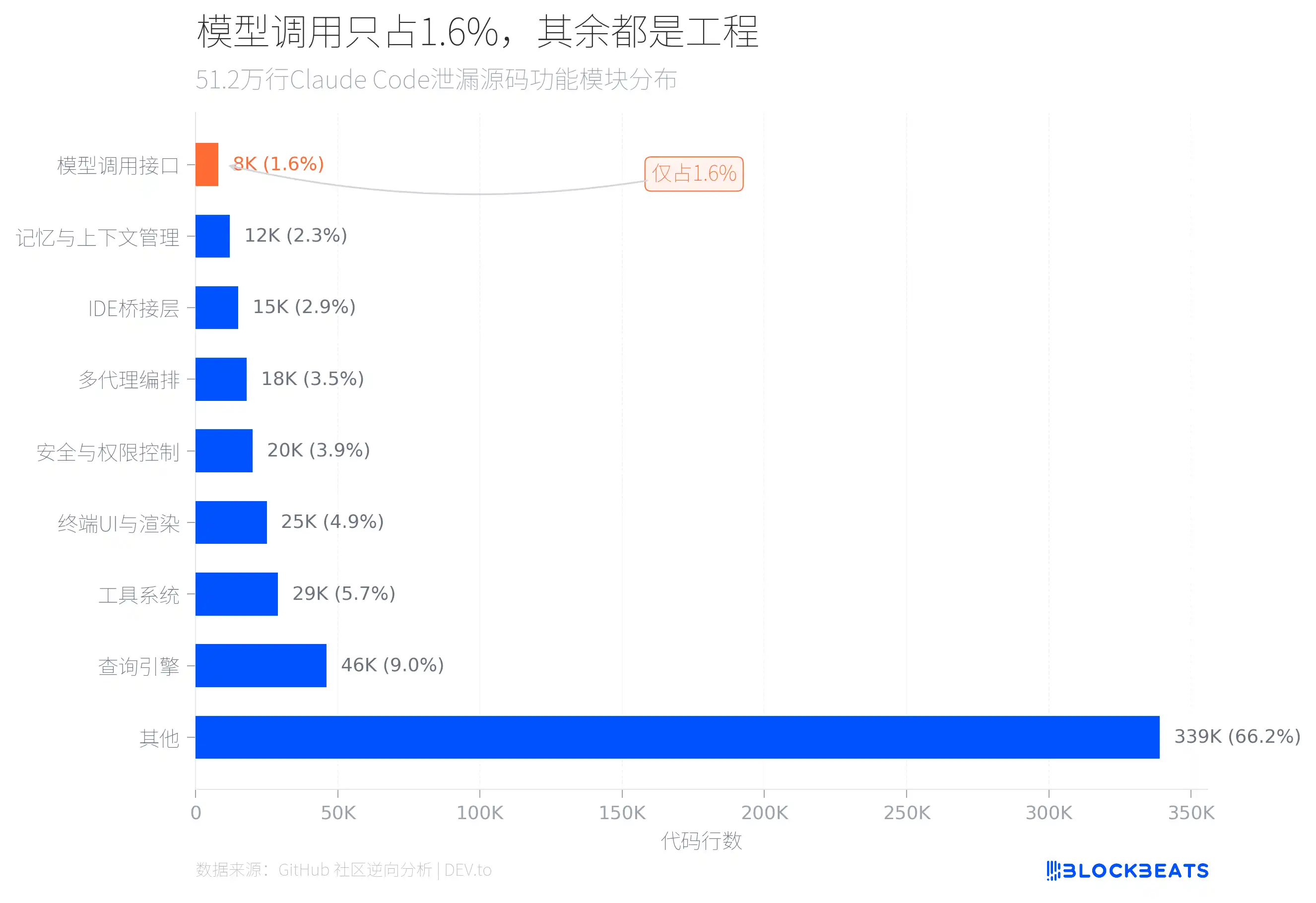
¿Y qué hace el 98,4% restante? Los dos módulos más grandes son el motor de consultas (46.000 líneas) y el sistema de herramientas (29.000 líneas). El motor de consultas gestiona las llamadas a la API de LLM, la salida en streaming, la orquestación de caché y la administración de conversaciones de múltiples turnos. El sistema de herramientas define alrededor de 40 herramientas integradas y 50 comandos con barra diagonal, formando una especie de arquitectura tipo plug-in, donde cada herramienta tiene controles de permisos independientes.
Además, hay 25.000 líneas de código para el renderizado de UI de terminal (uno de los archivos, llamado print.ts, tiene hasta 5594 líneas, y una sola función abarca 3167 líneas), 20.000 líneas de control de seguridad y permisos (incluye 23 comprobaciones de seguridad Bash numeradas y 18 comandos internos de Zsh enmascarados), y un sistema de orquestación de múltiples agentes de 18.000 líneas.
El investigador de investigación en aprendizaje automático Sebastian Raschka, tras analizar el código filtrado, señaló que la razón por la que Claude Code es más fuerte que la versión web con el mismo modelo no está en el modelo en sí, sino en el “andamiaje” de software construido alrededor del modelo, incluyendo carga del contexto del repositorio, programación de herramientas especializadas, estrategias de caché y colaboración de subagentes. Incluso considera que, si se aplica la misma arquitectura de ingeniería a otros modelos como DeepSeek o Kimi, también se podría obtener una mejora en el rendimiento de programación cercana.
Una comparación intuitiva ayuda a entender esta diferencia. Cuando escribes una pregunta en ChatGPT o en la versión web de Claude, el modelo procesa y devuelve la respuesta, y al terminar la conversación no queda nada. Pero la forma de hacer de Claude Code es completamente distinta: al iniciarse, primero lee los archivos de tu proyecto, entiende la estructura de tu repositorio, y recuerda tus preferencias, como «no mockees una base de datos en los tests». Puede ejecutar comandos directamente en tu terminal, editar archivos y ejecutar pruebas. Cuando hay tareas complejas, las divide en múltiples sub tareas y las asigna a distintos subagentes para que trabajen en paralelo. En otras palabras: la IA de la versión web es una ventana de preguntas y respuestas; Claude Code es un colaborador que vive en tu computadora.
Alguien comparó esta arquitectura con un sistema operativo: 42 herramientas integradas equivalen a llamadas al sistema, el sistema de permisos equivale a la administración de usuarios, el protocolo MCP corresponde a los drivers de dispositivos, y la orquestación de subagentes se parece a la planificación de procesos. Cada herramienta, por defecto al salir de fábrica, está marcada como «no segura, escribible», a menos que el desarrollador declare activamente que es segura. La herramienta para editar archivos fuerza a que se compruebe si ya leíste ese archivo; si no lo has leído, no te permite modificarlo. Esto no es simplemente un “plug-in” con unas cuantas herramientas para un chatbot; es un entorno de ejecución con el núcleo LLM y con un mecanismo de seguridad completo.
Esto significa una cosa: el muro de competencia de los productos de IA quizá no esté en la capa del modelo, sino en la capa de la ingeniería.
Cada vez que se rompe la caché, el costo se multiplica por 10
En el código filtrado hay un archivo llamado promptCacheBreakDetection.ts, que rastrea 14 vectores posibles que pueden causar la invalidación del prompt cache. Entonces, ¿por qué los ingenieros de Anthropic dedicarían tanto esfuerzo para evitar que la caché se rompa?
Mira la tarificación oficial de Anthropic y se entiende. Por ejemplo, para Claude Opus 4.6, el precio de entrada estándar es de 5 dólares por cada millón de tokens, pero si acierta la caché, el precio de lectura es de solo 0,5 dólares: un 90% más barato. Al contrario, cada vez que se rompe la caché, el costo de inferencia se multiplica por 10.
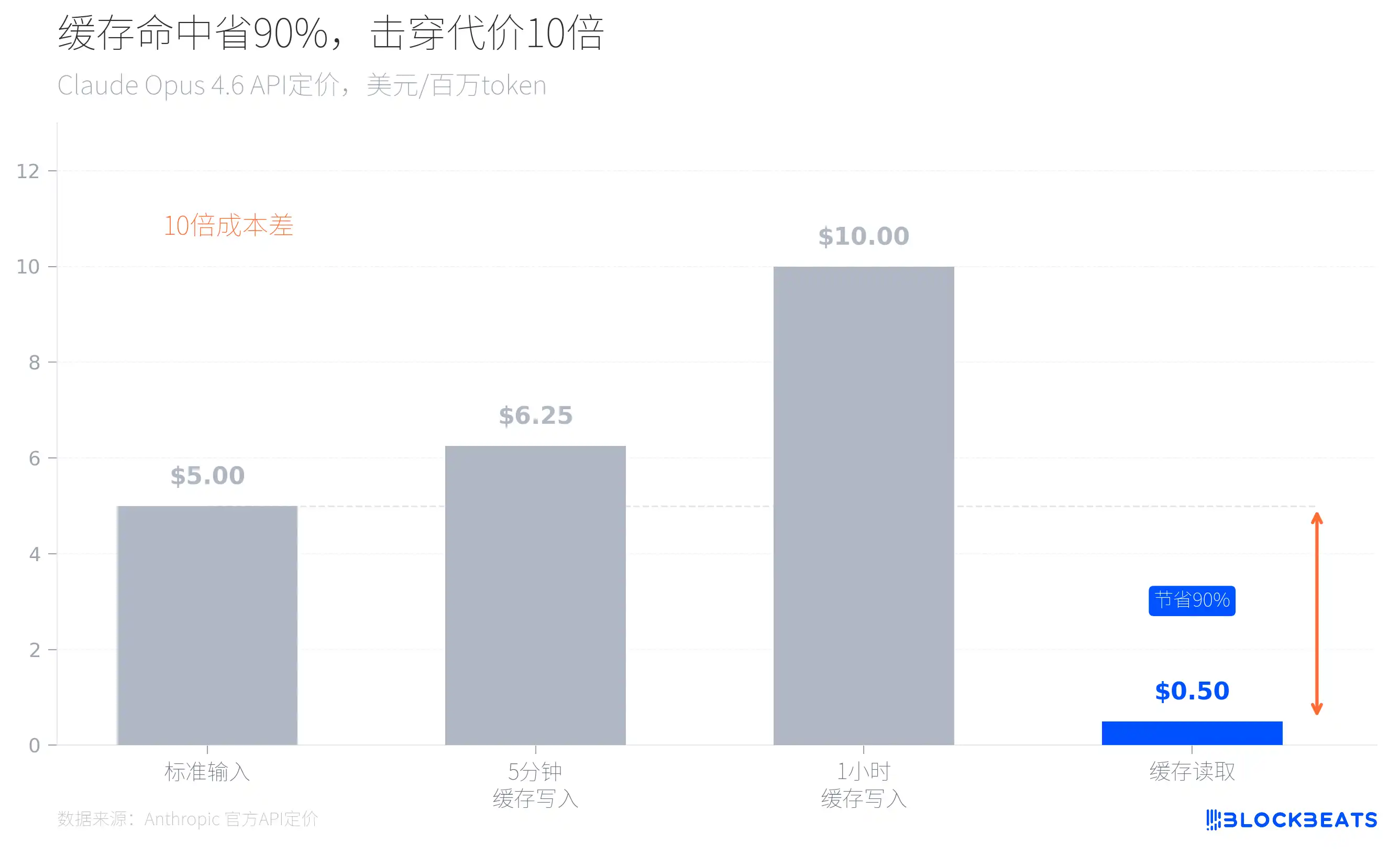
Esto explica muchas decisiones de arquitectura aparentemente «sobrediseñadas» dentro del código filtrado. Al iniciarse, Claude Code carga la rama git actual, los registros de commits recientes y el archivo CLAUDE.md como contexto; estos contenidos estáticos se cachean globalmente, y los límites se marcan para separar el contenido dinámico, asegurando que en cada conversación no se vuelva a procesar el contexto existente. En el código también hay un mecanismo llamado sticky latches, que evita que el cambio de modo destruya la caché ya establecida. Los subagentes están diseñados para reutilizar la caché del proceso padre, en lugar de reconstruir sus propias ventanas de contexto.
Aquí hay un detalle que vale la pena desarrollar. Quienes hayan usado herramientas de programación con IA saben que cuanto más larga es la conversación, más lento responde el AI, porque en cada vuelta se tiene que volver a enviar todo el historial previo al modelo. Un enfoque habitual es eliminar los mensajes antiguos para liberar espacio, pero el problema es que borrar cualquier mensaje rompe la continuidad de la caché, haciendo que todo el historial de la conversación deba reprocesarse; la latencia y los costos se disparan al mismo tiempo.
En el código filtrado existe un mecanismo llamado cache_edits: en vez de borrar realmente los mensajes, se marca a los mensajes antiguos con un indicador de «saltar» en la capa de API. El modelo ya no puede ver esos mensajes, pero no se rompe la continuidad de la caché. Esto significa que una conversación larga que dura varias horas, si limpias cientos de mensajes antiguos, la velocidad de la siguiente respuesta es casi igual a la de la primera. Para un usuario normal, esta es la respuesta de base de «por qué Claude Code puede soportar conversaciones infinitamente largas sin volverse lento».
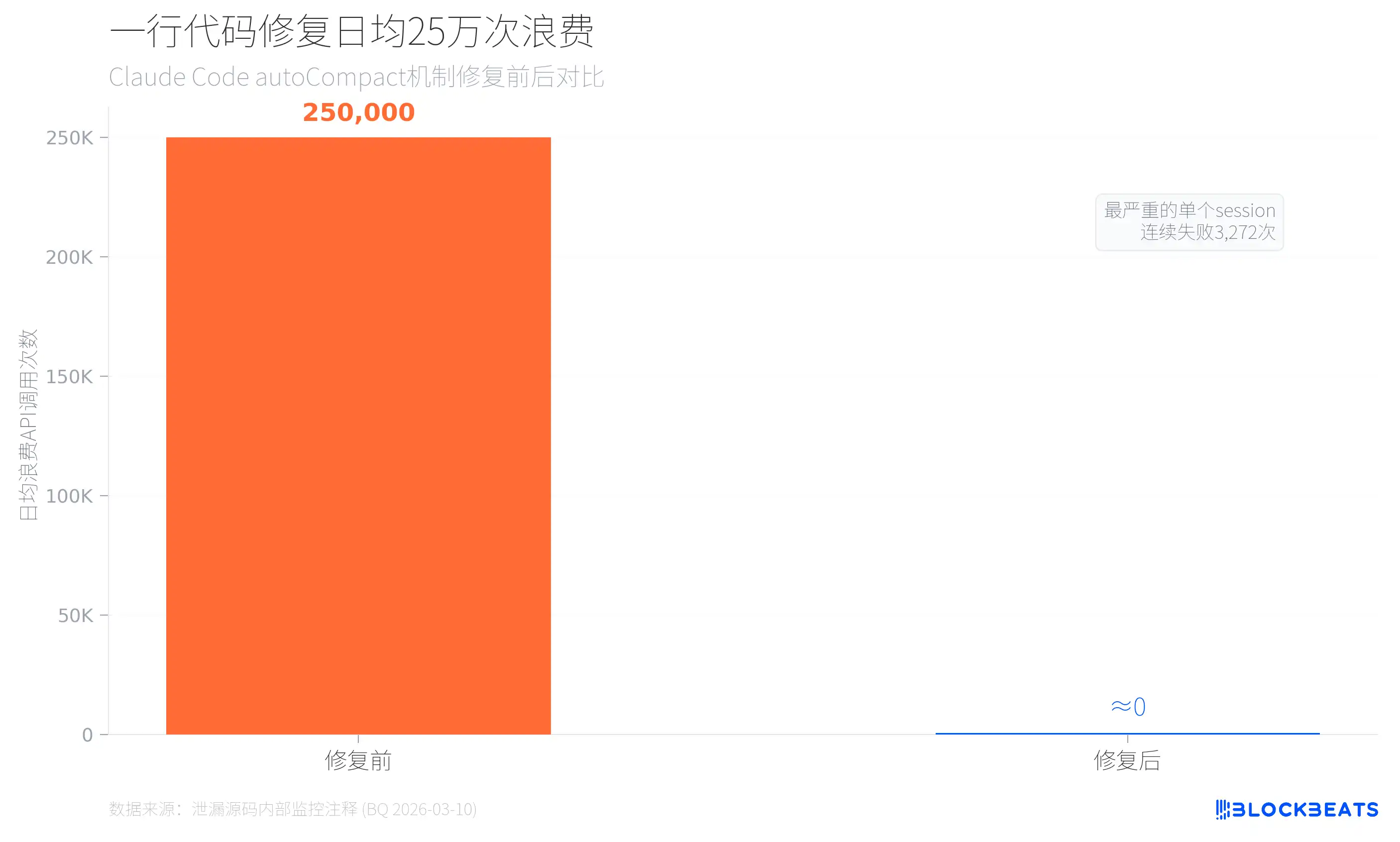
Según los datos internos de monitorización filtrados (provenientes de los comentarios en el código de autoCompact.ts, fechados el 10 de marzo de 2026), antes de introducir el límite de fallos de compresión automática, Claude Code desperdiciaba aproximadamente 250.000 llamadas diarias a la API. Hubo 1279 sesiones de usuario en las que ocurrieron más de 50 fallos consecutivos de compresión; la más grave falló 3272 veces seguidas. La solución fue solo añadir una línea de restricción: MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3.
Así que, para los productos de IA, puede que el costo de inferencia del modelo no sea el estrato más caro; los fallos de gestión de caché sí lo son.
44 interruptores, apuntan en la misma dirección
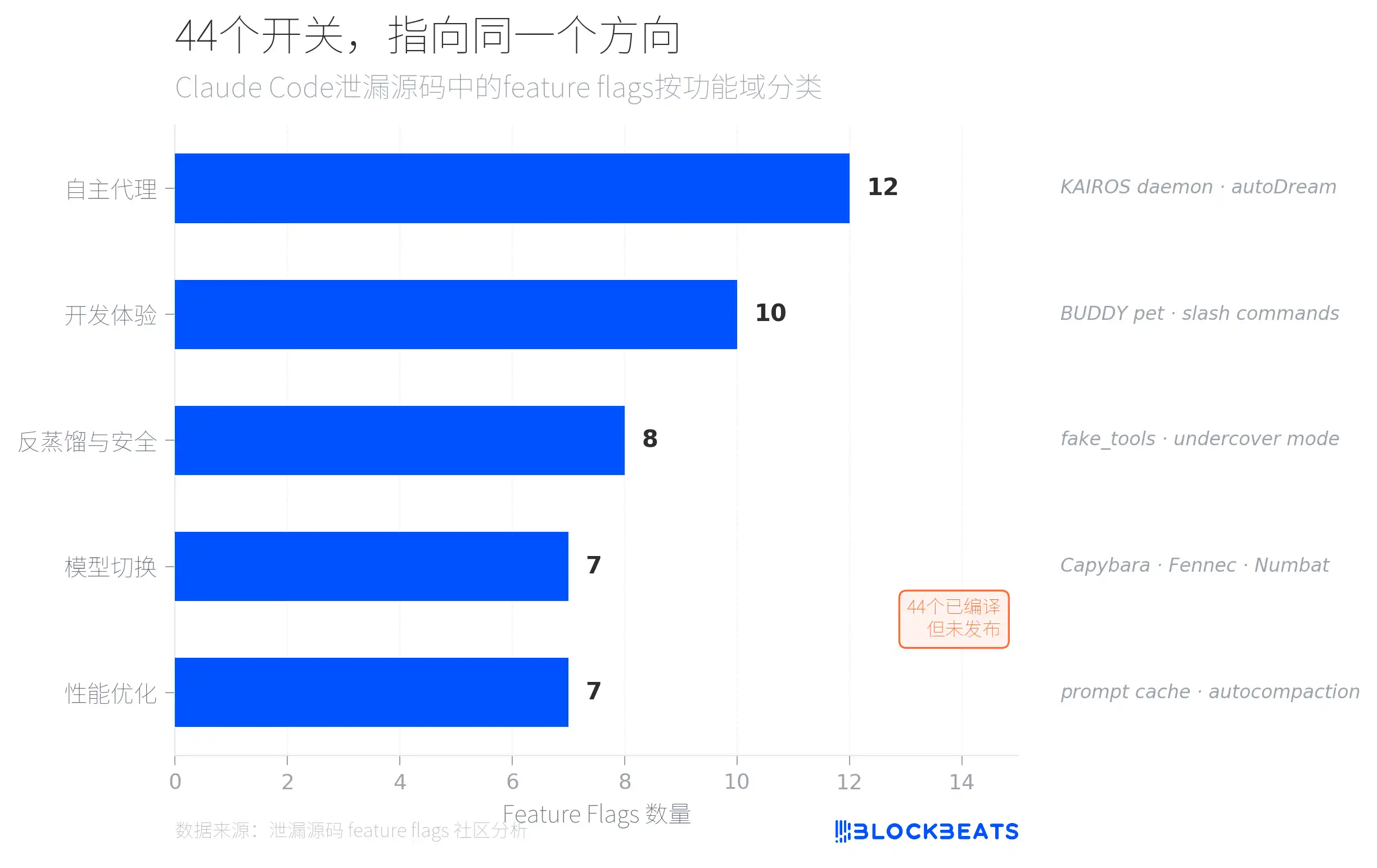
En el código filtrado se esconden 44 feature flags: interruptores de funciones ya compilados, pero que no se han publicado al exterior. Según el análisis de la comunidad, estos flags se dividen en cinco categorías por dominio de funciones, y la más densa es la de «agentes autónomos» (12), que apuntan a un sistema llamado KAIROS.
KAIROS aparece referenciado más de 150 veces en el código fuente; es un modo de demonio en segundo plano permanente. Claude Code ya no es solo una herramienta que responde cuando tú la llamas manualmente, sino un agente que permanece siempre ejecutándose en segundo plano, observando, registrando y actuando proactivamente cuando corresponde. La premisa es no interrumpir al usuario: cualquier operación que pueda bloquear al usuario por más de 15 segundos se retrasa.
KAIROS también tiene un subsistema integrado de detección de foco del terminal. En el código hay un campo llamado terminalFocus, que detecta en tiempo real si el usuario está mirando la ventana del terminal. Cuando cambias al navegador u otra aplicación, el agente determina que «no estás», cambia a modo autónomo y ejecuta tareas de forma proactiva, enviando código directamente sin esperar tu confirmación. Cuando vuelves al terminal, el agente regresa inmediatamente al modo colaborativo: primero informa lo que hizo y luego solicita tu opinión. El nivel de autonomía no es fijo; fluctúa en tiempo real según tu atención. Esto resuelve una situación incómoda de larga data para las herramientas de IA: una IA totalmente autónoma no genera confianza, y una IA totalmente pasiva es demasiado ineficiente. La elección de KAIROS es ajustar la proactividad de la IA dinámicamente con la atención del usuario: si lo miras, se queda quieta; si te vas, se pone a trabajar por su cuenta.
Otro subsistema de KAIROS se llama autoDream: cada vez que se acumulan 5 sesiones o se cumplen 24 horas, el agente inicia en segundo plano un proceso de «reflexión» en cuatro pasos. Primero, escanea memorias existentes para entender qué es lo que sabe actualmente. Luego, extrae nuevos conocimientos de los registros de conversación. Después, fusiona el conocimiento nuevo con el antiguo, corrige contradicciones y elimina duplicados. Por último, simplifica el índice y borra entradas desactualizadas. Este diseño se inspira en la teoría de consolidación de la memoria en las ciencias cognitivas. Cuando las personas duermen, ordenan los recuerdos del día; KAIROS, cuando el usuario se marcha, organiza el contexto del proyecto. Para el usuario común, esto significa que cuanto más uses Claude Code, más precisa será su comprensión de tu proyecto, y no solo «recuerda lo que le dijiste».
La segunda gran categoría es «anti-destilación y seguridad» (8 flags). De las más destacables está la mecánica fake_tools: cuando se cumplen simultáneamente 4 condiciones (flag activado en compilación, entrada CLI activada, uso de API de primera parte, y el switch remoto GrowthBook en true), Claude Code inyecta definiciones de herramientas falsas en las solicitudes de API. El objetivo es contaminar datasets que podrían estar en uso para grabar tráfico de API y entrenar modelos competidores. Esta es una forma de defensa totalmente nueva en la carrera armamentista de IA: no es evitar que copies, sino lograr que copies cosas equivocadas.
Además, en el código aparece un código de modelo Capybara (dividido en tres niveles: versión estándar, versión fast y versión con ventana de contexto de un millón), ampliamente conjeturado por la comunidad como el código interno de la serie Claude 5.
Huevos de pascua: en 512.000 líneas de código se esconde una mascota electrónica
Entre todas las arquitecturas de ingeniería serias y mecanismos de seguridad, los ingenieros de Anthropic también crearon silenciosamente un sistema completo de mascotas virtuales, con el alias interno BUDDY.
Según el código filtrado y el análisis de la comunidad, BUDDY es una mascota de terminal “imitativa” que aparece en forma de burbuja ASCII al lado del cuadro de entrada del usuario. Tiene 18 especies (incluyendo capibara, salamandra, hongo, fantasma, dragón y una serie de criaturas originales como Pebblecrab, Dustbunny, Mossfrog). Se clasifican en cinco niveles por rareza: común (60%), rara (25%), poco común (10%), épica (4%) y legendaria (1%). Cada especie también tiene una «variante brillante»; la raraest de todas, Shiny Legendary Nebulynx, aparece con una probabilidad de solo 1 entre 10.000.
Cada BUDDY tiene cinco atributos: DEBUGGING (depuración), PATIENCE (paciencia), CHAOS (caos), WISDOM (sabiduría) y SNARK (sarcasmo). También pueden llevar sombreros; las opciones incluyen corona, bombín, gorra de hélice, halo, sombrero de mago e incluso un patito miniatura. El valor hash del ID de usuario determina qué mascota eclosionarás; Claude generará para ella un nombre y una personalidad.
Según el plan de lanzamiento filtrado, BUDDY estaba programada para iniciar pruebas internas del 1 al 7 de abril, y para salir oficialmente en mayo, empezando por los empleados internos de Anthropic.
512.000 líneas de código, 98,4% haciendo ingeniería dura; pero al final alguien dedicó tiempo a una cría electrónica que lleva una gorra de hélice. Quizá sea esa la línea de código más humana dentro de la filtración.
Haz clic para conocer las vacantes de律动BlockBeats
Da la bienvenida a unirte a la comunidad oficial de律动 BlockBeats:
Telegram canal de suscripción: https://t.me/theblockbeats
Telegram grupo: https://t.me/BlockBeats_App
Cuenta oficial de Twitter: https://twitter.com/BlockBeatsAsia

