
Penulis: Phosphen
Kompilasi; Gans 甘斯, Bagel Prediksi Pasar Pengamatan
Pria ini mengumpulkan data semua pertandingan tenis profesional selama 43 tahun terakhir, memasukkannya ke dalam model pembelajaran mesin, lalu hanya menanyakan satu pertanyaan: bisakah kamu memprediksi siapa yang akan menang?
Model hanya menjawab satu kata: Bisa.
Selanjutnya, pada Australia Terbuka tahun ini, ia memprediksi 99 dari 116 pertandingan dengan akurasi hingga 85%!
Ini adalah pertandingan yang belum pernah dilihat selama pelatihan model, tetapi ia bahkan mampu memprediksi setiap pertandingan final, termasuk pemenang utamanya.

Semua ini hanya menggunakan satu laptop, data gratis, dan kode sumber terbuka, karya @theGreenCoding.
Selanjutnya, saya akan menguraikan lengkap proyek yang seperti menabur emas ini, dari data mentah hingga prediksi akhir yang sukses. Ini akan menjadi salah satu contoh keberhasilan AI + prediksi paling mengesankan yang pernah Anda lihat.
Titik Awal: Data tenis selama 43 tahun dalam satu folder
Kisah ini dimulai dari sebuah dataset yang disebut sebagai “Cawan Suci Data Olahraga”.
Dataset ini mencakup catatan setiap pertandingan profesional ATP (Asosiasi Tenis Profesional) dari 1985 hingga 2024.
Break point, double fault, forehand, backhand, tinggi badan pemain, usia, peringkat, catatan pertemuan sebelumnya, lokasi pertandingan… Semua statistik setiap poin yang pernah dilacak ATP ada di sana.
Empat puluh tahun data CSV, semuanya tersimpan dalam satu folder.
Ketika dia membuka dataset lengkap itu, komputer langsung crash.
Namun dia tidak menyerah. Untuk 95.491 pertandingan dalam dataset, dia menghitung banyak fitur turunan tambahan:
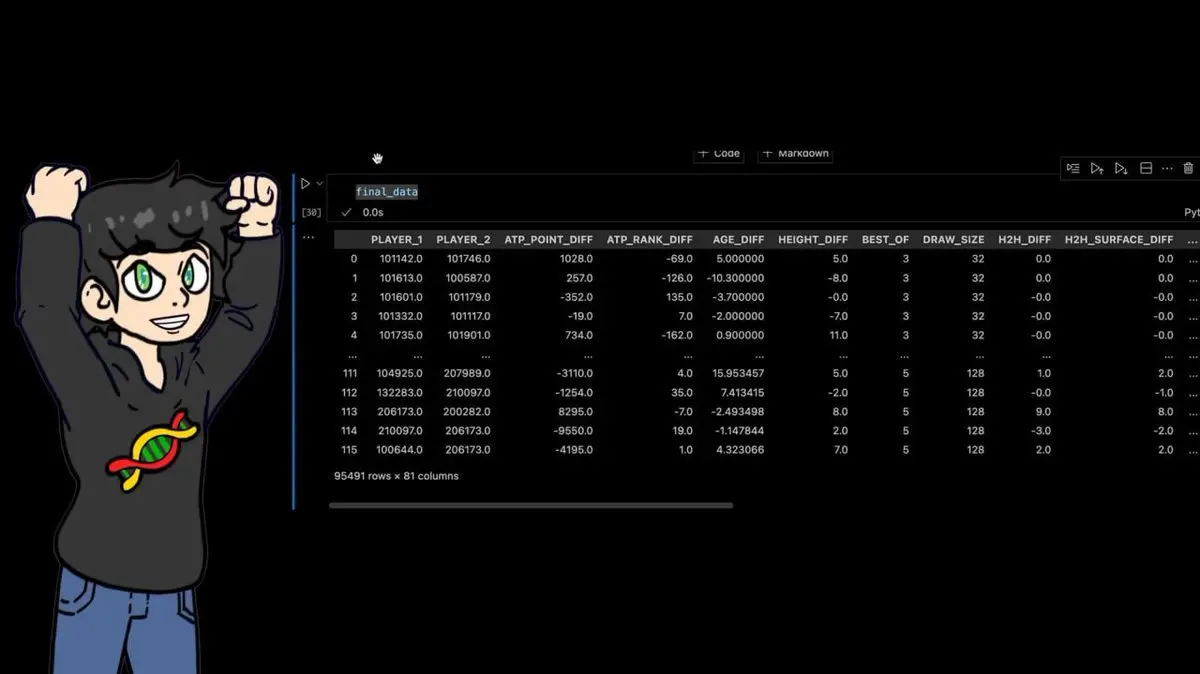
- Catatan pertemuan sebelumnya antara kedua pemain
- Selisih usia, selisih tinggi badan
- Persentase kemenangan dari 10, 25, 50, 100 pertandingan terakhir
- Selisih tingkat keberhasilan servis pertama
- Selisih tingkat penyelamatan break point
- Sistem penilaian ELO kustom yang diadaptasi dari catur (kunci utama)
Akhirnya, dataset: 95.491 baris × 81 kolom.
Setiap pertandingan profesional selama 40 tahun, lengkap dengan puluhan fitur yang dihitung secara manual.
Langkah kedua: Mengadopsi algoritma dari Titanic

Sebelum memasukkan data ke dalam classifier, dia memutuskan untuk memahami sepenuhnya cara kerja algoritma tersebut. Untuk itu, dia menulis decision tree dari nol menggunakan numpy.
Cara kerja decision tree mirip permainan tebak-tebakan — melalui serangkaian pertanyaan secara berurutan mendekati jawaban.
Untuk menjelaskan konsep ini, dia memilih dataset yang sangat berbeda: Titanic.
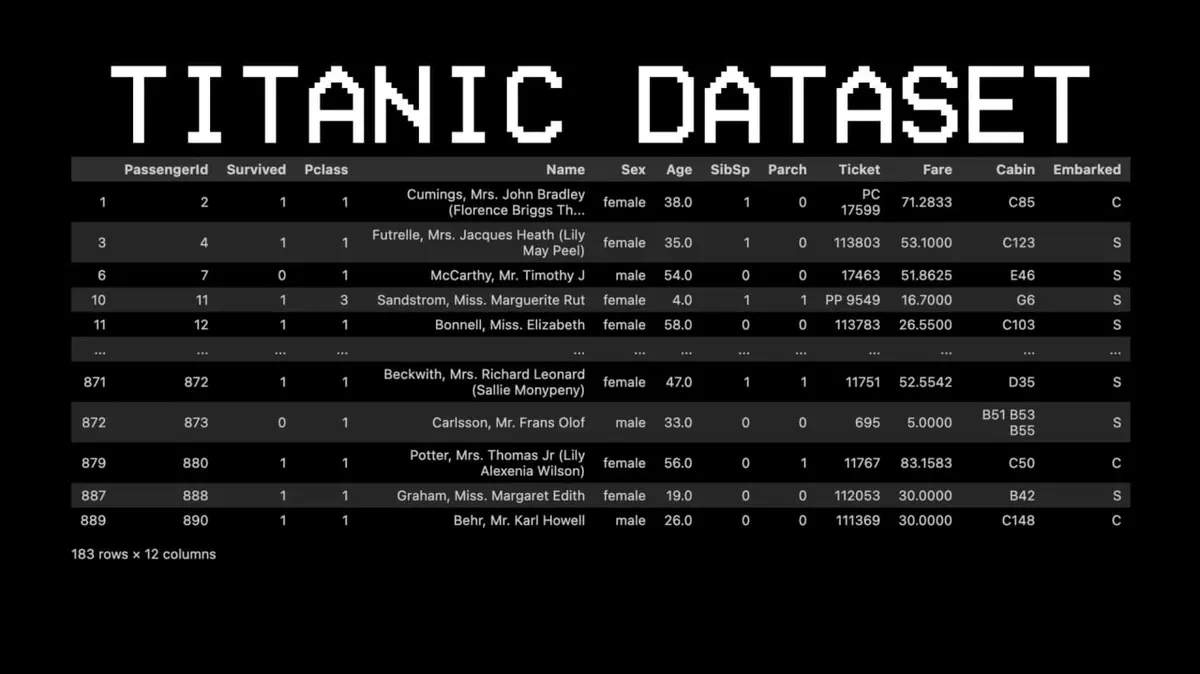
Contohnya: Apakah penumpang nomor 11 selamat?
- Pertanyaan pertama: Apakah dia di kelas satu? → Ya.
- Pertanyaan kedua: Apakah dia perempuan? → Ya.
- Prediksi: Selamat.
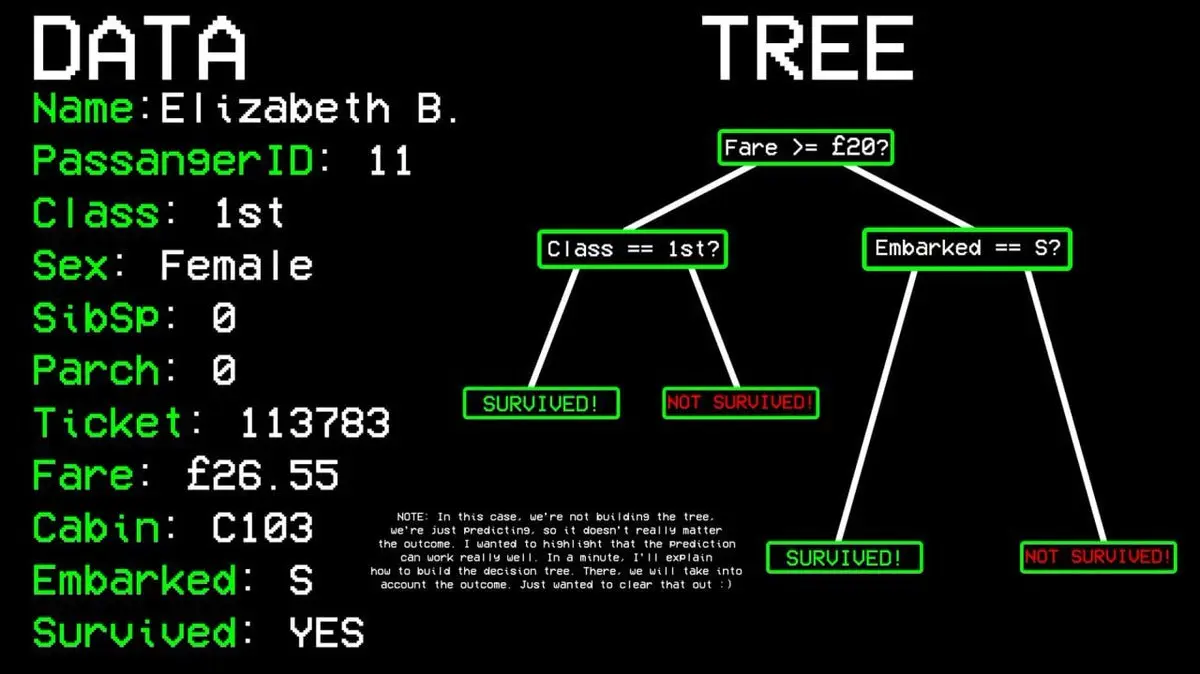
Bagaimana algoritma memutuskan pertanyaan apa yang harus diajukan?
Dimulai dari semua data, ia mencari variabel tunggal yang paling mampu membedakan antara “selamat” dan “tidak selamat”. Dalam data Titanic, jawabannya adalah kelas penumpang. Penumpang kelas satu di satu sisi, yang lain di sisi lain.
Namun, ada juga penumpang kelas satu yang meninggal, sehingga data tidak murni. Algoritma terus mencari split terbaik berikutnya, yaitu jenis kelamin. Semua perempuan di kelas satu selamat, membentuk “node murni”, dan cabang berhenti di situ.
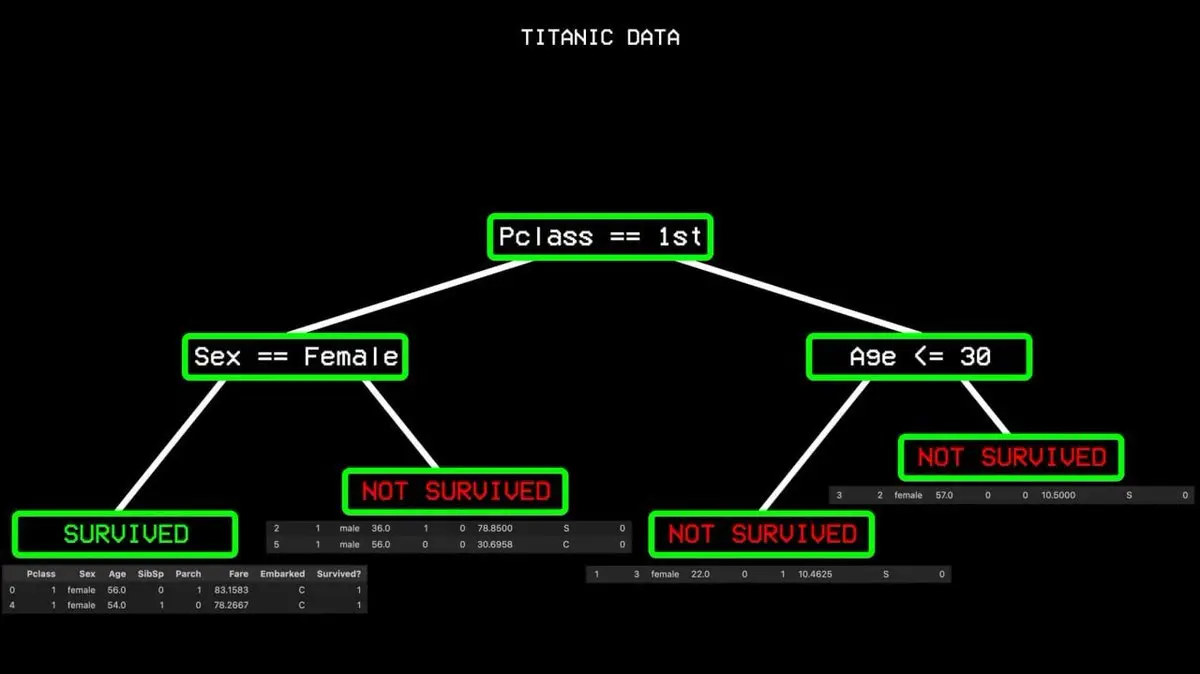
Proses ini diulang terus hingga membangun pohon keputusan lengkap yang mencakup semua kemungkinan.
Versi numpy buatannya bekerja baik pada dataset kecil, tetapi saat diterapkan ke 95.000 pertandingan tenis, kecepatannya sangat lambat. Maka, selama pelatihan resmi, dia beralih ke versi yang dioptimalkan dari sklearn, dengan logika yang sama tetapi jauh lebih cepat.
Langkah ketiga: Menemukan variabel kunci yang menentukan kemenangan
Sebelum melatih model, dia memplot semua variabel secara berpasangan dalam sebuah matriks scatter besar (SNS pairplot), mencari pola yang mampu membedakan pemenang dan pecundang.

Sebagian besar fitur hanyalah noise. ID pemain jelas tidak berguna. Selisih kemenangan menunjukkan beberapa pola, tetapi tidak cukup jelas untuk mendukung classifier yang andal.
Hanya satu variabel yang jauh melampaui yang lain: ELO_DIFF (selisih skor ELO).
Scatter plot ELO_DIFF dan ELO_SURFACE_DIFF menunjukkan pemisahan yang sangat jelas antara dua kategori, tidak ada fitur lain yang mendekati kekuatannya.
Temuan ini menjadi inti dari bagian terpenting proyek ini.
Langkah keempat: Mengadopsi sistem penilaian catur ke tenis
ELO adalah sistem penilaian yang digunakan untuk mengukur tingkat keahlian pemain, pertama kali diterapkan di catur. Saat ini, peringkat dunia Magnus Carlsen adalah 2833.

Dia memutuskan untuk menerapkan sistem ini ke tenis:
- Setiap pemain mulai dari skor 1500
- Menang: skor naik; kalah: skor turun
Inti mekanismenya: jumlah poin yang diperoleh tergantung pada selisih skor dengan lawan. Mengalahkan pemain dengan skor lebih tinggi memberi poin lebih banyak, kalah dari pemain dengan skor lebih rendah mengurangi poin lebih banyak.
Dia menggunakan formula ini untuk final Wimbledon 2023: Carlos Alcaraz (2063) melawan Novak Djokovic (2120), Alcaraz melakukan kebalikan dan memenangkan turnamen.

Masukkan angka ke dalam formula: Alcaraz +14 poin, Djokovic -14 poin.
Meskipun sederhana, saat diterapkan ke data 43 tahun, kekuatannya luar biasa.
Langkah kelima: Visualisasi kekuatan dominasi tiga legenda
Dia menggambar kurva skor ELO Federer dari awal karier hingga pensiun, setiap pertandingan tercatat secara lengkap.
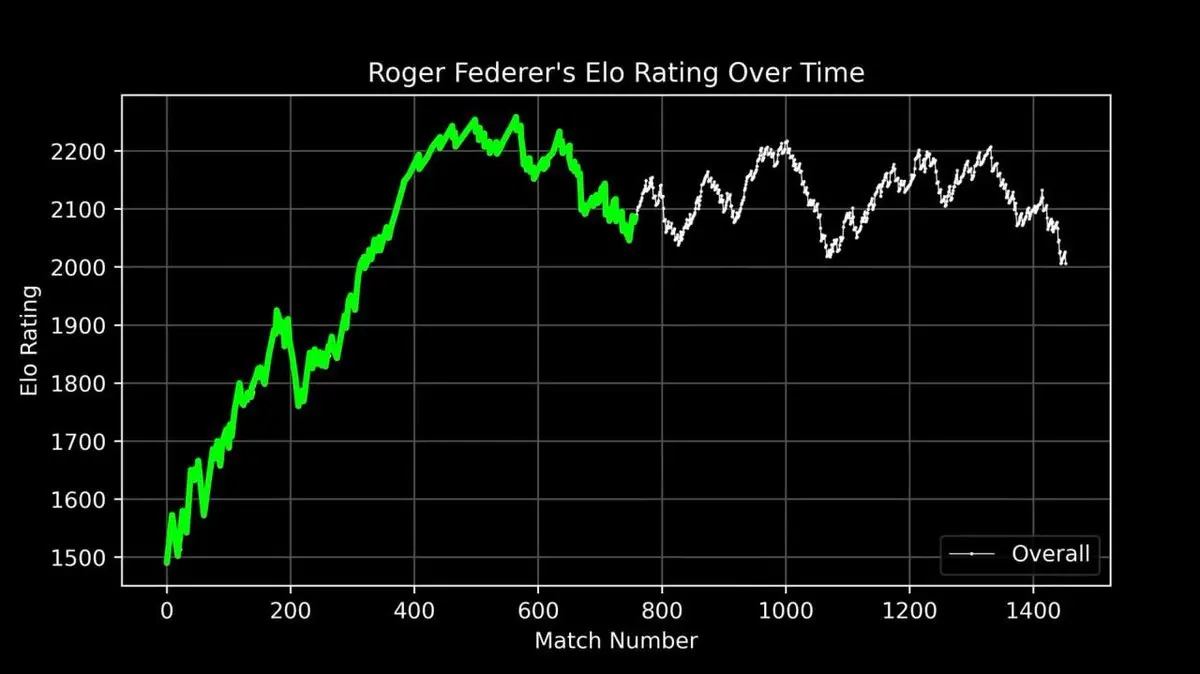
Kurva ini menampilkan kisah legendaris: kenaikan cepat di awal, masa puncak (sekitar 400 pertandingan), dominasi mutlak, dan fluktuasi di akhir karier.
Namun yang benar-benar mengagetkan adalah saat dia menempatkan Federer bersama semua pemain ATP sejak 1985 dalam satu grafik:
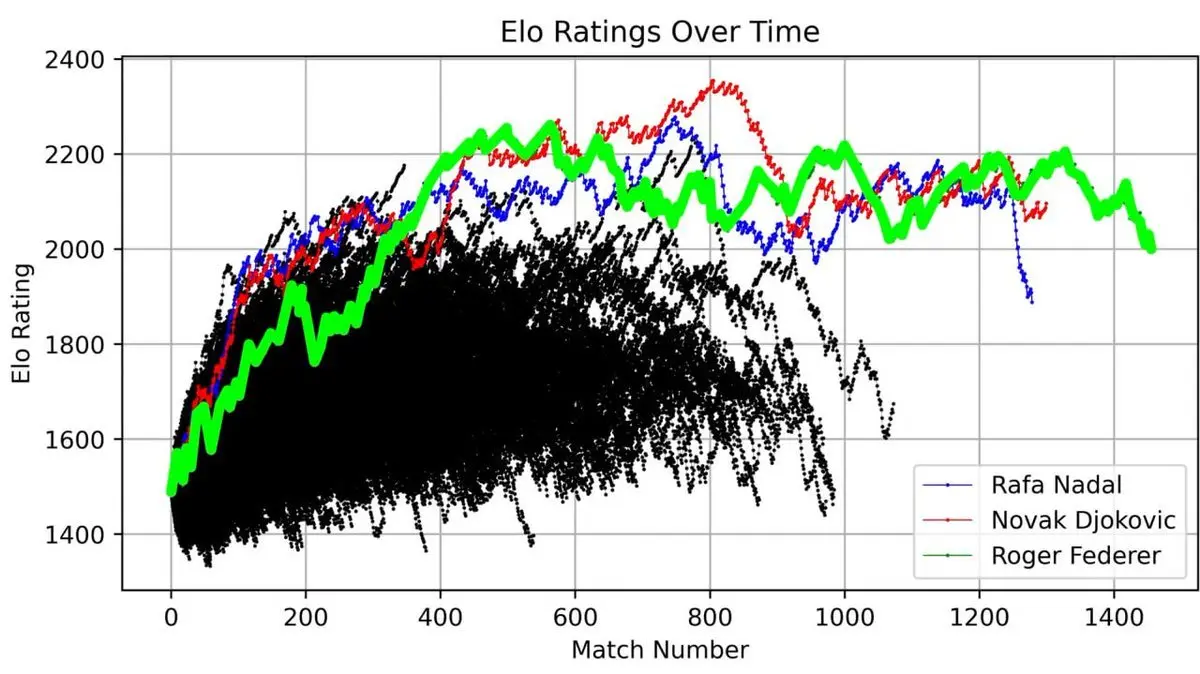
Tiga garis melambung tinggi, jauh di atas yang lain — Federer (hijau), Nadal (biru), Djokovic (merah).
“Trio Grand Slam” bukan sekadar julukan. Setelah memvisualisasikan data 40 tahun pertandingan, dominasi ini secara matematis sangat jelas.
Berdasarkan sistem ELO kustom ini, peringkat dunia saat ini adalah Jannik Sinner (2176), diikuti Djokovic (2096), dan Alcaraz (2003).

Ingat, peringkat pertama Sinner ini sangat penting untuk nanti.
Langkah keenam: Venue sebagai variabel pengubah segalanya
Jenis lapangan tenis benar-benar mengubah wajah olahraga ini:
- Tanah merah: lambat, bounce tinggi
- Rumput: cepat, bounce rendah
- Hard court: di tengah-tengah
Pemain yang unggul di satu jenis lapangan bisa jadi kalah di lapangan lain.
Oleh karena itu, dia membangun skor ELO terpisah untuk ketiga jenis lapangan: tanah merah, rumput, hard court.
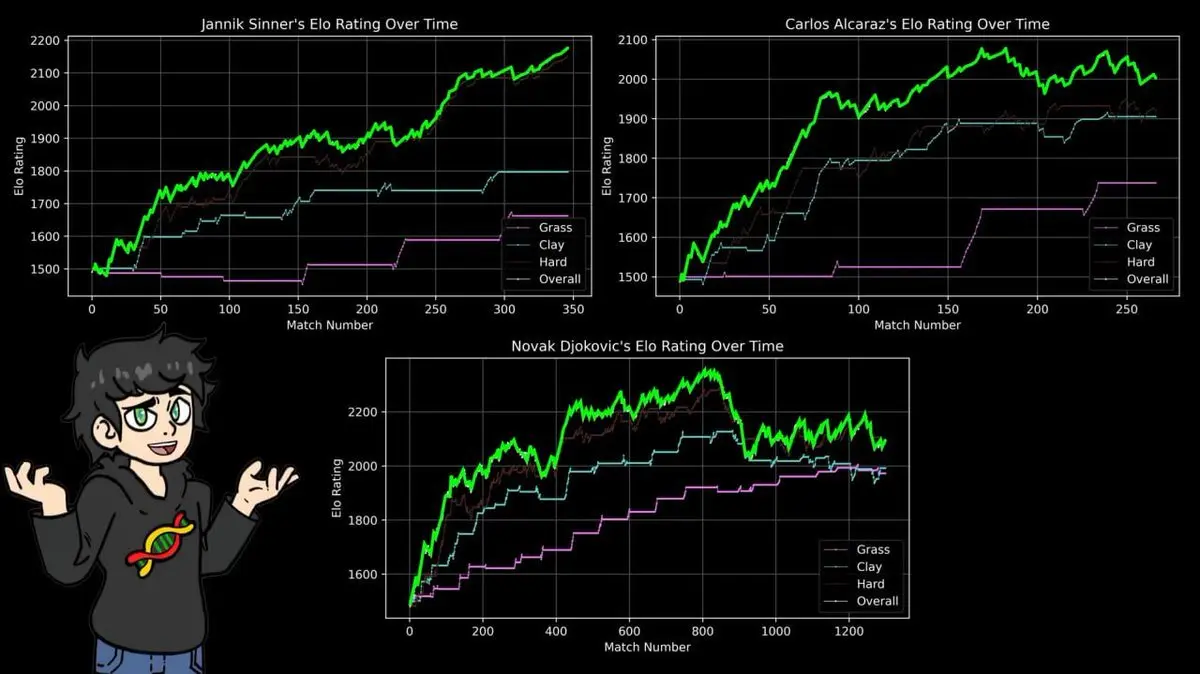
Hasilnya mengonfirmasi fakta yang sudah diketahui penggemar tenis, dan didukung data 43 tahun:
Skor tertinggi Nadal di tanah merah melebihi skor tertinggi Federer di rumput, dan skor tertinggi Djokovic di hard court, serta rekor tertinggi di semua lapangan.
14 gelar Roland Garros, 112 kemenangan dan 4 kekalahan.
Formula ELO tidak peduli narasi, tidak peduli ketenaran, ia hanya memproses catatan kemenangan dan kekalahan. Kesimpulannya sama persis dengan laporan olahraga selama 40 tahun.
Langkah ketujuh: Menemui batas
Data sudah disiapkan, sistem ELO sudah dibangun, dia mulai melatih classifier. Proses ini menunjukkan pentingnya pemilihan algoritma.
Decision tree: akurasi 74%
Satu decision tree pada dataset lengkap mencapai 74% akurasi. Kedengarannya bagus — sampai Anda tahu bahwa hanya dengan prediksi selisih ELO, Anda sudah bisa mencapai 72%.
Decision tree yang dia buat secara manual di atas skor ELO hampir tidak menambah apa-apa.
Random forest: akurasi 76%
Masalah decision tree tunggal adalah “tinggi varians” — sangat sensitif terhadap subset data saat pelatihan. Solusinya adalah random forest: membangun puluhan bahkan ratusan decision tree, masing-masing dengan subset data dan fitur yang berbeda, lalu voting mayoritas.

94 decision tree berbeda bekerja sama untuk memvote setiap pertandingan.

Hasilnya 76%. Ada peningkatan, tetapi batasnya sudah tercapai. Apapun hyperparameter yang diubah, fitur yang ditambahkan, data yang diolah, akurasi tidak pernah melewati 77%.
Langkah kedelapan: Melampaui batas
Kemudian dia mencoba XGBoost — yang dia sebut sebagai “versi steroid dari random forest”.
Perbedaannya: random forest membangun pohon secara paralel dan rata-rata hasilnya, sedangkan XGBoost membangun pohon secara berurutan — setiap pohon baru memperbaiki kesalahan dari semua pohon sebelumnya. Ia juga menambahkan regularisasi untuk mencegah overfitting, dan menjaga pohon tetap kecil agar tidak menghafal data.
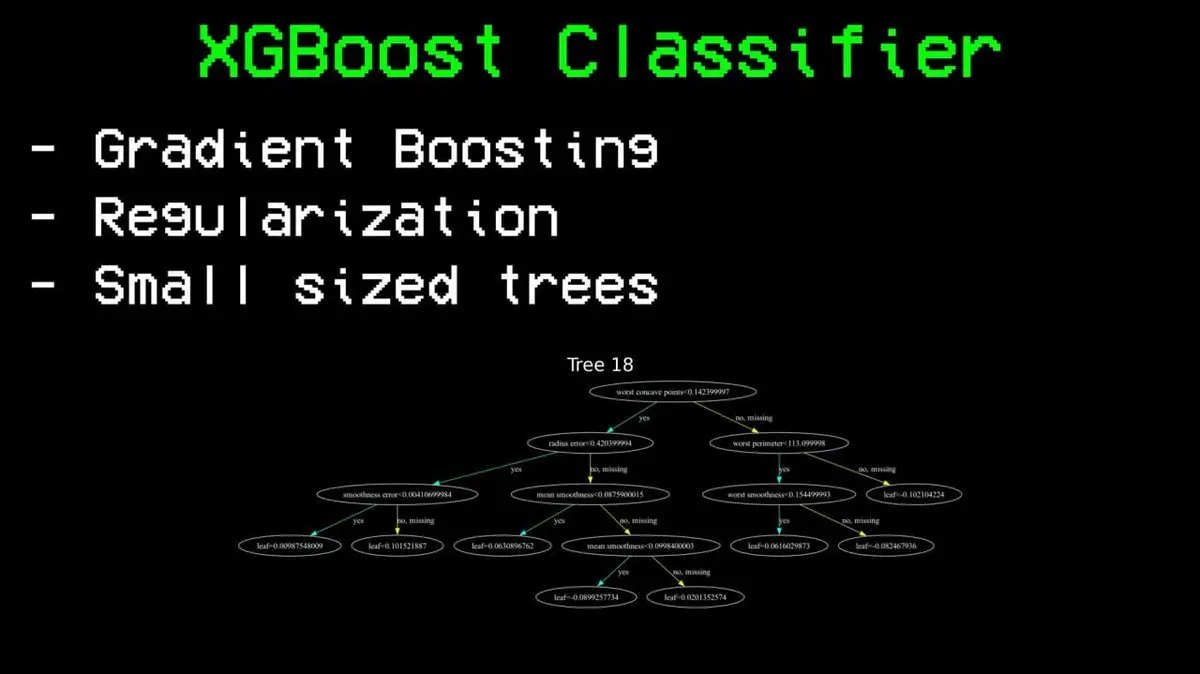
Hasilnya: akurasi 85%.
Dibandingkan batas 76% dari random forest, ini adalah loncatan besar. Dengan data yang sama dan fitur yang sama, satu-satunya yang berbeda adalah algoritma.
XGBoost juga menganggap tiga fitur terpenting sebagai: selisih ELO, selisih ELO khusus lapangan, dan skor ELO keseluruhan. Sistem penilaian dari catur ini terbukti sebagai faktor prediksi terkuat dari 81 fitur.
Sebagai pembanding, dia melatih neural network dengan data yang sama dan mendapatkan akurasi 83%. Lumayan, tetapi kalah dari XGBoost. Pada dataset ini, metode berbasis pohon lebih unggul.
Langkah kesembilan: Pertarungan puncak — Australia Terbuka 2025
Semua yang disebutkan di atas didasarkan pada data hingga Desember 2024.
Australia Terbuka 2025 yang berlangsung Januari 2025 sama sekali tidak ada dalam data pelatihan, menjadikannya sebagai ujian sempurna: apakah model benar-benar memahami pola tenis, atau hanya menghafal pola masa lalu?

Dia memasukkan seluruh jadwal pertandingan ke model, lalu membiarkannya memprediksi setiap pertandingan.
Hasilnya: dari 116 pertandingan, 99 diprediksi dengan benar, hanya 17 yang salah. Akurasi 85,3%.
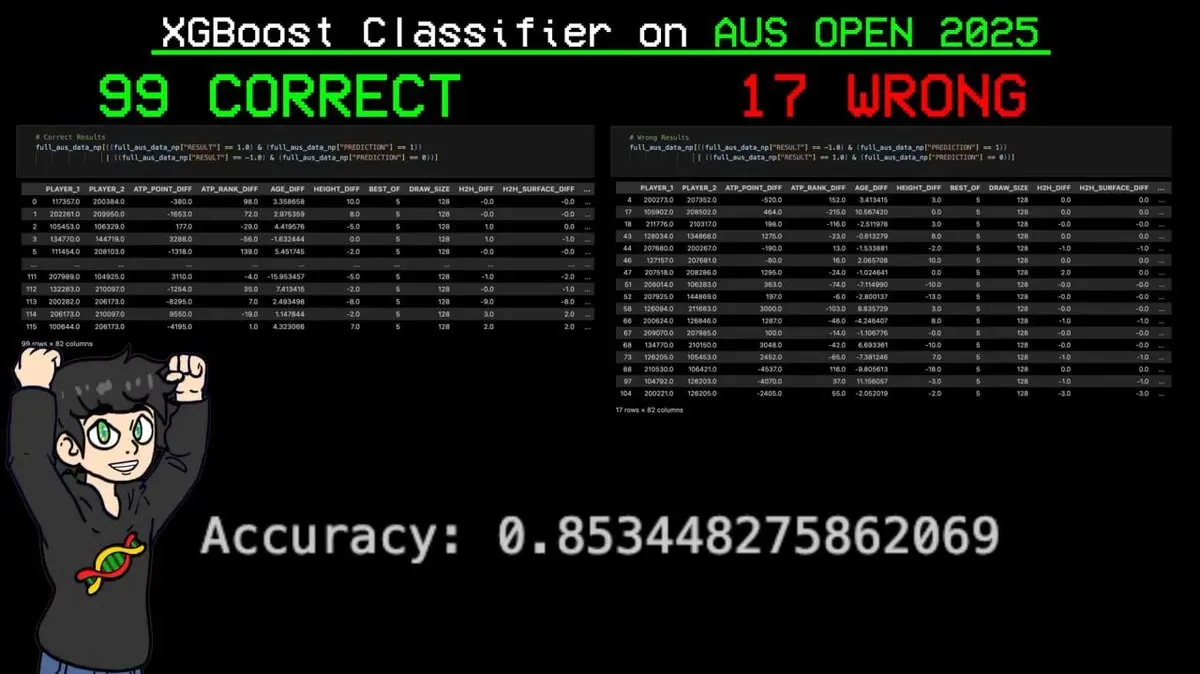
Prediksi terpenting: model secara akurat memprediksi kemenangan Sinner di seluruh turnamen, termasuk juara utama.
Sebelum bola pertama dipukul, AI sudah memprediksi juara grand slam.
Penutup
Seorang diri, satu laptop, tanpa data proprietary, tanpa infrastruktur mahal, tanpa tim riset — dia membangun model prediksi tenis profesional dengan akurasi 85%, dan sudah memprediksi juara utama sebelum turnamen dimulai.
Data tenis tersedia di GitHub, bisa direproduksi sepenuhnya.
Menciptakan keajaiban belum pernah semudah hari ini.
Perbedaan nyata bukan di sumber daya, tetapi di apakah Anda mau berusaha.