Au moment où cet article est publié, Amazon Web Services subit une importante panne qui perturbe une nouvelle fois l’infrastructure des cryptomonnaies. Dès 8h00 (heure du Royaume-Uni) ce matin, des dysfonctionnements dans la région US-EAST-1 d’AWS (datacenters de Virginie du Nord) ont paralysé Coinbase ainsi qu’une multitude de grandes plateformes crypto, parmi lesquelles Robinhood, Infura, Base et Solana.
AWS a reconnu des “taux d’erreurs accrus” impactant Amazon DynamoDB et EC2 — les services fondamentaux de base de données et de calcul sur lesquels reposent des milliers d’entreprises. Cette panne, survenue en temps réel, illustre parfaitement la thèse centrale de cet article : la dépendance de l’infrastructure crypto aux fournisseurs cloud centralisés crée des vulnérabilités systémiques, qui se manifestent systématiquement en période de tension.
Le moment est particulièrement instructif. Dix jours seulement après une cascade de liquidations de 19,3 milliards de dollars révélant des failles structurelles au niveau des plateformes d’échange, la panne AWS d’aujourd’hui démontre que le problème dépasse le cadre des plateformes individuelles et concerne l’infrastructure cloud sous-jacente. Lorsque AWS tombe, l’effet domino touche les exchanges centralisés, les plateformes “décentralisées” dépendantes de services centralisés, ainsi qu’innombrables autres services simultanément.
Ce n’est pas un accident isolé, mais bien un schéma récurrent. L’analyse ci-après recense des pannes AWS similaires survenues en avril 2025, décembre 2021 et mars 2017, qui ont à chaque fois mis à l’arrêt des services crypto majeurs. La question n’est plus de savoir si une nouvelle défaillance surviendra, mais quand, et quel en sera le facteur déclenchant.
Cascade de liquidations des 10-11 octobre 2025 : étude de cas
L’événement du 10-11 octobre 2025 constitue un cas d’école des modes de défaillance de l’infrastructure. À 20h00 UTC, une annonce géopolitique majeure provoque une vague de ventes sur l’ensemble du marché. En une heure, 6 milliards de dollars de liquidations sont enregistrés. À l’ouverture des marchés asiatiques, 19,3 milliards de dollars de positions à effet de levier se sont dissipés sur 1,6 million de comptes traders.
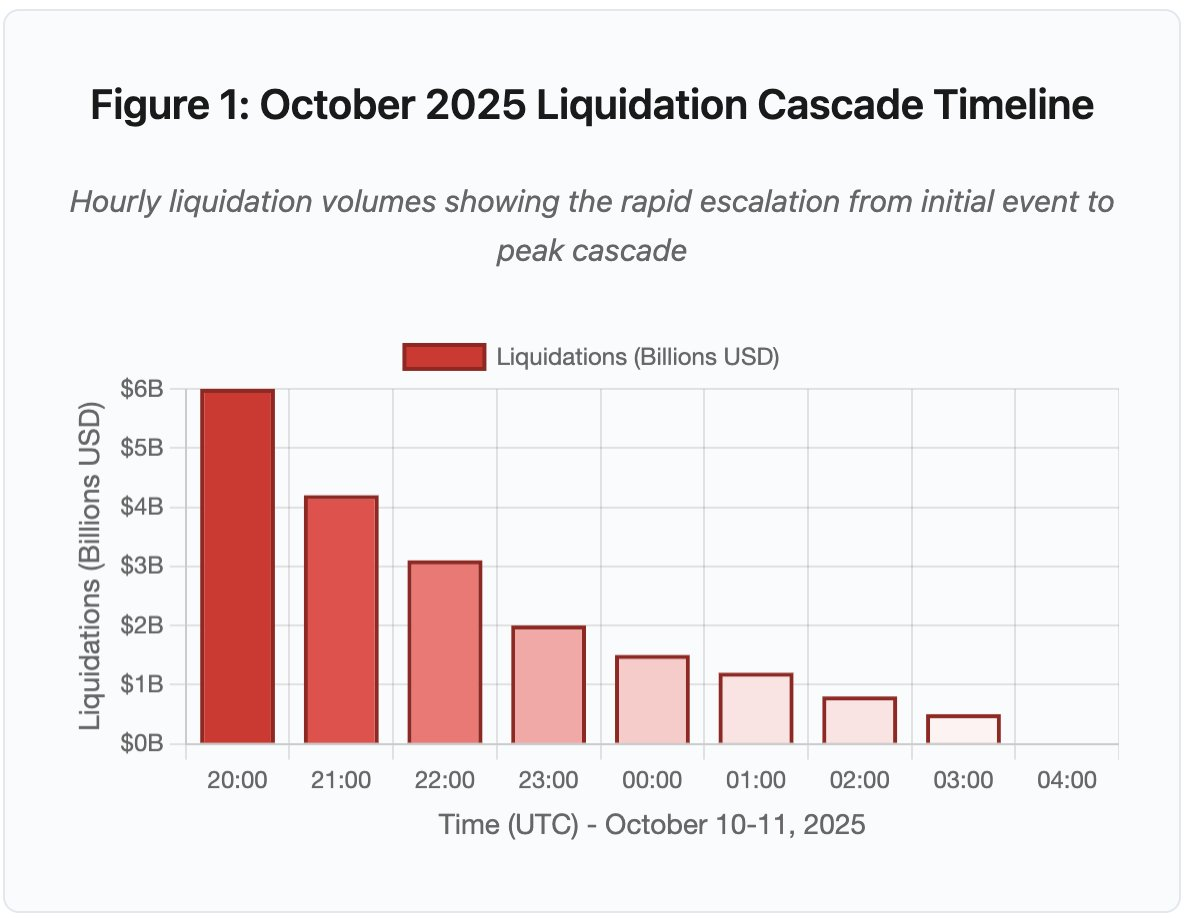
Figure 1 : Chronologie de la cascade de liquidations d’octobre 2025
Le graphique interactif illustre la progression spectaculaire des liquidations heure par heure. Dès la première heure, 6 milliards de dollars s’évaporent, suivi d’une seconde heure encore plus intense à mesure que la cascade s’accélère. Cette visualisation révèle :
- 20h00-21h00 : Choc initial — 6 Md$ liquidés (zone rouge)
- 21h00-22h00 : Pic de la cascade — 4,2 Md$ avec début du throttling API
- 22h00-04h00 : Dégradation prolongée — 9,1 Md$ sur des marchés peu liquides
- Points d’inflexion cruciaux : limitations API, retrait des market makers, raréfaction du carnet d’ordres
L’ampleur excède tout précédent sur les marchés crypto d’au moins un ordre de grandeur. La comparaison historique révèle la nature en escalier de l’événement :
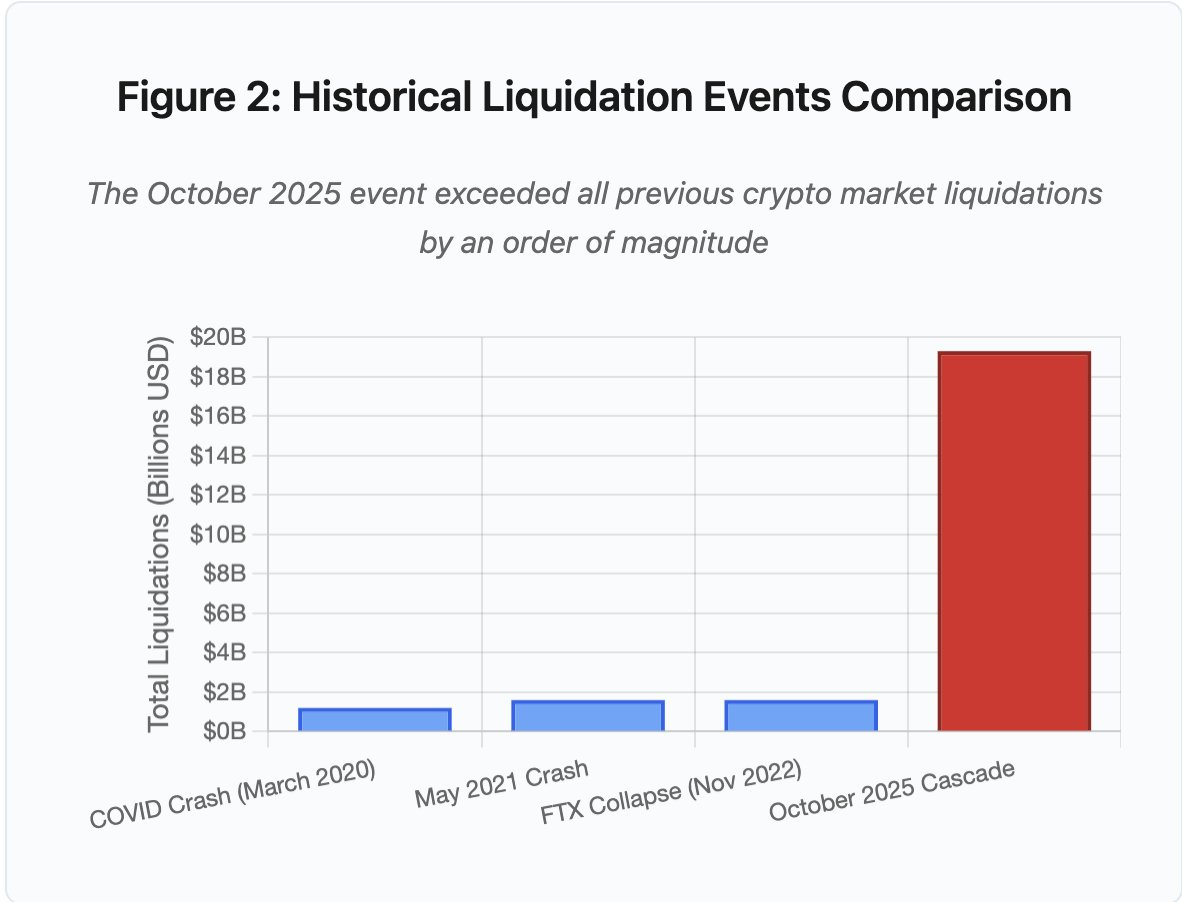
Figure 2 : Comparatif des événements historiques de liquidation
Le graphique en barres souligne la singularité d’octobre 2025 :
- mars 2020 (COVID) : 1,2 Md$
- mai 2021 (krach) : 1,6 Md$
- novembre 2022 (FTX) : 1,6 Md$
- octobre 2025 : 19,3 Md$ ⚠️ soit 16 fois le précédent record
Mais les montants des liquidations ne sont qu’une partie du problème. La question cruciale porte sur le mécanisme : comment un événement externe de marché a-t-il déclenché ce mode de défaillance précis ? La réponse dévoile des faiblesses systémiques, tant dans l’infrastructure des exchanges centralisés que dans la conception des protocoles blockchain.
Défaillances hors chaîne : architecture des exchanges centralisés
Surcharge d’infrastructure et limites de débit
Les APIs des exchanges appliquent des limitations de débit pour prévenir les abus et gérer la charge serveur. En temps normal, ces restrictions autorisent le trading légitime tout en bloquant d’éventuelles attaques. Mais lors de volatilité extrême, quand des milliers de traders souhaitent simultanément ajuster leur position, ces mêmes restrictions deviennent des goulets d’étranglement.
Les CEX limitent la notification des liquidations à une par seconde, même lorsqu’ils en traitent des milliers à la seconde. Lors de la cascade d’octobre, cela a créé une opacité : les utilisateurs étaient incapables d’évaluer en temps réel la gravité de la situation. Les outils de monitoring tiers affichaient des centaines de liquidations par minute alors que les flux officiels en montraient bien moins.
Les limitations API ont empêché les traders de modifier leur position durant la première heure critique. Les demandes de connexion ont expiré. Les ordres n’ont pas été validés. Les stop-loss n’ont pas été exécutés. Les requêtes de position renvoyaient des données périmées. Ce verrou infrastructurel a transformé un événement de marché en crise opérationnelle.
Les exchanges traditionnels provisionnent leur infrastructure pour la charge normale avec une marge de sécurité. Mais la charge normale diffère radicalement de la charge sous stress. Le volume moyen quotidien de transactions prédit mal les besoins en situation extrême. Lors de cascades, le volume explose par 100 ou plus. Les requêtes de positions augmentent par 1 000 lorsque chaque utilisateur vérifie simultanément son compte.
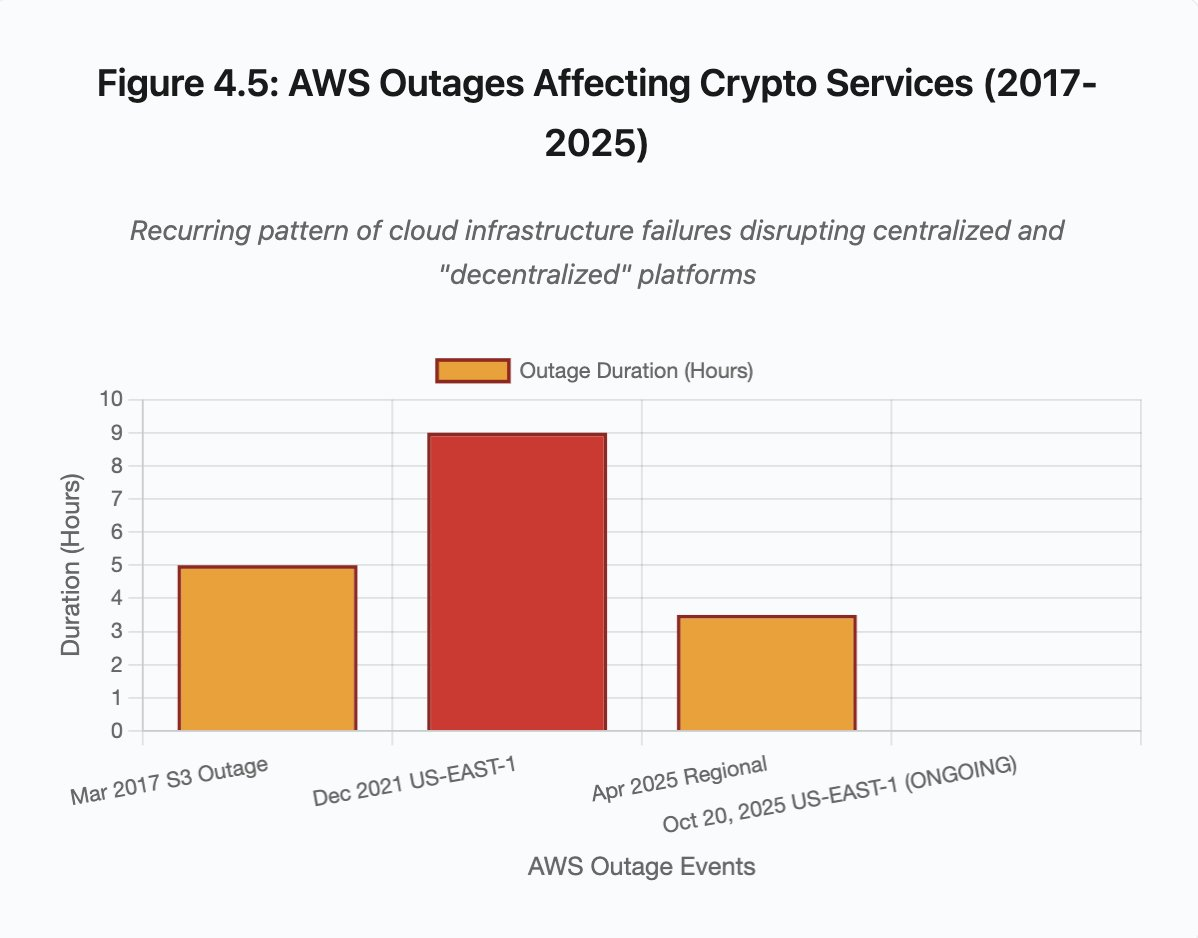
Figure 4.5 : Pannes AWS impactant les services crypto
L’infrastructure cloud à mise à l’échelle automatique aide, mais ne réagit pas instantanément. Le déploiement de réplicas de lecture de bases de données prend plusieurs minutes. Créer de nouvelles instances API prend également plusieurs minutes. Pendant ce laps de temps, les systèmes de marge continuent de valoriser les positions sur la base de prix corrompus provenant de carnets d’ordres saturés.
Manipulation d’oracle et vulnérabilités de tarification
Lors de la cascade d’octobre, un choix de conception critique des systèmes de marge est apparu : certains exchanges calculaient la valeur du collatéral sur la base des prix spot internes, plutôt que sur les flux externes d’oracle. En conditions normales, les arbitragistes maintiennent l’alignement des prix. Mais lorsque l’infrastructure est sous tension, ce couplage s’effondre.
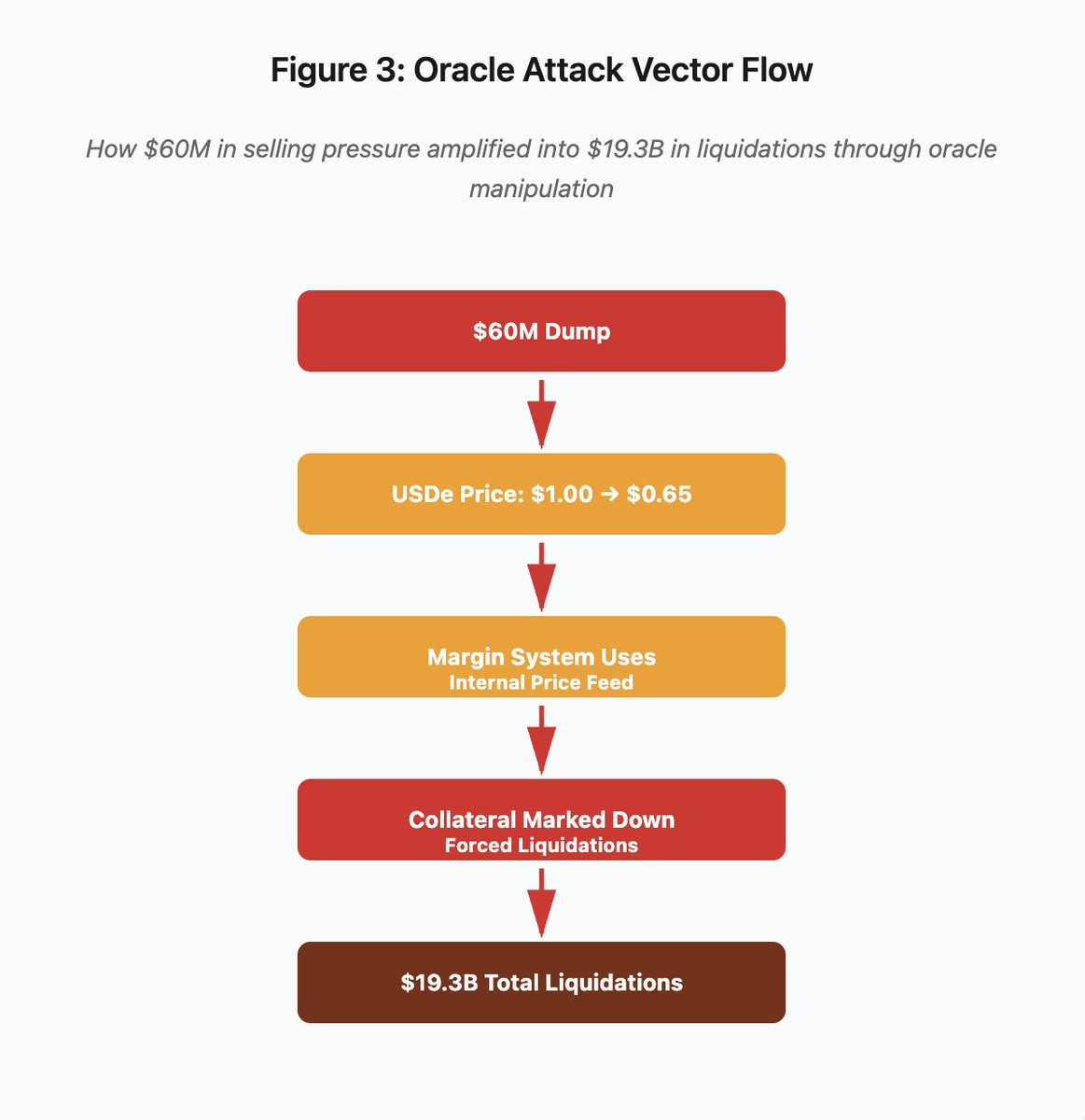
Figure 3 : Schéma du flux de manipulation d’oracle
Le diagramme interactif illustre l’attaque en cinq étapes :
- Dump initial : pression vendeuse de 60 M$ sur USDe
- Manipulation du prix : USDe s’effondre de 1,00 $ à 0,65 $ sur une seule plateforme
- Défaillance de l’oracle : le système de marge utilise le flux spot interne corrompu
- Déclenchement de la cascade : le collatéral est dévalorisé, les liquidations forcées démarrent
- Amplification : 19,3 Md$ de liquidations au total (amplification x322)
L’attaque a exploité l’utilisation par Binance des prix spot pour le collatéral synthétique. Un attaquant a écoulé 60 millions de dollars de USDe sur des carnets d’ordres peu liquides, ce qui a fait chuter le prix spot de 1,00 $ à 0,65 $. Le système de marge, configuré pour valoriser le collatéral au prix spot, a marqué à la baisse toutes les positions collatéralisées en USDe de 35 %. Cela a déclenché des appels de marge et des liquidations forcées sur des milliers de comptes.
Ces liquidations ont entraîné de nouvelles ventes sur le même marché peu liquide, accentuant encore la baisse des prix. Le système de marge, observant ces prix plus bas, a marqué à la baisse encore plus de positions. La boucle de rétroaction a transformé une pression vendeuse de 60 millions en 19,3 milliards de liquidations forcées.

Figure 4 : Boucle de rétroaction de la cascade de liquidations
Le schéma circulaire illustre la dynamique auto-renforçante de la cascade :
Baisse du prix → déclenchement des liquidations → ventes forcées → nouvelle baisse du prix → [cycle répété]
Ce mécanisme n’aurait pas fonctionné avec un système d’oracle bien conçu. Si Binance avait utilisé des prix moyens pondérés dans le temps (TWAP) sur plusieurs plateformes, la manipulation temporaire n’aurait pas affecté la valorisation du collatéral. Avec des flux agrégés de Chainlink ou d’autres oracles multi-sources, l’attaque aurait échoué.
L’incident wBETH, survenu quatre jours plus tôt, a révélé une vulnérabilité similaire. Wrapped Binance ETH (wBETH) est censé maintenir une parité 1:1 avec ETH. Lors de la cascade, la liquidité s’est tarie et le marché spot wBETH/ETH affichait une décote de 20 %. Le système de marge a marqué à la baisse le collatéral wBETH, déclenchant des liquidations sur des positions pourtant pleinement collatéralisées par l’ETH sous-jacent.
Mécanismes d’Auto-Deleveraging (ADL)
Lorsque les liquidations ne peuvent être exécutées aux prix de marché, les exchanges appliquent l’Auto-Deleveraging pour mutualiser les pertes entre traders bénéficiaires. L’ADL ferme de force des positions bénéficiaires aux prix courants afin de couvrir le déficit des positions liquidées.
Pendant la cascade d’octobre, Binance a activé l’ADL sur plusieurs paires de trading. Les traders en position longue profitable ont vu leurs positions fermées de force, non par défaut de gestion du risque, mais parce que d’autres positions devenaient insolvables.
L’ADL reflète un choix d’architecture fondamental dans le trading de dérivés centralisés. Les plateformes garantissent qu’elles ne perdent pas d’argent. Les pertes doivent donc être absorbées par :
- des fonds d’assurance (capitaux dédiés aux défauts de liquidation)
- l’ADL (fermeture forcée de positions bénéficiaires)
- la mutualisation des pertes (répartition sur tous les utilisateurs)
La taille du fonds d’assurance par rapport à l’intérêt ouvert conditionne la fréquence de l’ADL. En octobre 2025, le fonds d’assurance de Binance atteignait environ 2 milliards de dollars. Face à 4 milliards de dollars d’intérêt ouvert sur les futures perpétuels BTC, ETH et BNB, cela représente une couverture de 50 %. Mais lors de la cascade d’octobre, l’intérêt ouvert dépassait 20 milliards de dollars sur l’ensemble des paires. Le fonds d’assurance était insuffisant.
Après la cascade d’octobre, Binance a annoncé garantir l’absence d’ADL sur les contrats BTC, ETH et BNB USDⓈ-M tant que l’intérêt ouvert total reste inférieur à 4 milliards de dollars. Cela crée une incitation : les exchanges peuvent maintenir des fonds d’assurance plus importants pour éviter l’ADL, mais cela immobilise du capital qui pourrait être utilisé plus efficacement.
Défaillances sur chaîne : limites des protocoles blockchain
Le graphique en barres compare les durées d’indisponibilité des différents incidents :
- Solana (févr. 2024) : 5 heures — saturation du throughput de vote
- Polygon (mars 2024) : 11 heures — incompatibilité de version des validateurs
- Optimism (juin 2024) : 2,5 heures — surcharge du séquenceur (airdrop)
- Solana (sept. 2024) : 4,5 heures — attaque par spam de transactions
- Arbitrum (déc. 2024) : 1,5 heure — défaillance du fournisseur RPC
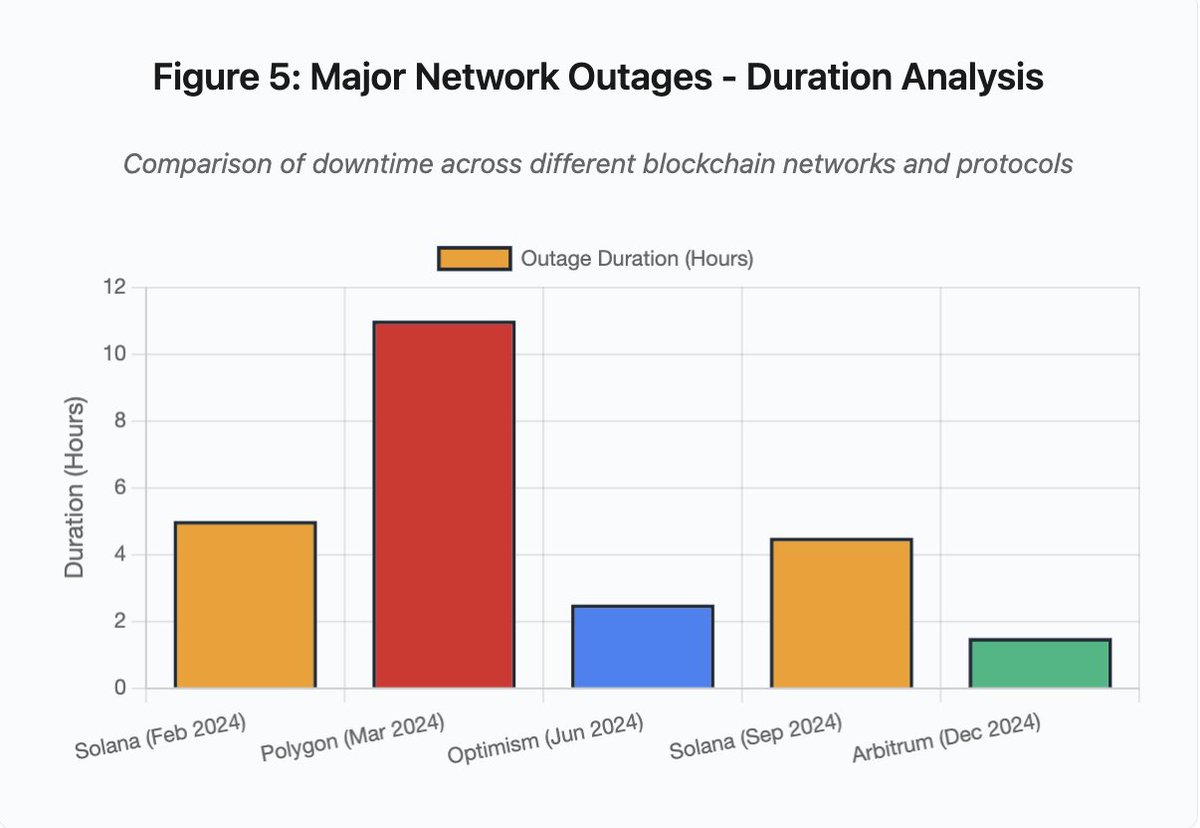
Figure 5 : Durée des pannes réseau majeures
Solana : le goulet d’étranglement du consensus
Solana a connu plusieurs pannes en 2024-2025. Celle de février 2024 a duré environ 5 heures. Celle de septembre 2024, 4,5 heures. Ces interruptions trouvent leur origine dans l’incapacité du réseau à traiter le volume de transactions en cas d’attaque par spam ou d’activité extrême.
Détail figure 5 : Les pannes Solana (5 heures en février, 4,5 heures en septembre) illustrent les faiblesses récurrentes de la résilience du réseau sous stress.
L’architecture de Solana privilégie le throughput. En conditions idéales, le réseau traite 3 000 à 5 000 transactions par seconde avec une finalité sous la seconde. Cette performance dépasse de loin Ethereum. Mais lors d’événements extrêmes, cette optimisation engendre des vulnérabilités.
L’incident de septembre 2024 découle d’un afflux massif de transactions spam qui a saturé les mécanismes de vote des validateurs. Les validateurs Solana doivent voter sur les blocs pour atteindre le consensus. En fonctionnement normal, ils priorisent les transactions de vote pour assurer la progression du consensus. Mais le protocole classait auparavant ces transactions comme ordinaires sur le marché des frais.
Lorsque le mempool a été saturé par des millions de transactions spam, les validateurs ont eu du mal à transmettre les transactions de vote. Faute de votes suffisants, les blocs ne pouvaient pas être finalisés. Sans blocs finalisés, la chaîne s’est figée. Les utilisateurs avec des transactions en attente les ont vues bloquées dans le mempool. Les nouvelles transactions ne pouvaient pas être soumises.
StatusGator a recensé plusieurs interruptions de service Solana en 2024-2025 jamais officiellement reconnues par Solana. Cela crée une asymétrie d’information. Les utilisateurs ne distinguent pas les pannes locales des incidents réseau généralisés. Les services tiers de monitoring apportent de la transparence, mais les plateformes devraient tenir des pages de statut exhaustives.
Ethereum : l’explosion des frais de gas
Ethereum a subi des hausses extrêmes de frais de gas lors du boom DeFi en 2021. Les frais de transaction ont dépassé 100 $ pour des transferts simples, et jusqu’à 500–1 000 $ pour des interactions complexes avec des smart contracts. Ces frais ont rendu le réseau impraticable pour les petits montants et ouvert un autre vecteur d’attaque : l’extraction de MEV.
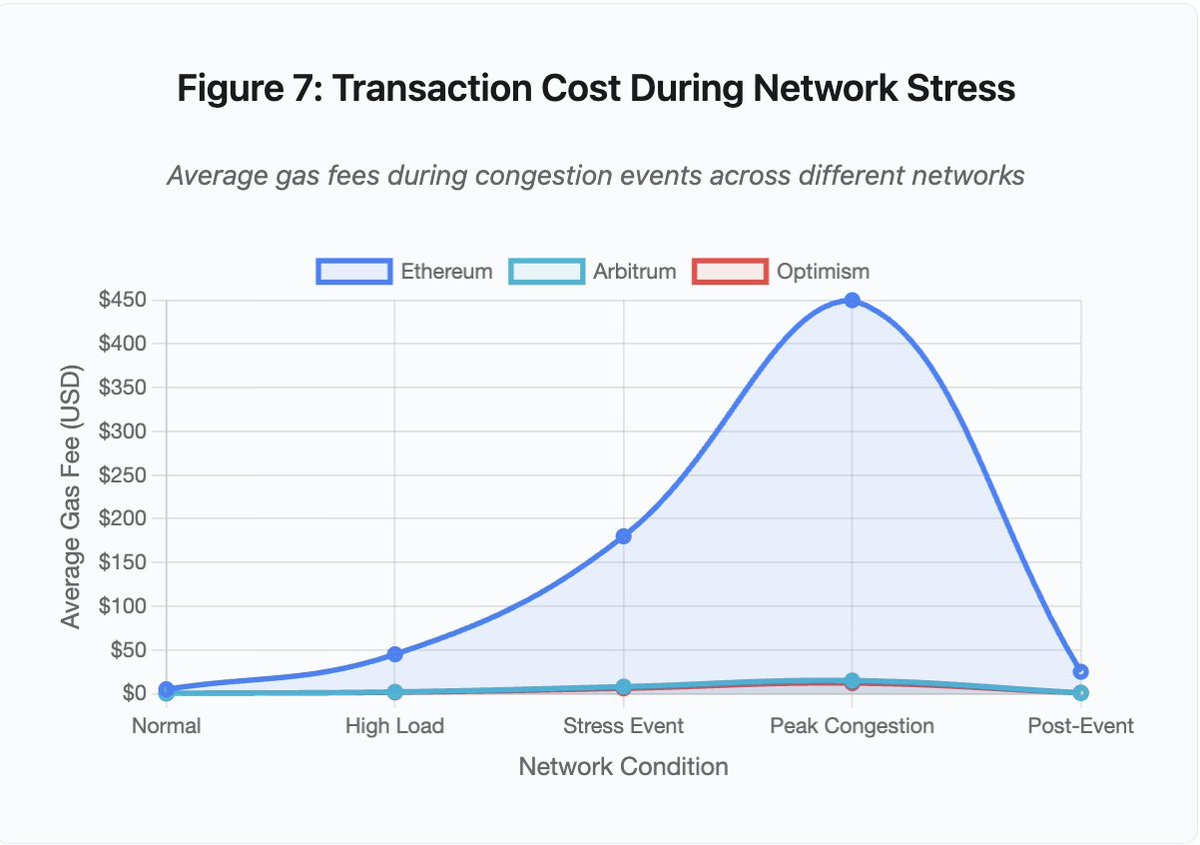
Figure 7 : Coût des transactions lors de stress réseau
Ce graphique linéaire illustre la flambée des frais de gas en situation de congestion :
- Ethereum : 5 $ (normal) → 450 $ (pic de congestion) — x90
- Arbitrum : 0,50 $ → 15 $ — x30
- Optimism : 0,30 $ → 12 $ — x40
La visualisation démontre que même les solutions Layer 2 subissent une forte inflation des frais, bien que le niveau initial soit bien plus faible.
Le Maximal Extractable Value (MEV) désigne les profits que les validateurs peuvent extraire en réordonnant, incluant ou excluant des transactions. En période de frais élevés, le MEV devient particulièrement lucratif. Les arbitragistes rivalisent pour devancer les gros ordres DEX. Les bots de liquidation cherchent à liquider les positions sous-collatéralisées en priorité. Cette compétition se traduit par des enchères sur les frais de gas.
Les utilisateurs voulant inclure leur transaction en période de congestion doivent surenchérir face aux bots MEV. Cela crée des situations où le coût de la transaction dépasse sa valeur. Vous voulez réclamer un airdrop de 100 $ ? Payez 150 $ de gas. Besoin d’ajouter du collatéral pour éviter la liquidation ? Affrontez des bots prêts à payer 500 $ pour la priorité.
La limite de gas Ethereum plafonne le calcul total par bloc. En cas de congestion, les utilisateurs se disputent l’espace disponible. Le marché des frais fonctionne comme prévu : ceux qui paient le plus sont prioritaires. Mais ce modèle rend le réseau de plus en plus coûteux lors des pics d’utilisation, précisément quand l’accès est le plus crucial.
Les solutions Layer 2 ont tenté d’apporter une réponse en déplaçant le calcul hors chaîne tout en héritant de la sécurité Ethereum via un règlement périodique. Optimism, Arbitrum et autres rollups traitent des milliers de transactions hors chaîne, puis soumettent des preuves compressées sur Ethereum. Cette architecture réduit efficacement le coût par transaction en fonctionnement normal.
Layer 2 : le goulet d’étranglement du séquenceur
Mais les solutions Layer 2 introduisent de nouveaux points de blocage. Optimism a connu une panne lorsque 250 000 adresses ont réclamé un airdrop simultanément en juin 2024. Le séquenceur — qui ordonne les transactions avant soumission à Ethereum — a été saturé. Les utilisateurs n’ont pas pu soumettre de transactions pendant plusieurs heures.
Cet incident montre que déplacer le calcul hors chaîne n’élimine pas les exigences infrastructurelles. Les séquenceurs doivent traiter les transactions entrantes, les ordonner, les exécuter et générer des preuves de fraude ou ZK pour le règlement sur Ethereum. En trafic extrême, les séquenceurs sont confrontés aux mêmes défis de montée en charge que les blockchains autonomes.
Plusieurs fournisseurs RPC doivent rester actifs. Si le fournisseur principal tombe, les utilisateurs doivent pouvoir basculer automatiquement. Lors de la panne Optimism, certains RPC sont restés fonctionnels tandis que d’autres ont échoué. Les wallets configurés sur un fournisseur défaillant ne pouvaient plus interagir avec la chaîne, même si celle-ci restait active.
Les pannes AWS ont révélé à plusieurs reprises les risques liés à la concentration de l’infrastructure dans l’écosystème crypto :
- 20 octobre 2025 (aujourd’hui) : panne régionale US-EAST-1 impactant Coinbase, Venmo, Robinhood et Chime. AWS signale des taux d’erreurs accrus sur DynamoDB et EC2.
- avril 2025 : panne régionale affectant Binance, KuCoin et MEXC simultanément. Plusieurs exchanges majeurs sont tombés suite à la défaillance de leurs composants hébergés sur AWS.
- décembre 2021 : panne US-EAST-1 ayant paralysé Coinbase, Binance.US et l’exchange “décentralisé” dYdX pendant 8 à 9 heures, impactant également les entrepôts Amazon et des services de streaming majeurs.
- mars 2017 : panne S3 bloquant l’accès à Coinbase et GDAX pendant cinq heures, avec une perturbation générale d’internet.
Le schéma est clair : ces exchanges hébergent des composants critiques sur AWS. Lors de pannes régionales AWS, plusieurs exchanges et services deviennent simultanément indisponibles. Les utilisateurs ne peuvent accéder à leurs fonds, exécuter des trades ou modifier leur position — précisément lorsque la volatilité exige une action immédiate.
Polygon : incompatibilité de version du consensus
Polygon (anciennement Matic) a subi une panne de 11 heures en mars 2024. La cause était une incompatibilité de versions des validateurs. Certains opéraient avec une version logicielle ancienne, d’autres avec une version mise à jour. Les transitions d’état divergeaient selon les versions.
Détail figure 5 : la panne Polygon (11 heures) est la plus longue parmi les incidents majeurs, illustrant la gravité des défaillances de consensus.
Lorsque les validateurs ne parviennent pas à s’accorder sur l’état correct, le consensus échoue. La chaîne ne produit plus de blocs, car les validateurs ne s’accordent pas sur leur validité. Cela créé un blocage : les validateurs sur l’ancienne version rejettent les blocs des validateurs sur la nouvelle, et inversement.
La résolution exige une mise à niveau coordonnée des validateurs. Mais cette coordination prend du temps : chaque opérateur doit être contacté, déployer la bonne version et redémarrer son nœud. Dans un réseau décentralisé de centaines d’opérateurs indépendants, cela peut durer des heures ou des jours.
Les hard forks utilisent généralement des déclencheurs de hauteur de bloc. Tous les validateurs mettent à jour au même bloc, assurant une activation simultanée. Mais cela nécessite une coordination préalable. Les mises à niveau progressives, où les validateurs adoptent la nouvelle version au fil de l’eau, risquent d’engendrer l’incompatibilité qui a causé la panne Polygon.
Arbitrages architecturaux
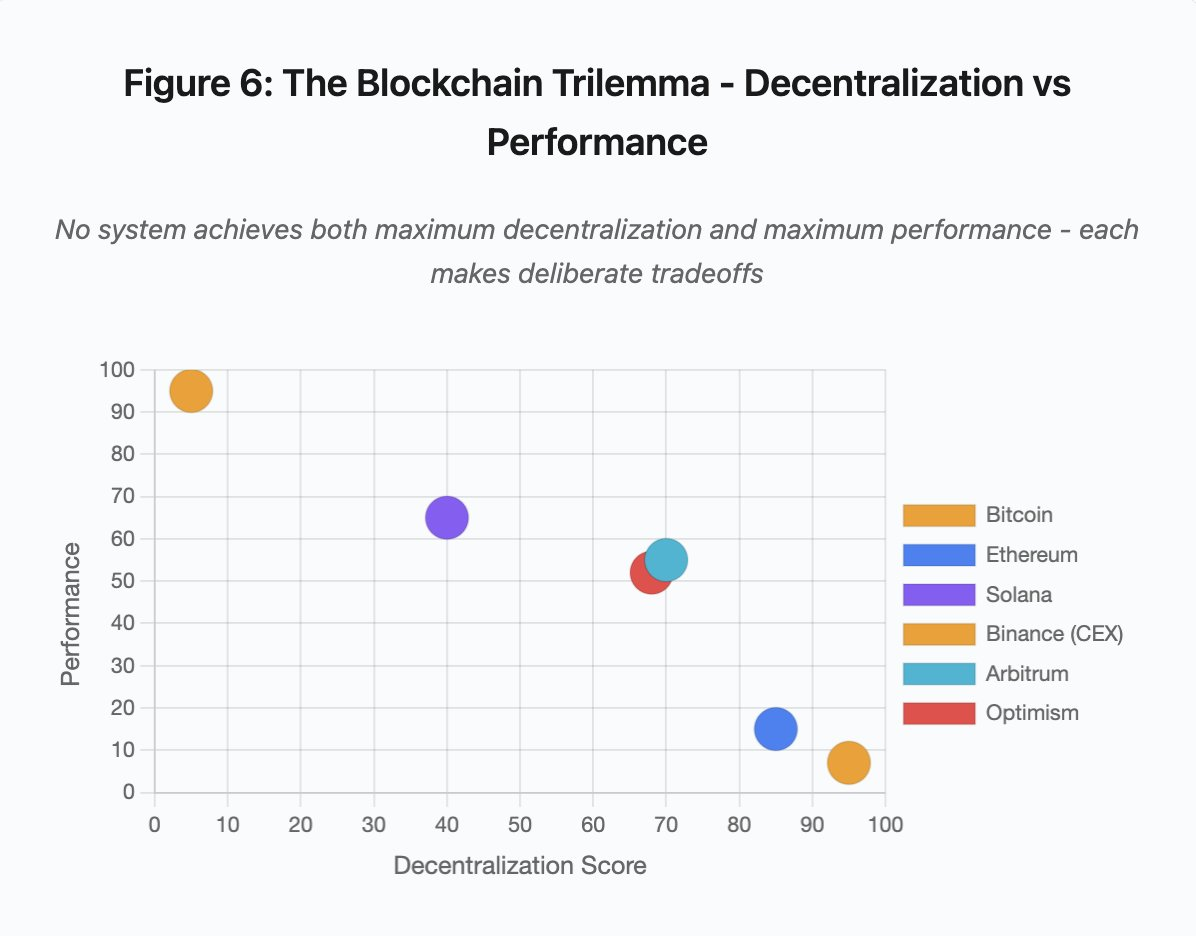
Figure 6 : Trilemme blockchain — décentralisation vs performance
Ce graphique cartographie les systèmes selon deux dimensions clés :
- Bitcoin : forte décentralisation, faible performance
- Ethereum : forte décentralisation, performance modérée
- Solana : décentralisation moyenne, haute performance
- Binance (CEX) : décentralisation minimale, performance maximale
- Arbitrum/Optimism : décentralisation moyenne à forte, performance moyenne
Enseignement principal : aucun système n’atteint à la fois le maximum de décentralisation et de performance. Chaque conception arbitre selon la cible d’usage.
Les exchanges centralisés atteignent une faible latence grâce à une architecture simple. Les moteurs de matching traitent les ordres en microsecondes, l’état est centralisé en base de données. Aucun protocole de consensus n’ajoute de surcharge. Mais cette simplicité crée des points de défaillance uniques. Sous stress, les défaillances se propagent en cascade dans des systèmes étroitement couplés.
Les protocoles décentralisés distribuent l’état entre validateurs, éliminant les points de défaillance uniques. Les chaînes à haut throughput conservent cette propriété lors des pannes (pas de perte de fonds, seule la disponibilité est temporairement compromise). Mais atteindre le consensus entre validateurs distribués implique une surcharge computationnelle. Les validateurs doivent se mettre d’accord avant chaque transition d’état. En cas de versions incompatibles ou de trafic extrême, le consensus peut s’arrêter temporairement.
Multiplier les réplicas améliore la tolérance aux pannes, mais augmente les coûts de coordination. Chaque validateur supplémentaire dans un système byzantin accroît la surcharge de communication. Les architectures à haut throughput minimisent cette surcharge par des communications optimisées, ce qui améliore la performance mais expose à certains schémas d’attaque. Les architectures axées sur la sécurité privilégient la diversité des validateurs et la robustesse du consensus, limitant le throughput mais maximisant la résilience.
Les solutions Layer 2 tentent de combiner ces deux propriétés par une architecture hiérarchique. Elles héritent de la sécurité Ethereum via le règlement L1 tout en offrant un throughput élevé grâce au calcul off-chain. Cependant, elles introduisent de nouveaux goulets d’étranglement au niveau du séquenceur et des RPC, démontrant que la complexité architecturale engendre de nouveaux modes de défaillance tout en en résolvant d’autres.
L’évolutivité reste le problème fondamental
Ces incidents révèlent un schéma constant : les systèmes sont dimensionnés pour la charge normale, puis échouent de façon catastrophique sous stress. Solana gérait le trafic routinier mais s’est effondré lors d’une multiplication par 10 000 du volume de transactions. Les frais de gas Ethereum restaient raisonnables jusqu’à ce que l’adoption DeFi provoque la congestion. Optimism fonctionnait correctement jusqu’à la réclamation simultanée de 250 000 airdrops. Les APIs de Binance suffisaient en temps normal mais ont saturé lors de la cascade de liquidations.
L’épisode d’octobre 2025 a illustré cette dynamique au niveau des exchanges. En fonctionnement normal, les limitations API et connexions base de données de Binance sont suffisantes. Sous cascade, quand chaque trader tente simultanément d’ajuster sa position, ces limites deviennent des goulets d’étranglement. Le système de marge, censé protéger l’exchange par des liquidations forcées, a aggravé la crise en générant des vendeurs forcés au pire moment.
La mise à l’échelle automatique ne suffit pas face à une hausse brutale de la charge. Le déploiement de serveurs prend plusieurs minutes. Pendant ce temps, les systèmes de marge marquent les positions sur des prix corrompus issus de carnets d’ordres peu liquides. Quand la capacité supplémentaire est opérationnelle, la cascade est déjà propagée.
La surprovision pour des événements rares coûte cher en temps normal. Les opérateurs optimisent pour la charge typique, acceptant les défaillances occasionnelles comme un compromis rationnel. Les coûts d’indisponibilité sont reportés sur les utilisateurs, qui subissent liquidations, transactions bloquées ou impossibilité d’accéder à leurs fonds lors de mouvements de marché critiques.
Améliorations de l’infrastructure
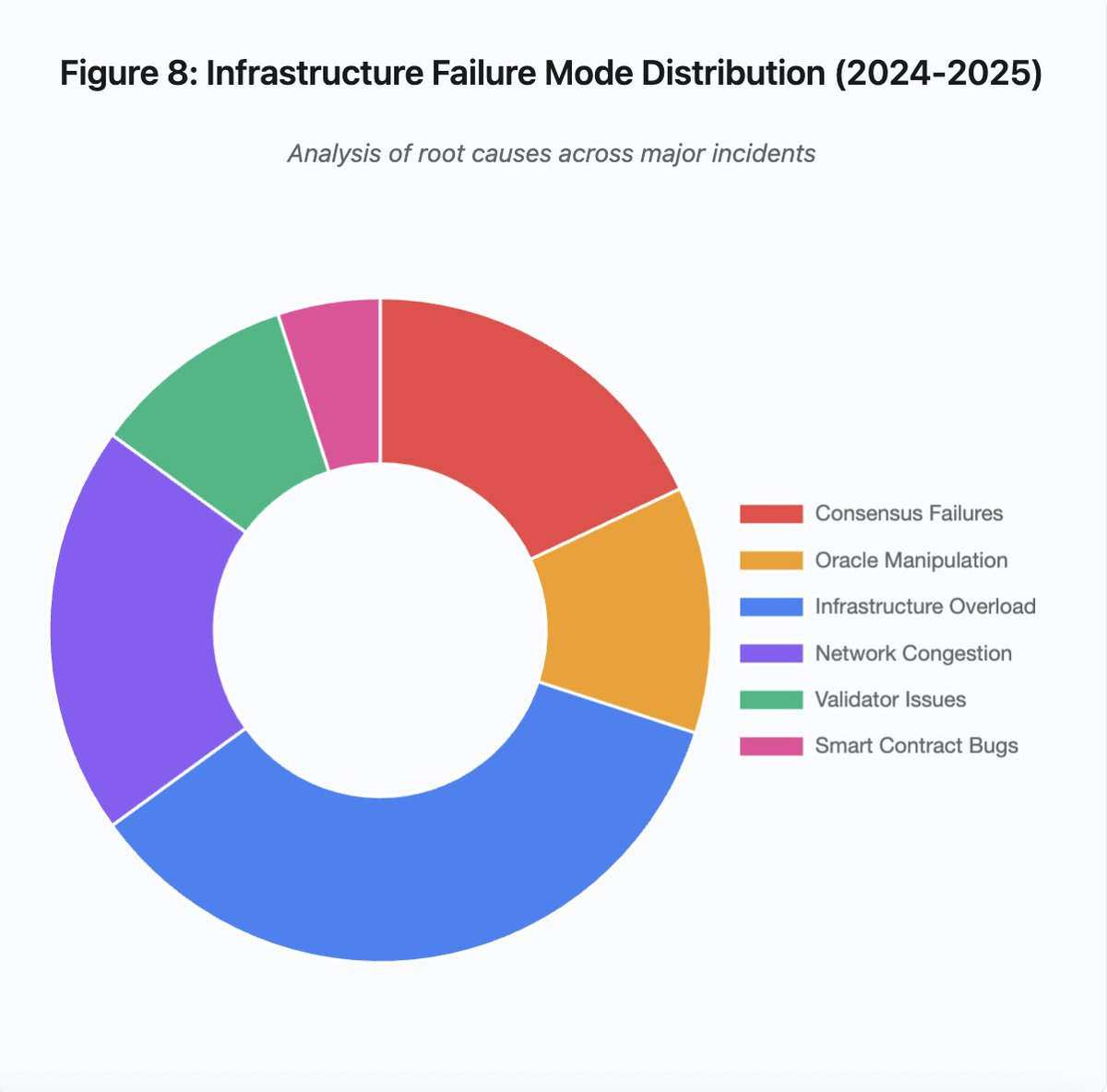
Figure 8 : Répartition des modes de défaillance infrastructurelle (2024–2025)
La répartition en camembert des causes principales révèle :
- Surcharge d’infrastructure : 35 % (la plus fréquente)
- Congestion réseau : 20 %
- Défaillances de consensus : 18 %
- Manipulation d’oracle : 12 %
- Problèmes de validateurs : 10 %
- Bugs de smart contract : 5 %
Plusieurs évolutions architecturales pourraient réduire la fréquence et la gravité des pannes, chacune impliquant des arbitrages :
1. Séparation des systèmes de tarification et de liquidation
L’incident d’octobre provient en partie du couplage du calcul de marge aux prix spot. Utiliser des ratios de conversion pour les actifs enveloppés plutôt que les prix spot aurait évité la mauvaise valorisation du wBETH. Plus généralement, les systèmes critiques de gestion du risque ne devraient pas dépendre de flux de marché manipulables. Des oracles indépendants, multi-sources et avec calcul TWAP, offrent des prix plus robustes.
2. Surprovision et infrastructure redondante
La panne AWS d’avril 2025, ayant affecté Binance, KuCoin et MEXC, a mis en avant les risques de dépendance excessive. Héberger des composants critiques sur plusieurs clouds augmente la complexité et le coût, mais élimine les défaillances corrélées. Les réseaux Layer 2 pourraient maintenir plusieurs fournisseurs RPC avec bascule automatique. Ce surcoût semble excessif en temps normal, mais évite des interruptions de plusieurs heures lors des pics de demande.
3. Renforcement des tests de résistance et planification de la capacité
Le schéma de systèmes fiables jusqu’à l’échec révèle un manque de tests de stress. Simuler une charge 100 fois supérieure à la normale devrait être une pratique standard. Identifier les goulets d’étranglement en développement coûte moins cher que les découvrir lors d’incidents réels. Cependant, les tests synthétiques ne capturent pas entièrement les comportements en production. Les utilisateurs réagissent différemment lors d’une crise réelle qu’en simulation.
Perspectives
La surprovision reste la solution la plus fiable, mais s’oppose aux logiques économiques. Maintenir une capacité 10 fois supérieure pour des événements rares coûte de l’argent chaque jour pour éviter des incidents annuels. Tant que les pannes majeures n’entraînent pas des coûts suffisants pour justifier la surprovision, les systèmes continueront de céder sous stress.
La pression réglementaire pourrait imposer des changements. Si la réglementation exige 99,9 % de disponibilité ou limite la durée d’indisponibilité, les exchanges devront surprovisionner. Mais les règles suivent généralement les catastrophes, plus qu’elles ne les préviennent. L’effondrement de Mt. Gox en 2014 a contraint le Japon à réglementer les exchanges crypto. La cascade d’octobre 2025 entraînera probablement des réponses similaires. Reste à savoir si elles cibleront des résultats (indisponibilité maximale, slippage maximal lors des liquidations) ou des moyens (oracles spécifiques, seuils de circuit breaker).
Le défi fondamental est que ces systèmes fonctionnent en continu sur des marchés mondiaux, mais reposent sur une infrastructure pensée pour des horaires de bureau. Quand le stress survient à 2h00 du matin, les équipes improvisent des correctifs tandis que les utilisateurs subissent des pertes croissantes. Les marchés traditionnels suspendent les échanges en situation de stress ; les marchés crypto s’effondrent. Selon la perspective, cela peut être perçu comme une fonctionnalité ou un défaut.
Les systèmes blockchain ont atteint une sophistication technique remarquable en peu de temps. Maintenir un consensus distribué sur des milliers de nœuds est une prouesse d’ingénierie. Mais assurer la fiabilité sous stress nécessite de passer d’architectures prototypes à des infrastructures de production. Cette transition implique des coûts et exige de privilégier la robustesse sur la rapidité d’innovation.
La difficulté réside dans le choix de la robustesse plutôt que la croissance lors des marchés haussiers, quand tous gagnent et que les interruptions semblent n’être le problème que des autres. Quand le prochain cycle testera le système, de nouvelles faiblesses apparaîtront. L’industrie retiendra-t-elle les leçons d’octobre 2025 ou répétera-t-elle les mêmes schémas ? L’histoire suggère que la prochaine vulnérabilité critique sera découverte lors d’une nouvelle défaillance de plusieurs milliards sous tension.
Analyse fondée sur les données publiques de marché et les déclarations des plateformes. Les opinions exprimées sont strictement personnelles et n’engagent aucune entité.
Avertissement :
- Cet article est une republication de [yq_acc]. Tous droits réservés à l’auteur original [yq_acc]. Pour toute objection à cette republication, veuillez contacter l’équipe Gate Learn, qui traitera la demande sans délai.
- Clause de non-responsabilité : Les opinions et points de vue exprimés dans cet article sont ceux de l’auteur uniquement et ne constituent en aucun cas un conseil en investissement.
- Les traductions de cet article dans d’autres langues sont réalisées par l’équipe Gate Learn. Sauf mention contraire, il est interdit de copier, distribuer ou plagier les versions traduites.








