現在のブロックチェーン業界では、データに関する課題が主要なボトルネックの一つとなっています。従来型データベースは効率性に優れるものの、信頼性や検証性が不足しています。一方で、ブロックチェーンは本質的に信頼性が高いですが、複雑なデータ構造の保存には向いていません。ここでDKGが登場し、グラフ構造・分散型ネットワーク・ブロックチェーンアンカリングを組み合わせることで、データの信頼性と可用性のバランスを実現し、両者のギャップを埋めます。
デジタル資産やAIの観点から見ると、OriginTrailの価値は、単なるストレージネットワークにとどまらず、「ナレッジレイヤー」としてAIやDeFi、エンタープライズ用途に対し、構造化され検証可能なデータ基盤を提供する点にあります。
OriginTrail DKGのコアコンセプトとアーキテクチャ
OriginTrail DKGのコアは、「分散型ナレッジグラフネットワーク」として定義されます。単なるデータ保存ではなく、マシンがネイティブに解釈可能な「ナレッジ関係」としてデータを構造化します。従来のデータシステムとは異なり、データの相互接続性や意味的な深みを重視し、情報を「説明可能」にします。
ナレッジグラフは「ノード(エンティティ)」と「リレーションシップ(関係)」によるデータネットワークを形成します。たとえば、製品は単独のデータポイントではなく、製造元や物流経路、認証などとリンクし、関連性の網を構築します。この構造によって、データは「孤立した記録」から「推論可能なナレッジ」へと進化します。
OriginTrailでは、こうした構造化データセットをKnowledge Assetとして管理します。各Knowledge Assetは生データに加え、コンテキストや関係、検証情報を含み、ネットワーク全体で発見・検証・再利用可能です。これによりデータは「デジタル資産」として参照・組み合わせ・商用化もできます。
Knowledge AssetはParanet(サブネットワーク)単位でグループ化されます。各ParanetはサプライチェーンやAIデータなど特定領域に特化し、独立したデータエコシステムを形成します。DKGは複数のブロックチェーンと連携し、クロスチェーン検証やデータアンカリングを実現することで、分散性・検証性・クロスネットワーク連携を同時に備えています。さらに、これは分散型ナレッジグラフの定義やWeb3データ構造の進化にもつながります。
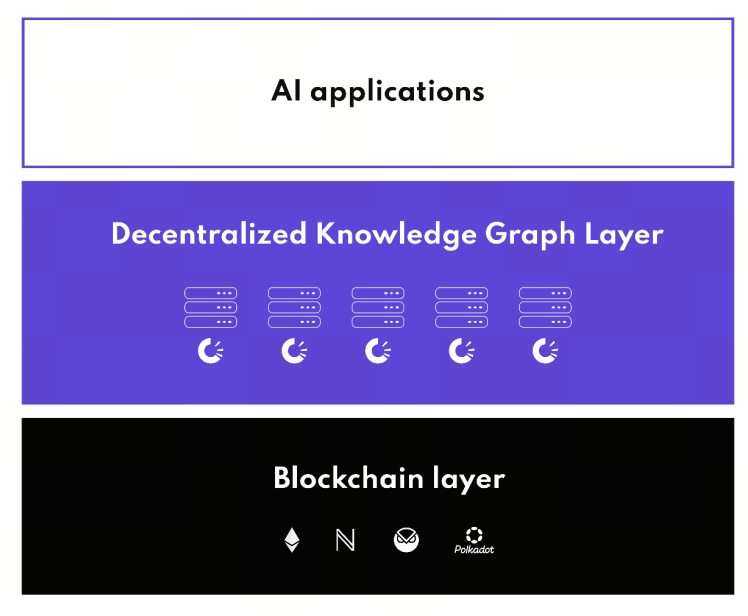
出典:origintrail.io
DKGが従来のデータベースやブロックチェーンと異なる点
DKGの役割を正確に理解するには、データアーキテクチャ内での位置付けを明確にする必要があります。DKGは従来型データベースの代替でも、ブロックチェーンの拡張でもなく、両者の間に「ナレッジレイヤー」という新たなデータ層を導入します。
従来型データベース(SQL/NoSQLなど)は効率的なデータ保存やクエリが強みですが、管理主体が中央集権的であるため、外部からデータの真正性や完全性を独立して検証できません。これは組織横断の連携における大きな課題です。
ブロックチェーンは分散型コンセンサスによりデータの不変性やトレーサビリティを保証しますが、データ構造は取引や状態中心でシンプルなため、複雑なエンティティ関係や意味情報の表現には不向きです。そのため、高度なデータアプリケーションのサポートには限界があります。
DKGは両者の強みを統合します。
ナレッジグラフで複雑な関係データをモデル化し、主要なデータフィンガープリントをブロックチェーンに記録することで、「構造的な表現+検証性」を実現します。要約すると、データベースは「データ」を、ブロックチェーンは「状態」を、DKGは「ナレッジ関係」を保存します。この三層モデルにより、DKGはWeb3データ基盤の中核となり、ブロックチェーンとデータストレージアーキテクチャの違いを明確にします。
OriginTrailのデータ公開・保存ワークフロー
OriginTrail DKGのデータ公開は、標準化かつ検証可能なプロセスとして設計されています。目的は、ネットワークに投入される全データが構造的に表現され、暗号学的に検証可能であることを保証することです。
最初のステップはデータの構造化です。生データをナレッジグラフ形式に変換し、エンティティ・属性・関係を明確に定義します。これにより「生情報」が「マシン解釈可能なナレッジ」となり、高度なクエリや再利用が可能となります。
次にKnowledge Assetの生成を行います。構造化データをKnowledge Assetとしてパッケージ化し、一意の暗号ハッシュを付与します。このハッシュが「フィンガープリント」となり、将来の整合性・一貫性チェックを支えます。
続いてオンチェーンアンカリングとオフチェーンストレージを実施します。主要なデータフィンガープリントはブロックチェーンに記録し、実データは分散型ノードネットワークに保存することで、ブロックチェーンの高コストを回避しつつデータ不変性を確保します。
全体の流れはデータ作成 → 構造化 → Knowledge Asset生成 → オンチェーンアンカリング → 分散保存です。この仕組みにより、「オンチェーン検証+オフチェーン拡張性」のバランスが取れ、DKGはブロックチェーンの信頼性とデータネットワークの柔軟性を両立します。さらに、データのオンチェーン/オフチェーンメカニズムや検証可能なデータ公開プロセスにもつながります。
ノードネットワークの協調とデータ検証
DKGは分散型ノードネットワーク上で稼働します。ノードはKnowledge Assetの保存、クエリサービスの提供、データ整合性の検証を担います。データは複数ノードに複製され、可用性や検閲耐性が強化されます。
テーブルは読み込み中です。読み込みが完了するまでコピーはお控えください。
データ検証では、ノードがハッシュチェックやプロトコルルールを用いてデータの改ざんを防ぎ、ネットワーク全体で一貫性を保ちます。
この協調的アプローチは「分散型データサービスネットワーク」です。従来のブロックチェーンコンセンサスとは異なり、データの可用性と信頼性を重視しています。
さらに分析を進めると、分散型ノード協調メカニズムやデータ整合性・検証モデルが論点となるでしょう。
DKGのクエリおよびデータアクセスモデル
DKGの大きな強みは高度なクエリ機能です。データがナレッジグラフとして整理されているため、単純な検索だけでなく意味的なクエリが可能です。例えば「製品のサプライチェーン経路」をクエリすることもできます。
データアクセス時には、システムがデータソースと検証情報の両方を提供し、ユーザーはデータの信頼性を評価できます。
このモデルにより「発見可能+検証可能」なデータアクセスが実現し、AIアプリケーションの基盤となります。さらに、グラフデータベースのクエリメカニズムや検証可能なデータアクセスモデルの分析も期待されます。
DKGの強みと潜在的な制約
DKGには明確な強みがあります。データの検証性により信頼性を担保し、構造的ナレッジモデリングでAIや複雑なユースケースに最適化されたデータを提供します。分散型アーキテクチャによってデータの所有権と検閲耐性も強化されます。
一方で制約も存在します。
ナレッジグラフは本質的に複雑で厳密なデータモデリングが必要です。ネットワーク性能はノード規模に依存し、シナリオによってはクエリ効率とコストのトレードオフも発生します。
こうした要素から、DKGは「高付加価値データネットワーク」に最適であり、すべてのデータシナリオに万能ではありません。今後は分散型データネットワークの利点と課題やWeb3データの拡張性課題についても議論が進むでしょう。
まとめ
OriginTrail DKGは、ナレッジグラフ、ブロックチェーン、分散ストレージを融合したWeb3データ基盤です。構造的データモデリング、オンチェーン検証、分散型ネットワークというアプローチにより、データの発見性・検証性・堅牢な所有権管理を実現します。
従来のデータベースやブロックチェーンの代替ではなく、データの上位に「ナレッジレイヤー」として補完的に機能します。AIやWeb3の進化とともに、このアーキテクチャは今後のデータ基盤の重要な構成要素となるでしょう。
よくある質問
-
OriginTrail DKGとは?
OriginTrail DKGは、データを構造的に整理し、ブロックチェーン技術で検証性と所有権を管理する分散型ナレッジグラフネットワークです。
-
OriginTrail DKGはどのようにデータの信頼性を確保しますか?
DKGはデータハッシュをブロックチェーンに記録し、分散型ノードネットワークによるデータ保存と検証を行うことで、不変性とトレーサビリティを保証します。
-
DKGとブロックチェーンの違いは何ですか?
ブロックチェーンは主に取引や状態を記録しますが、DKGは構造化されたナレッジデータの整理とクエリを行います。両者はWeb3アーキテクチャ内で異なる役割を担っています。
-
DKGは従来型データベースの代替となりますか?
DKGは従来型データベースを完全に代替するものではなく、検証性や複雑な関係モデリングが必要な高付加価値シナリオで補完的に機能します。
-
DKGはなぜAIやWeb3にとって重要なのですか?
DKGは構造化され信頼できるデータソースを提供し、高品質なデータ上でAIが推論できるようにし、Web3アプリケーションに信頼できるデータ基盤を提供します。
共有
内容
ホルムズ危機により日量1,300万バレルの原油フローが撹乱、インドと中国はロシアの供給に転換
Shytoshi Kusama、13日間の沈黙の後にXへ復帰。SHIBが1.8%下落する中、土曜日のコミュニティ討議を発表
Doppler Finance統合によりリアルタイムXRPL決済を可能にする、Girin LabsのXRP支払いウォレットのローンチ
主要なCEXへ40 Million USDTが送金、Coinglassのデータが判明
JPMorgan:DeFiのセキュリティ悪用と停滞するTVLが機関投資家の採用を制限


関連記事

Falcon Financeトークノミクス:FFバリューキャプチャの解説

Falcon FinanceとEthena:合成ステーブルコイン市場の徹底比較

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

ブロックチェーン上でMidnightはどのようにプライバシーを実現するのか――ゼロ知識証明とプログラマブルなプライバシー機構の詳細解説

ETHを賭ける方法は?
