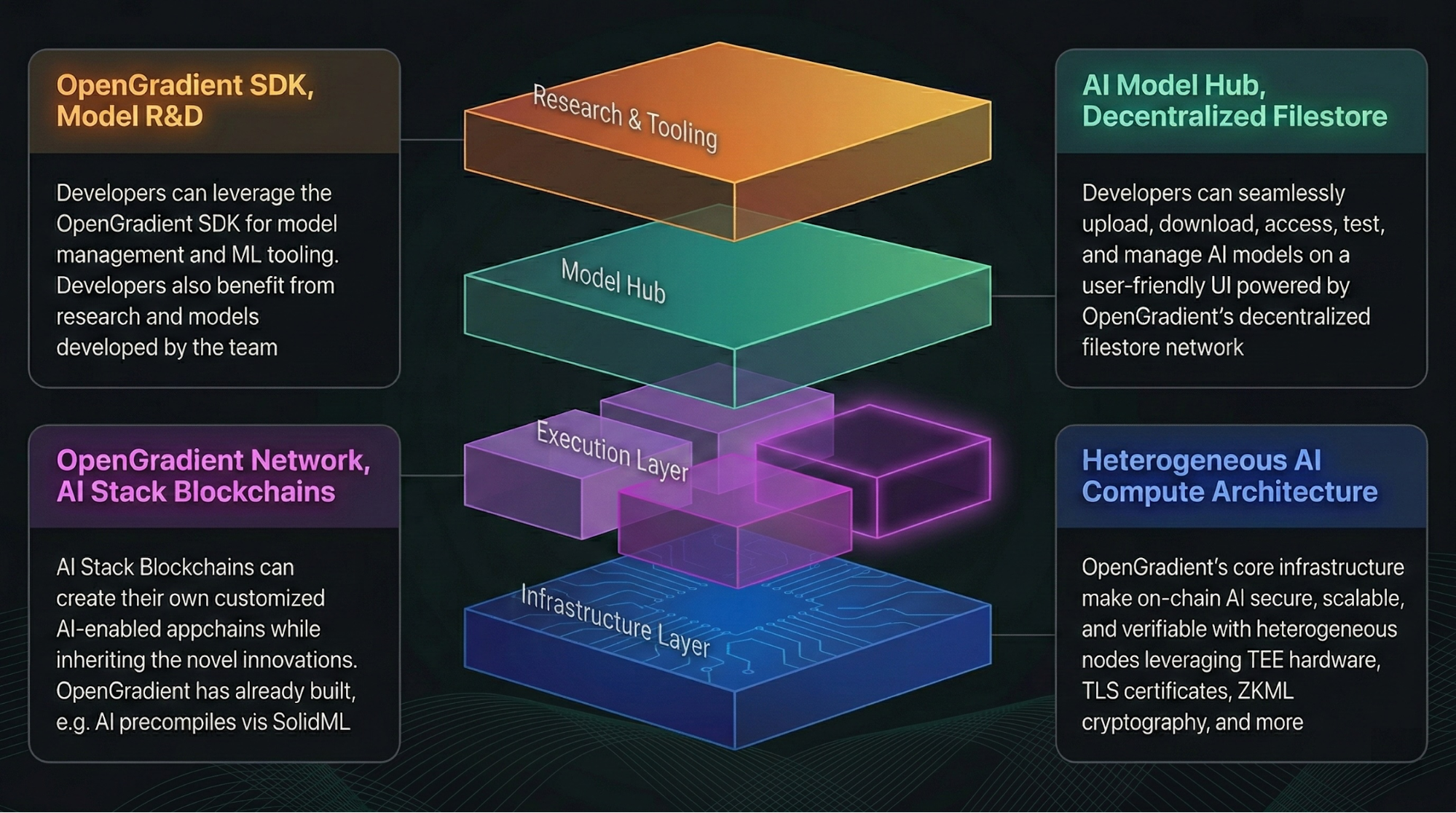
OpenGradientはどのように機能するのか――AIリクエストからオンチェーン検証までのワークフローを解説
実際、開発者やユーザーがAIリクエストを送信しても、直接的に検証できない結果を受け取ることはありません。リクエストは、計算、検証、記録という複数の段階を経るワークフローに入り、信頼性の高い結果を確保する構造となっています。このフレームワークは、自動的な意思決定やデータ処理において特に重要な役割を果たします。
このワークフローには、リクエスト受付、推論実行、結果検証、オンチェーン確認が含まれています。各モジュールの連動により、OpenGradientのオペレーションロジックが支えられています。
OpenGradientネットワークへのユーザー接続方法
ユーザーがアクセスすることで、ワークフロー全体が始動します。
技術的には、開発者はAPIやSDKを通じて自身のアプリケーションをOpenGradientネットワークに接続し、モデルパラメータや入力データを含む推論リクエストを送信します。システムはリクエストを受信後、最適な形式に変換し、割り当て準備を行います。
構造的には、アクセスレイヤーがネットワークの最前線に位置し、ユーザーリクエストを実行可能な内部タスクへ変換してスケジューリングシステムへ転送します。この層には、インターフェースサービスやリクエスト管理モジュールが含まれます。
この設計により、複雑な分散コンピューティングが統一されたインターフェースで抽象化され、ユーザーはネットワークの内部構造を意識せずに利用できます。
OpenGradientにおけるAIリクエストの提出方法
リクエスト提出段階で、タスクが実行パイプラインに入る流れが決まります。
リクエストを受け取ると、システムはタスクの種類、複雑さ、ノードの状態に応じて適切な推論ノードへ割り当てます。この際、スケジューリングアルゴリズムがリソース利用の最適化を図ります。
リクエスト管理モジュールはタスクの詳細を記録し、追跡・検証用のユニークIDを生成します。その後、タスクは実行キューに入り、推論ノードによる処理を待ちます。
このメカニズムにより、効率的なリソース割り当てとノードの混雑防止が実現します。
推論ノードによるモデル計算の実行
推論ノードは、計算処理を担う要素です。
タスク受領後、推論ノードはAIモデルをローカルで実行し、入力データを処理して出力結果を生成します。検証可能性を確保するため、関連する証明データも同時に生成します。
推論ノードはモデル実行環境と結果生成モジュールから構成され、安定性と再現性を保証する管理環境で稼働します。
この段階で計算と証明生成が同時に行われ、以降の検証フェーズの基盤となります。
検証ノードによる推論結果の検証
検証ノードは、推論結果の整合性と信頼性を独立して確認します。
推論ノードから出力データと証明データを受け取り、計算または検証アルゴリズムを使って正当性を検証します。検証が失敗すれば、結果は却下または再計算されます。
検証レイヤーは実行レイヤーとは独立して機能し、検証は元の計算ノードに依存しません。これにより、システム全体のセキュリティが強化されます。
この仕組みにより、信頼性が単一ノードからネットワーク全体へ移行し、不正耐性が高まります。
オンチェーン記録による最終確認
オンチェーン記録は、最終結果を恒久的に記録します。
検証後、結果はブロックチェーンまたは関連データレイヤーに送信され、不変な実行証拠が生成されます。通常、データパッケージ化と確認が必要です。
オンチェーンレイヤーはプロセスの最終段階を担い、分散型台帳上に結果を記録して長期的な追跡性を保証します。
この設計で、計算結果は永続的かつ将来的な監査にも対応可能となります。
モジュール協調による実行プロセスの完遂
モジュール間の協調が、システム全体の効率性を左右します。
リクエスト、実行、検証、記録の各レイヤーはメッセージパッシングやタスクスケジューリングで接続され、各段階で結果を次工程へ渡します。
モジュールはパイプライン構造で配置され、ボトルネックなく連続的なタスク処理を実現します。
| モジュール | 機能 | 位置 |
|---|---|---|
| アクセスレイヤー | リクエスト受付 | エントリーポイント |
| スケジューリングレイヤー | タスク割り当て | 中間 |
| 推論ノード | 計算実行 | コア |
| 検証ノード | 結果検証 | セキュリティレイヤー |
| オンチェーンレイヤー | 結果記録 | 終端 |
この協調体制により、全体のスループットが向上し、各フェーズの責任が明確化されます。
OpenGradient推論ワークフローの構造分解
ワークフロー全体は、連続的なステップに分割できます。
標準的なタスクは、リクエスト提出 → タスク割り当て → モデル実行 → 結果生成 → 検証 → オンチェーン記録の順で進み、この一連の流れがクローズドループを形成します。
各段階は異なるモジュールが管理し、責任の明確化とシステムのスケーラビリティが実現されています。
工程を標準化することで、保守性とシステムの拡張性が高まります。
まとめ
OpenGradientは、AI推論・結果検証・オンチェーン記録を協調モジュール化することで、検証可能な計算を実現します。この構造により、分散型AIネットワークは効率性と信頼性を両立できます。
FAQ
OpenGradientはAIリクエストをどのように処理しますか?
ユーザーがリクエストを送信すると、システムが推論ノードに割り当てて実行し、続いて検証プロセスを開始します。
なぜ検証ノードが必要ですか?
推論結果を独立して検証し、特定のノードへの依存を排除します。
オンチェーン記録の役割は?
最終結果を保存し、不変性と監査性を保証します。
推論ノードと検証ノードの違いは何ですか?
推論ノードは計算を実行し、検証ノードはその結果の正当性を確認します。
OpenGradientはなぜ多段階ワークフローを採用しているのですか?
各モジュールが専門業務に集中することで、効率性とセキュリティが強化されるためです。
共有
内容


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

