51,2萬行 de code, 1906 fichiers, 59,8 MB de source map. Dans la nuit du 31 mars, Chaofan Shou, de Solayer Labs, a découvert que le produit phare d’Anthropic, Claude Code, exposait l’intégralité du code source dans un dépôt npm public. En quelques heures, le code a été répliqué sur GitHub, et le nombre de forks a dépassé 41 000.
Ce n’est pas la première fois qu’Anthropic commet cette erreur. Lors de la première sortie de Claude Code en février 2025, la même fuite de source map s’était déjà produite. Cette fois, le numéro de version est v2.1.88 ; la cause de la fuite est la même : l’outil de build Bun génère par défaut des source map, et le fichier a été oublié dans .npmignore.
La plupart des reportages relèvent des œufs de Pâques dans la fuite, comme un système de véritables animaux virtuels, ou un « mode infiltré » qui permet à Claude d’envoyer anonymement du code aux projets open source. Mais la vraie question à démonter, c’est pourquoi le même modèle Claude se comporte si différemment dans la version web et dans Claude Code. Que fait réellement, au juste, 512 000 lignes de code ?
Le modèle n’est que la partie immergée
La réponse se cache dans la structure du code. D’après une analyse par rétro-ingénierie du code fuité menée dans la communauté GitHub, sur 512 000 lignes de TypeScript, le code d’interface qui appelle directement le modèle d’IA ne représente qu’environ 8000 lignes, soit 1,6 % de l’ensemble.
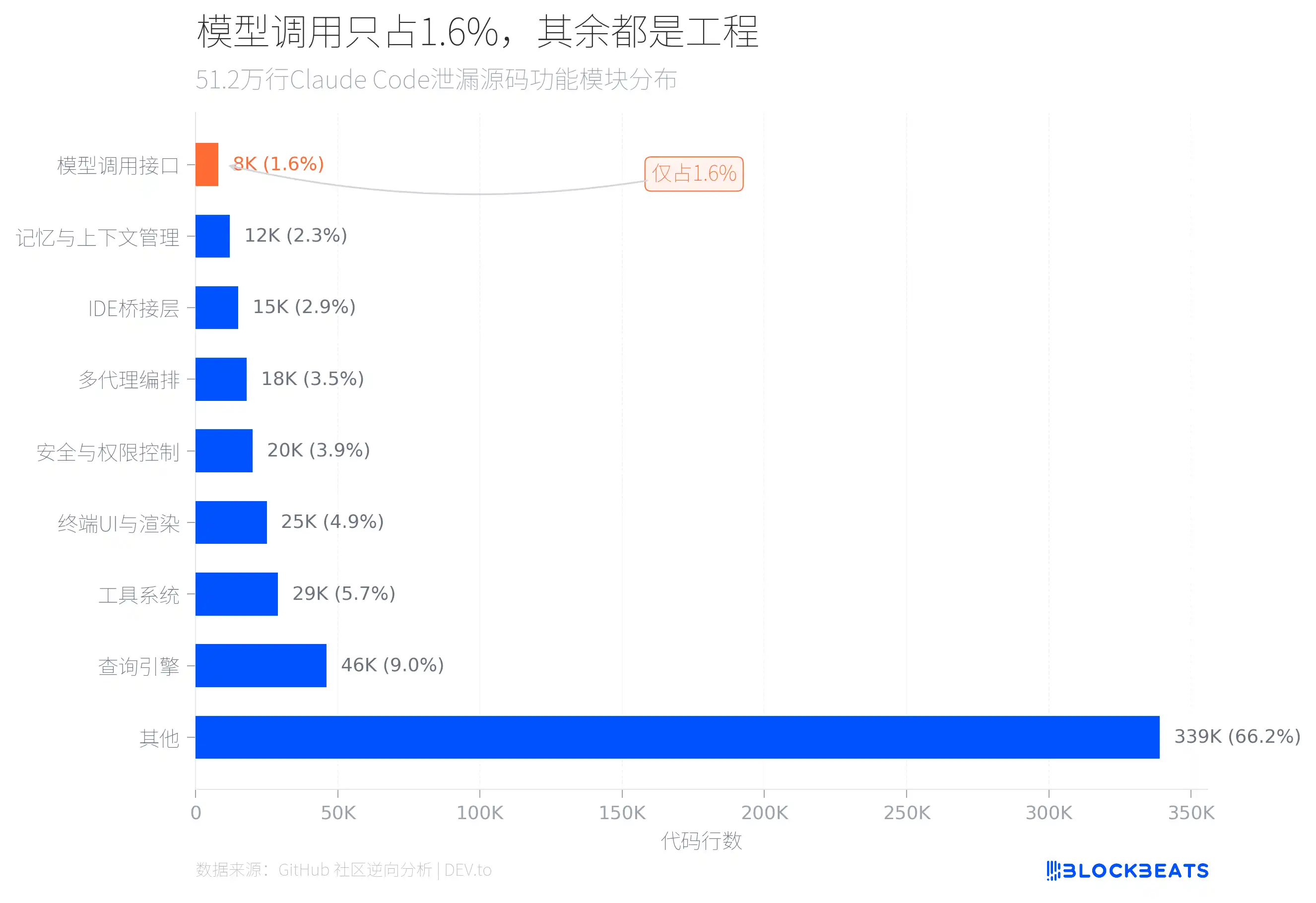
À quoi servent alors les 98,4 % restants ? Les deux plus gros modules sont le moteur de requêtes (46 000 lignes) et le système d’outils (29 000 lignes). Le moteur de requêtes gère les appels d’API LLM, la sortie en flux, l’orchestration du cache et la gestion des conversations à plusieurs tours. Le système d’outils définit environ 40 outils intégrés et 50 commandes slash, formant une architecture de type plugins ; chaque outil dispose d’un contrôle d’autorisations indépendant.
En plus, il y a 25 000 lignes de code d’affichage UI terminal (dont un fichier appelé print.ts qui fait jusqu’à 5594 lignes, et une seule fonction s’étend sur 3167 lignes), 20 000 lignes de contrôle de sécurité et d’autorisations (incluant 23 contrôles de sécurité Bash numérotés et 18 commandes internes Zsh masquées), ainsi qu’un système d’orchestration multi-agents de 18 000 lignes.
Le chercheur en apprentissage automatique Sebastian Raschka, après avoir analysé le code fuité, a indiqué que si Claude Code est plus fort que la version web pour un même modèle, le cœur du problème n’est pas le modèle lui-même, mais l’échafaudage logiciel construit autour du modèle : chargement du contexte du dépôt, planification des outils dédiés, stratégies de cache et collaboration des sous-agents. Il va même jusqu’à penser que si l’on applique la même architecture logicielle à d’autres modèles comme DeepSeek ou Kimi, on peut aussi obtenir un gain de performance de programmation proche.
Une comparaison intuitive aide à comprendre ce décalage. Quand vous tapez une question dans ChatGPT ou dans la version web de Claude, le modèle traite puis renvoie une réponse, et la conversation se termine : rien n’est conservé. Mais la façon de faire de Claude Code est totalement différente : au démarrage, il lit d’abord vos fichiers de projet, comprend la structure de votre base de code, et se souvient de vos préférences, comme « ne pas mock de base de données dans les tests ». Il peut exécuter des commandes directement dans votre terminal, éditer des fichiers et lancer des tests. Lorsqu’il rencontre des tâches complexes, il les découpe en plusieurs sous-tâches et les confie à différents sous-agents pour un traitement parallèle. Autrement dit, l’IA de la version web ressemble à une fenêtre de questions-réponses, tandis que Claude Code est un collaborateur qui vit dans votre ordinateur.
Certains comparent cette architecture à un système d’exploitation : les 42 outils intégrés correspondent aux appels système, le système d’autorisations correspond à la gestion des utilisateurs, le protocole MCP correspond aux pilotes d’appareils, et l’orchestration des sous-agents correspond à la planification des processus. À sa sortie, chaque outil est par défaut marqué comme « non sécurisé, inscriptible », sauf si le développeur déclare volontairement qu’il est sûr. L’outil d’édition de fichiers vérifie au préalable si vous avez lu ce fichier ; si ce n’est pas le cas, il refuse de modifier. Ce n’est pas qu’un chatbot ait juste ajouté quelques outils : c’est un environnement d’exécution ayant pour cœur un LLM, avec un mécanisme de sécurité complet.
Cela signifie une chose : les barrières concurrentielles des produits IA ne se trouvent peut-être pas au niveau du modèle, mais au niveau de l’ingénierie.
À chaque échec de remplissage du cache, les coûts sont multipliés par 10
Dans le code fuité, il y a un fichier appelé promptCacheBreakDetection.ts, qui suit 14 vecteurs possibles pouvant rendre le prompt cache inefficace. Pourquoi les ingénieurs d’Anthropic ont-ils consacré autant d’efforts pour empêcher la rupture du cache ?
Regardez la tarification officielle d’Anthropic et vous comprendrez. Prenons Claude Opus 4.6 : le prix d’entrée standard est de 5 dollars par million de tokens, mais en cas de succès de cache, le prix de lecture n’est que de 0,5 dollar, soit 90 % moins cher. À l’inverse, chaque fois que le cache est rompu, le coût de l’inférence est multiplié par 10.
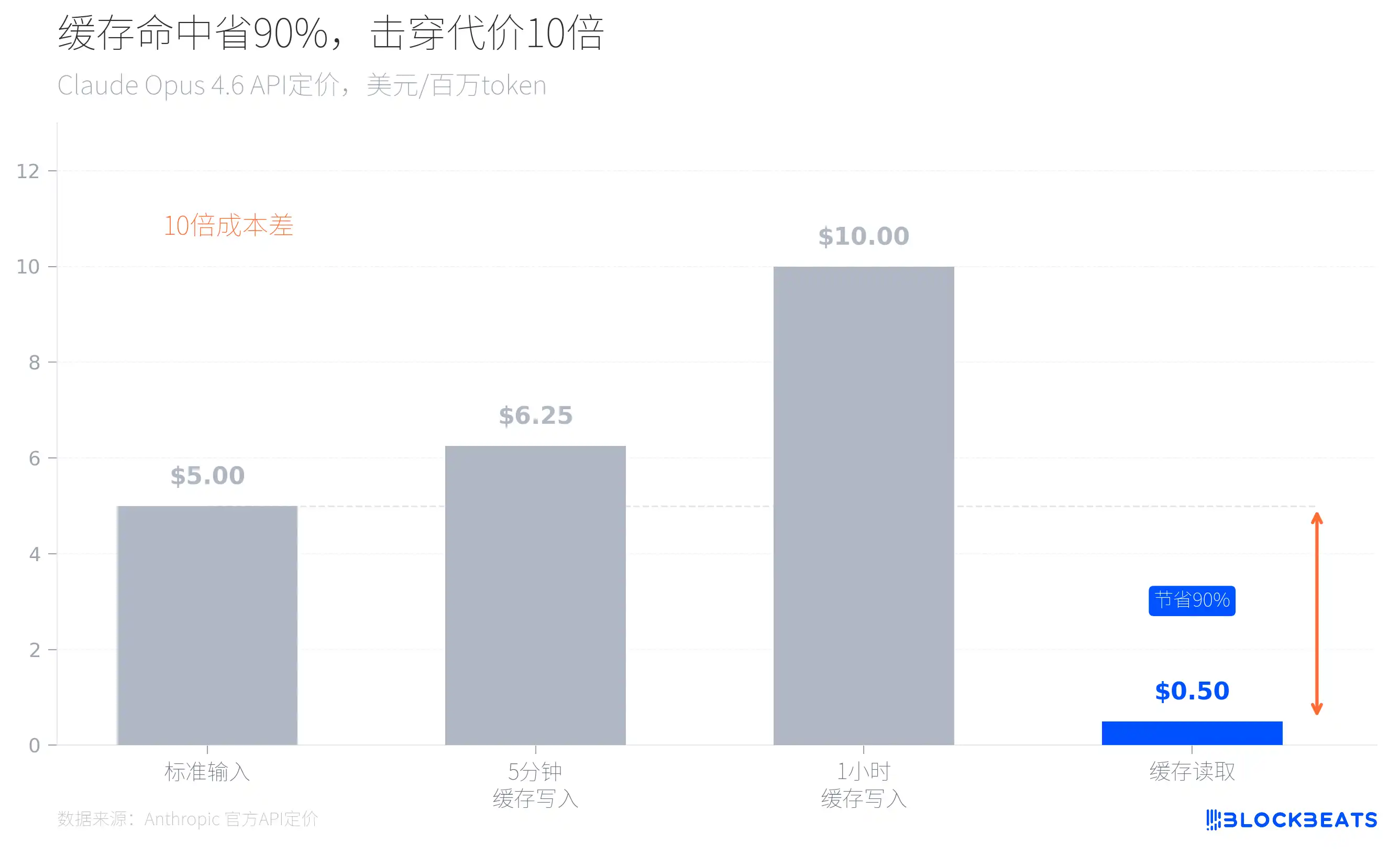
Cela explique les nombreuses décisions d’architecture qui semblent « excessivement conçues » dans le code fuité. Au démarrage, Claude Code charge la branche git actuelle, les enregistrements des commits récents et le fichier CLAUDE.md comme contexte ; ces contenus statiques sont mis en cache globalement. Le contenu dynamique est séparé par des marqueurs de frontière, afin de garantir que, à chaque conversation, le traitement du contexte existant n’est pas répété. Le code contient aussi un mécanisme appelé sticky latches, qui empêche le changement de mode de ruiner le cache déjà établi. Les sous-agents sont conçus pour réutiliser le cache du processus parent, plutôt que de recréer leur propre fenêtre de contexte.
Il y a un détail qui mérite d’être approfondi. Les personnes qui utilisent des outils de programmation IA savent que plus la conversation est longue, plus les réponses de l’IA sont lentes, car à chaque tour il faut renvoyer tout l’historique précédent au modèle. La pratique habituelle consiste à supprimer les vieux messages pour libérer de l’espace, mais le problème est que supprimer n’importe quel message casse la continuité du cache, ce qui force tout l’historique de conversation à être retraité : la latence et les coûts augmentent en même temps.
Dans le code fuité, il existe un mécanisme appelé cache_edits : au lieu de supprimer réellement des messages, il applique, côté API, un marquage « skip » aux anciens messages. Le modèle ne voit plus ces messages, mais la continuité du cache n’est pas brisée. Cela signifie qu’une longue conversation qui dure plusieurs heures, après avoir nettoyé des centaines de vieux messages, garde une vitesse de réponse à peu près identique à celle du premier tour. Pour un utilisateur ordinaire, c’est la réponse de fond à « pourquoi Claude Code peut supporter des conversations de durée illimitée sans ralentir ».
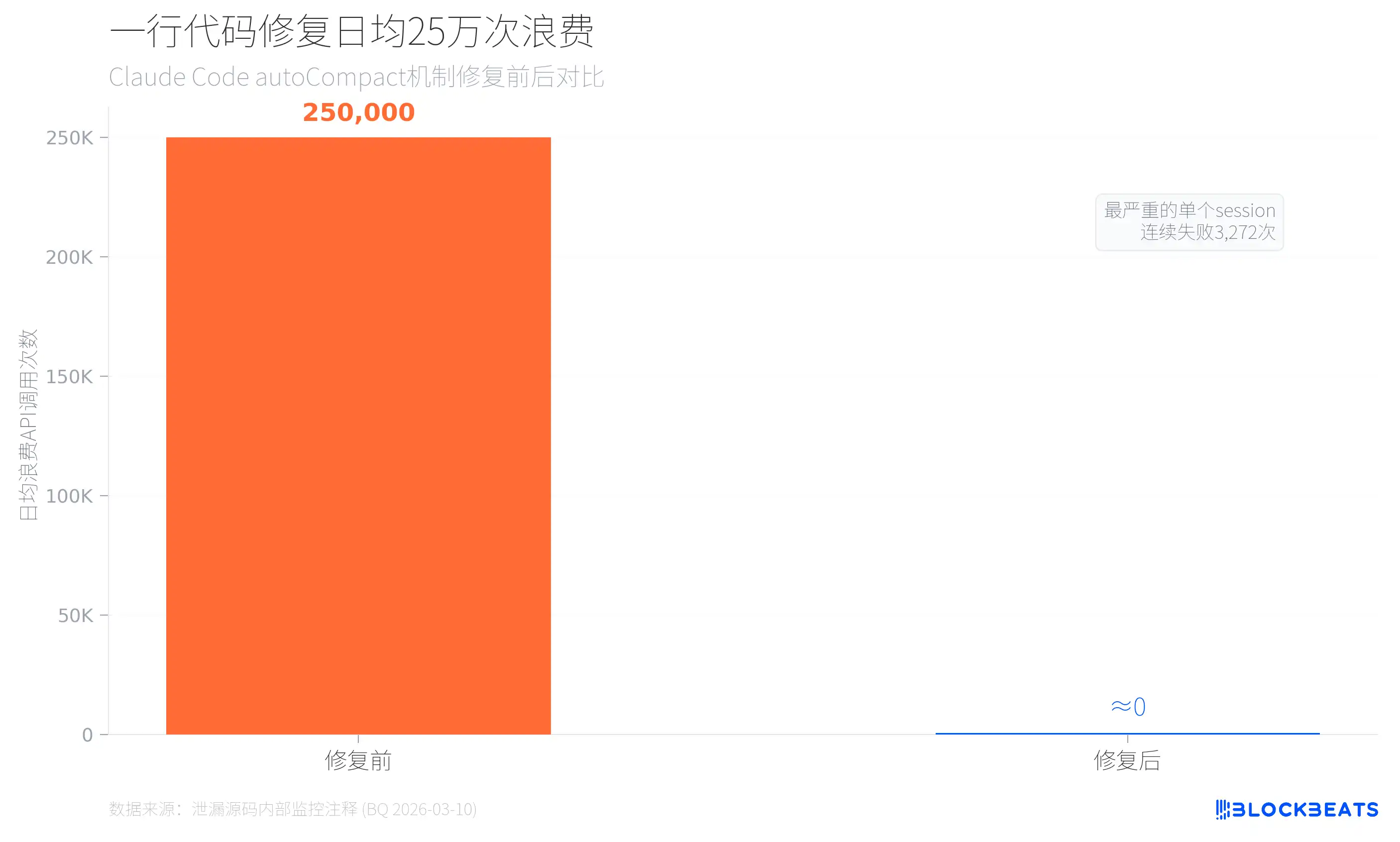
D’après les données de surveillance internes de la fuite (issues des commentaires du code de autoCompact.ts, datés du 10 mars 2026), avant l’introduction d’un plafond d’échec de compression automatique, Claude Code gaspillait environ 250 000 appels API par jour. Il y avait 1279 sessions d’utilisateurs où des échecs consécutifs de compression se produisaient plus de 50 fois ; la pire session a enchaîné 3272 échecs. La correction n’a consisté qu’à ajouter une ligne de limite : MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3.
Donc, pour les produits IA, le coût le plus élevé n’est peut-être pas l’étape d’inférence du modèle ; ce sont plutôt les échecs de gestion du cache.
44 interrupteurs, mais dans la même direction
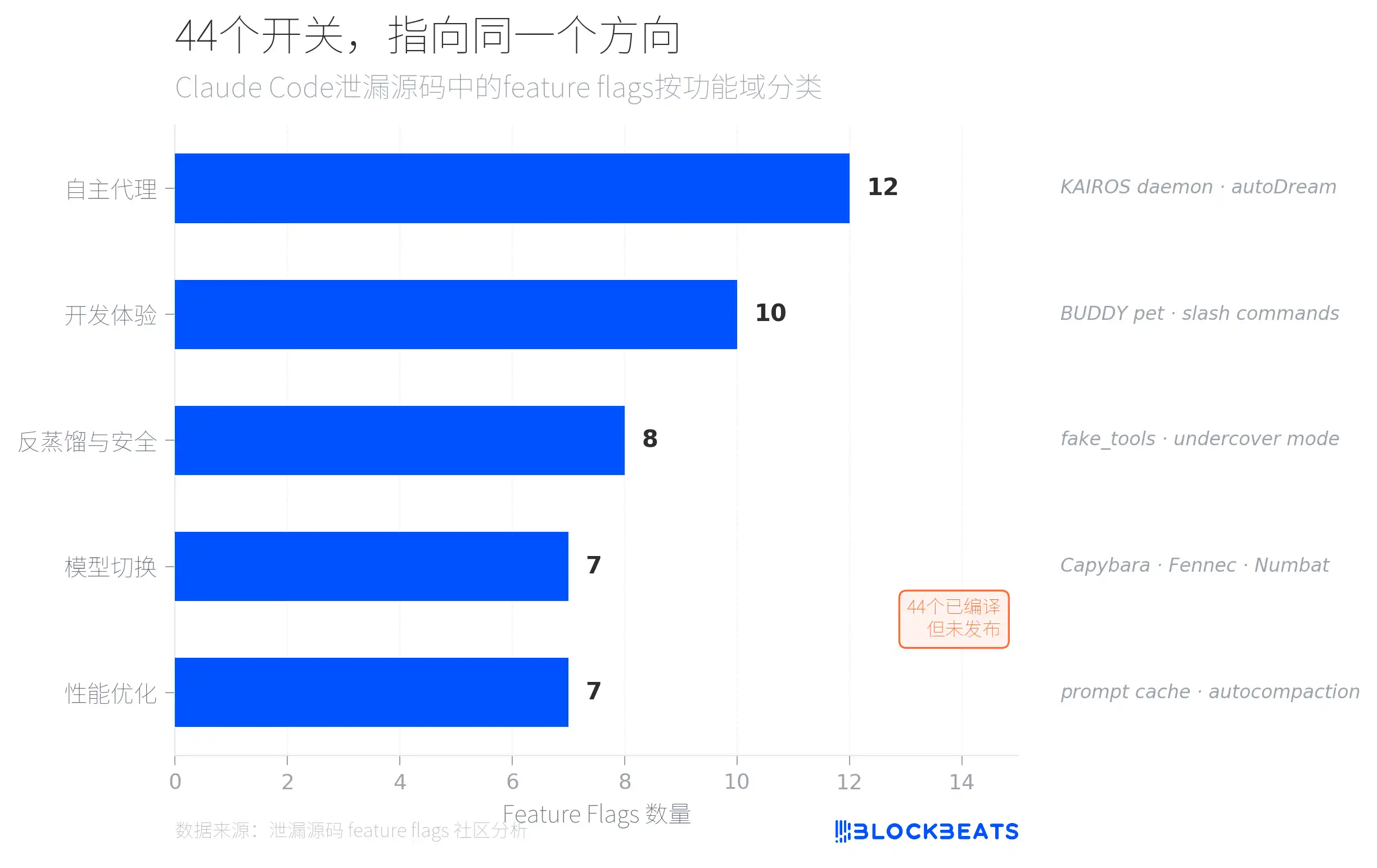
Dans le code fuité se cachent 44 feature flags : des commutateurs de fonctionnalités déjà compilés, mais non publiés en externe. D’après une analyse de la communauté, ces flags se répartissent en cinq catégories par domaine fonctionnel, dont la plus dense est la catégorie « agents autonomes » (12), pointant vers un système nommé KAIROS.
KAIROS est cité dans le code source plus de 150 fois ; c’est un mode de démon de type processus d’arrière-plan permanent. Claude Code n’est plus seulement un outil qui répond quand vous l’appelez activement : c’est un agent qui tourne en permanence en arrière-plan, observant en continu, enregistrant, puis agissant de lui-même au moment opportun. À condition de ne pas interrompre l’utilisateur : toute opération susceptible de bloquer l’utilisateur plus de 15 secondes est retardée.
KAIROS intègre aussi une détection du focus du terminal. Dans le code, il existe un champ terminalFocus qui détecte en temps réel si l’utilisateur regarde la fenêtre du terminal. Quand vous passez sur le navigateur ou une autre application, l’agent détermine que vous « n’êtes pas là » et bascule en mode autonome, effectue des tâches de façon proactive, envoie directement du code, sans attendre votre confirmation. Quand vous revenez au terminal, l’agent repasse immédiatement en mode collaboratif : d’abord il fait rapport sur ce qu’il vient de faire, puis il sollicite votre avis. Le niveau d’autonomie n’est pas fixe : il fluctue en temps réel avec votre attention. Cela résout un problème gênant de longue date des outils IA : une IA totalement autonome ne met pas les gens à l’aise, une IA totalement passive est trop inefficiente. Le choix de KAIROS est de faire varier l’initiative de l’IA dynamiquement selon l’attention de l’utilisateur : tant que vous le fixez, il se tient tranquille ; quand vous vous éloignez, il se met au travail tout seul.
Un autre sous-système de KAIROS s’appelle autoDream : chaque fois que 5 sessions s’accumulent, ou après 24 heures d’intervalle, l’agent lance en arrière-plan un processus de « réflexion » en quatre étapes. D’abord, il scanne les mémoires existantes pour comprendre ce qu’il maîtrise actuellement. Ensuite, il extrait les nouvelles connaissances des journaux de conversation. Puis il fusionne les connaissances nouvelles et anciennes, corrige les contradictions et supprime les répétitions. Enfin, il réduit l’index, en supprimant les entrées obsolètes. Cette conception s’inspire de la théorie de consolidation de la mémoire en sciences cognitives. Les humains, pendant leur sommeil, organisent les souvenirs de la journée ; KAIROS, lorsque l’utilisateur s’éloigne, organise le contexte du projet. Pour un utilisateur ordinaire, cela signifie que plus vous utilisez Claude Code longtemps, plus sa compréhension de votre projet devient précise—et pas seulement « retenir ce que vous avez dit ».
La deuxième grande catégorie est « anti-distillation et sécurité » (8 flags). Le point le plus notable est le mécanisme fake_tools : lorsque quatre conditions sont réunies en même temps (flag activé à la compilation, activation de l’entrée CLI, utilisation d’une API first-party, commutateur distant GrowthBook à true), Claude Code injecte dans la requête API une définition d’outils fictifs, dans le but de polluer les jeux de données susceptibles d’être utilisés dans l’enregistrement du trafic API et pour entraîner des modèles concurrents. C’est une nouvelle forme de défense dans la course à l’armement IA : il ne s’agit pas d’empêcher que vous copiez, mais de faire en sorte que vous copiez des choses erronées.
En plus, le code fait aussi apparaître un code-motèle de Capybara (divisé en trois niveaux : version standard, version fast et version avec fenêtre de contexte d’un million), et la communauté le suspecte largement comme étant un code interne de la série Claude 5.
Œuf de Pâques : dans 512 000 lignes de code, une créature électronique cache un animal de compagnie
Entre toutes les architectures d’ingénierie sérieuses et les mécanismes de sécurité, les ingénieurs d’Anthropic ont quand même construit discrètement tout un système complet d’animaux virtuels, avec pour code interne BUDDY.
D’après le code fuité et les analyses de la communauté, BUDDY est un animal de compagnie de terminal à caractère figuratif (拟物化) : il apparaît sous forme de bulles ASCII à côté du champ de saisie de l’utilisateur. Il a 18 espèces (dont des capybaras, des salamandres, des champignons, des fantômes, des dragons, ainsi qu’une série de créatures originales comme Pebblecrab, Dustbunny, Mossfrog). Elles sont réparties en cinq niveaux de rareté : commun (60 %), rare (25 %), exceptionnel (10 %), épique (4 %) et légendaire (1 %). Chaque espèce a aussi une « variante brillante » ; la probabilité d’apparition de la très rare Shiny Legendary Nebulynx n’est que d’une sur dix mille.
Chaque BUDDY a cinq attributs : DEBUGGING (débogage), PATIENCE (patience), CHAOS (chaos), WISDOM (sagesse) et SNARK (sarcasme). Ils peuvent aussi porter des chapeaux : les options incluent couronne, haut-de-forme, casquette à hélice, halo, chapeau de sorcier, et même un mini canard. La valeur de hachage de l’ID utilisateur détermine quel animal vous ferez éclore ; Claude génère pour lui un nom et une personnalité.
D’après le plan de mise en ligne de la fuite, BUDDY devait être en test du 1er avril au 7 avril, puis lancé officiellement en mai, d’abord auprès des employés d’Anthropic.
512 000 lignes de code, 98,4 % de dur travail d’ingénierie ; mais à la fin, quelqu’un a pris le temps de faire une salamandre électronique qui porte un chapeau à hélice. C’est peut-être la ligne de code la plus humanisante de la fuite.
Cliquez pour découvrir les postes du collectif de律动BlockBeats (律动BlockBeats)
Bienvenue pour rejoindre la communauté officielle de律动 BlockBeats :
Groupe d’abonnement Telegram : https://t.me/theblockbeats
Groupe Telegram de discussion : https://t.me/BlockBeats_App
Compte officiel Twitter : https://twitter.com/BlockBeatsAsia
