Midas Touch: How 43 Years of Tennis Data Became a Prediction Market Money Printing Machine?
PANews

作者:Phosphen
翻訳:Gans 甘斯、Bagel予測市場観察
この男は過去43年間のすべてのプロテニス試合のデータを収集し、それをすべて機械学習モデルに入力し、ただ一つの質問をした:「勝者を予測できるか?」
モデルは一言だけ答えた:「できる。」
そして今年のオーストラリア・オープンで、116試合中99試合を正確に予測し、正確率はなんと85%!
これはモデルの訓練中に一度も見たことのない試合だったが、最終的な優勝者が勝つすべての試合さえも予測しきった。

これらすべては、@theGreenCodingによる、ノートパソコン一台、無料のデータ、オープンソースのコードだけで実現された。
次に、この金鉱のようなプロジェクトを完全に解説し、原始データから最終的な予測成功までを詳述する。これはあなたが見た中で最も印象的なAIと予測成功の例となるだろう。
出発点:一つのフォルダに保存された43年分のテニスデータ
物語は、「スポーツデータの聖杯」と称される資料集から始まる。
この資料集は、1985年から2024年までのATP(男子プロテニス協会)のすべてのプロ試合記録を網羅している。
ブレークポイント、ダブルフォルト、フォアハンド、バックハンド、選手の身長、年齢、ランキング、過去の対戦記録、試合会場……ATPが追跡してきたすべての逐点統計データが揃っている。
40年分のCSVファイルが一つのフォルダに詰まっている。
彼がこの完全なデータセットを開いたとき、コンピュータは即座にクラッシュした。
しかし彼は諦めなかった。データセット内の95,491試合について、多くの派生特徴量を追加で計算した。
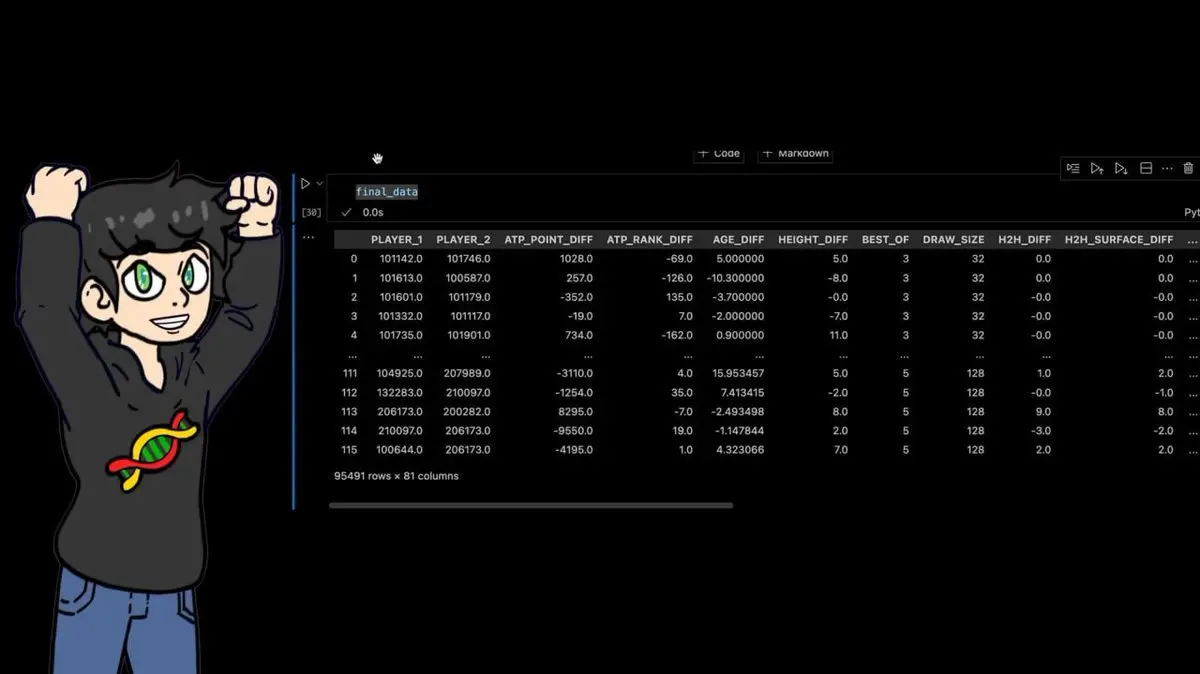
- 二選手の過去の対戦記録
- 年齢差、身長差
- 最近10、25、50、100試合の勝率
- サーブポイント獲得率の差
- ブレークポイントセーブ率の差
- 国際象棋から借用したカスタムELO評価システム(重要ポイント)
最終的なデータセットは:95,491行 × 81列。
過去40年のすべてのプロテニス試合に、数十の手作業で計算された特徴量を付加したものだ。
第二段階:タイタニック号から学んだアルゴリズム

データを分類器に入力する前に、彼はまずアルゴリズムの動作原理を徹底的に理解しようと決めた。そのために、numpyだけを使ってゼロから決定木を自作した。
決定木の仕組みは推理ゲームに似ている——一連の質問を通じて答えに近づいていく。
この概念を説明するために、彼は全く異なるデータセットを選んだ:タイタニック号。
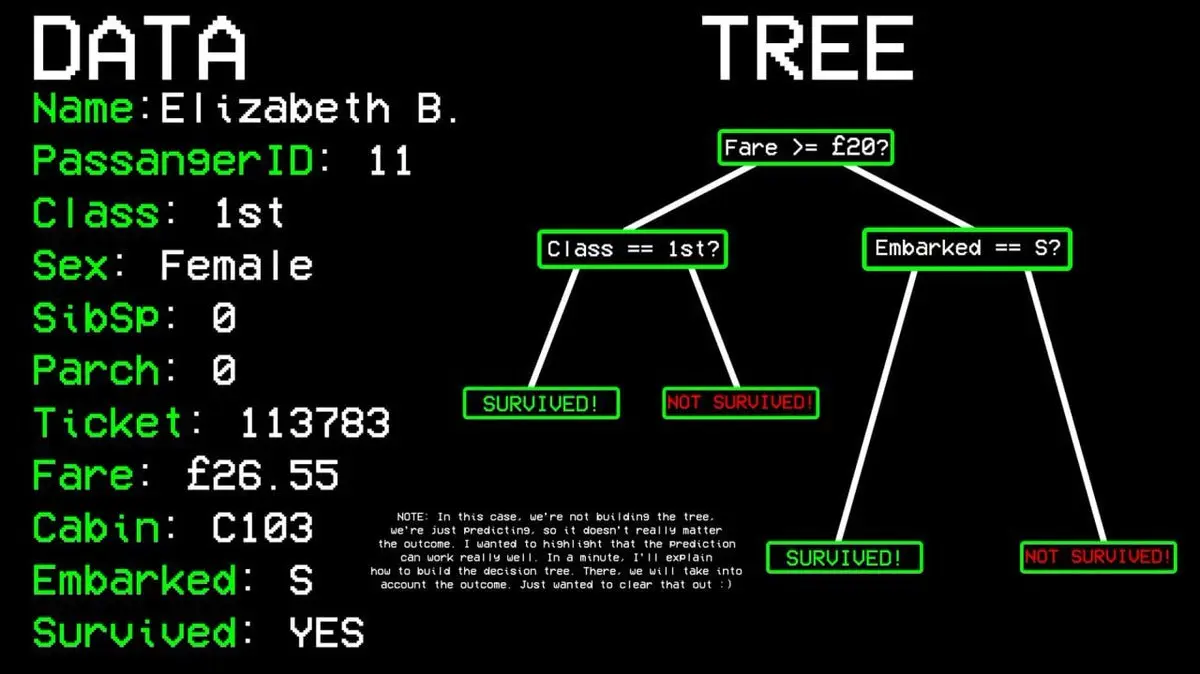
例:乗客11号は生存したか?
- 質問1:ファーストクラスに乗っているか?→はい。
- 質問2:女性か?→はい。
- 予測結果:生存。
アルゴリズムはどうやって質問すべきかを決めるのか?
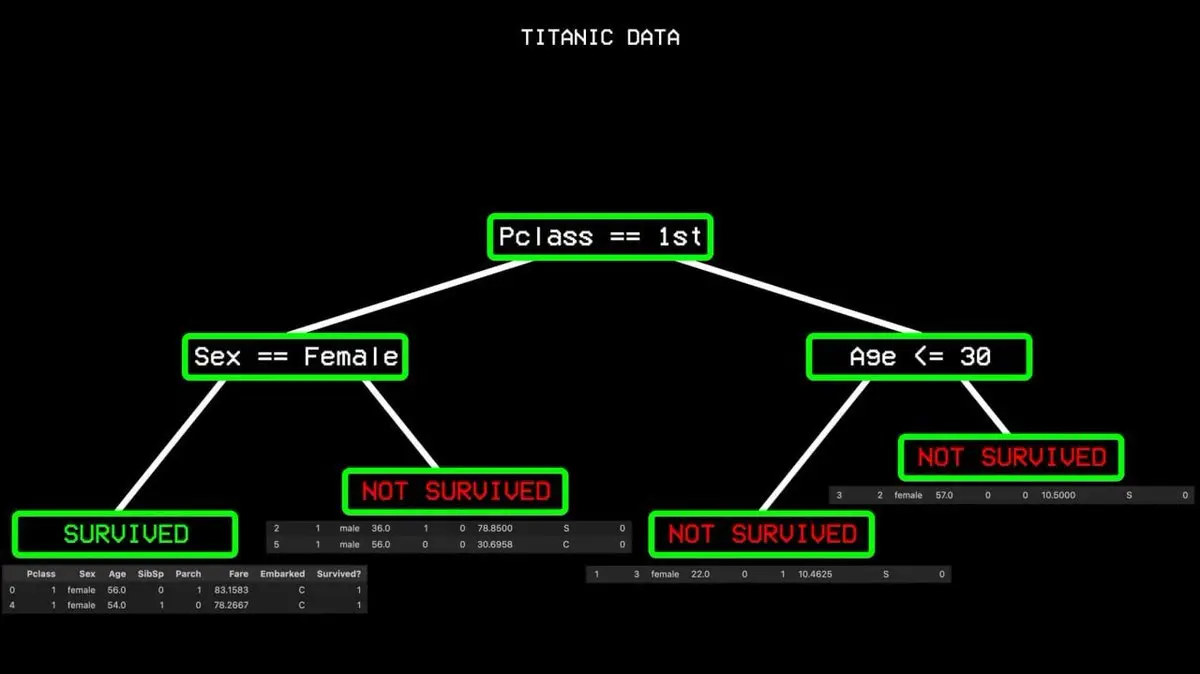
すべてのデータから出発し、「生存」か「非生存」を最もよく区別できる単一の変数を見つける。タイタニックのデータでは、その答えは「客室クラス」だった。ファーストクラスの乗客は一方に、その他はもう一方に分かれる。
しかし、ファーストクラスの中にも遭難した人がいるため、「不純度」が残る。アルゴリズムは次の最良の分割点を探し続ける——それは性別だ。ファーストクラスの女性はすべて生存し、「純粋なノード」となり、これ以上分岐を止める。
この過程を繰り返し、すべてのケースをカバーする完全な決定木を構築していく。
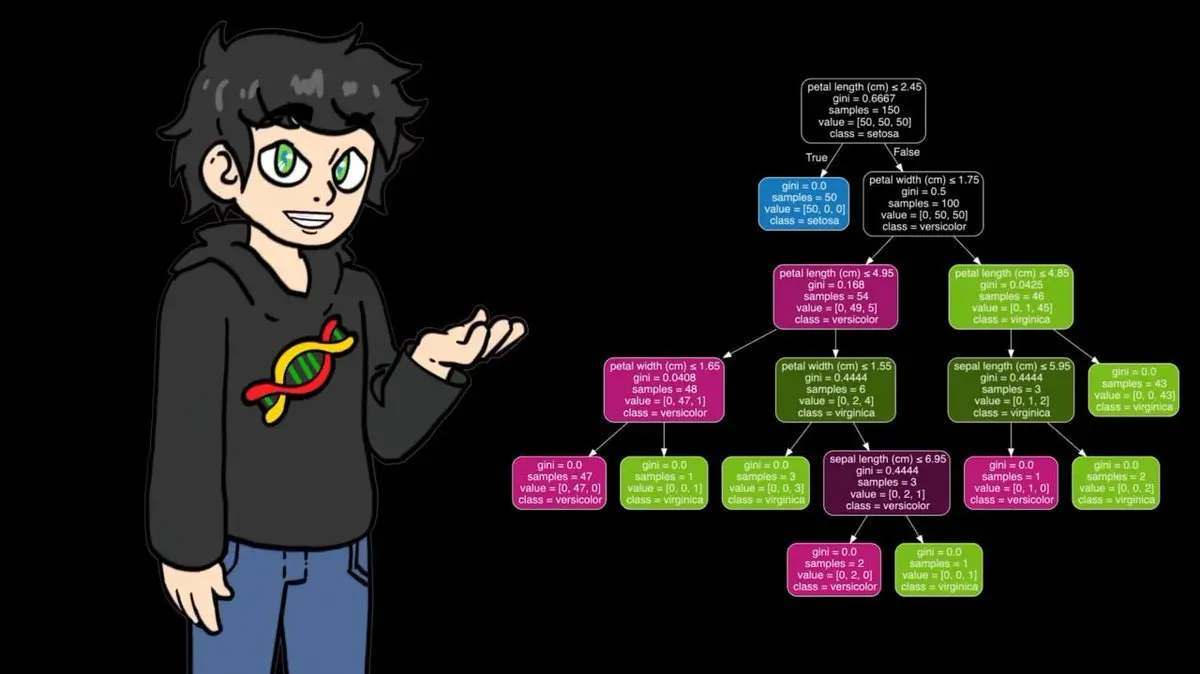
彼の手作りnumpy版は小さなデータセットでは良好に動作したが、95,000試合のデータに適用すると速度が遅すぎて崩壊寸前だった。そこで、正式な訓練段階ではscikit-learnの最適化版に切り替えた。同じロジックだが、はるかに高速だ。
第三段階:勝敗を決める重要変数を見つける
モデル訓練の前に、彼はすべての変数をペアごとに散布図に描き、大きな散布図行列(SNSのpairplot)を作成し、勝者と敗者を区別できる規則性を探した。

ほとんどの特徴はノイズだった。選手IDは明らかに役に立たない。勝率差は一定の規則性を示すものの、明確ではなく、信頼できる分類器には不十分。
唯一、他の変数を凌駕するのは「ELO差」(ELO_DIFF)だけだった。
ELO_DIFFとELO_SURFACE_DIFFの散布図は、二つのカテゴリーの分離度を明確に示しており、他の特徴は比較にならない。
この発見により、彼はこのプロジェクトの最も核心部分を構築した。
第四段階:チェスの評価システムをテニスに導入
ELOは選手の技術レベルを評価する方法で、もともとチェスに最初に適用された。
現在、チェス世界一のマグナス・カールセンの評価は2833点。

彼はこのシステムをテニスに応用することにした。
- 各選手の初期評価:1500点
- 勝利:評価上昇、敗北:評価下降
基本メカニズムは、勝ち負けの得点は対戦相手の評価差に依存し、評価の高い相手に勝てば得点が多く、低評価の相手に負ければ大きく減点される。
2023年ウィンブルドン決勝の例でこの公式を示す:カルロス・アルカラス(評価2063)対ノバク・ジョコビッチ(評価2120)。アルカラスが逆転勝利。

公式に代入すると、アルカラス +14点、ジョコビッチ -14点。
計算は簡単だが、43年の歴史データに適用すると、その威力は驚異的だ。
第五段階:ビッグ3の支配力を可視化
彼はフェデラーのキャリア全体のELO評価を曲線に描いた。デビューから引退まで、すべての試合を記録。
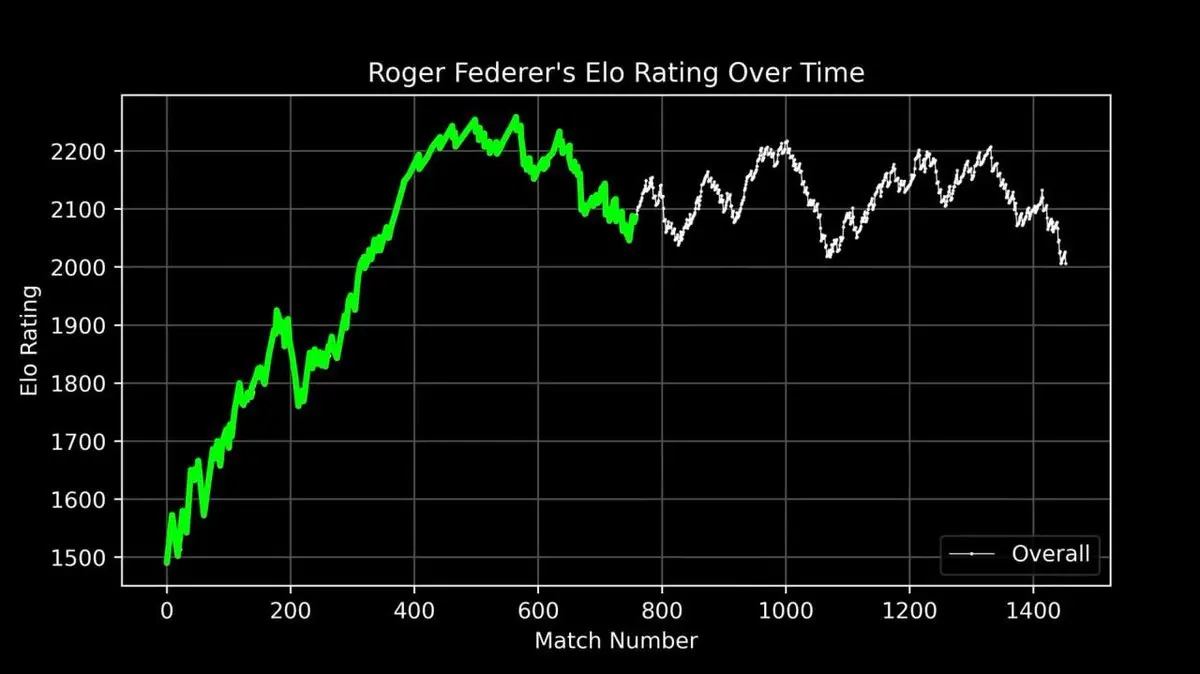
この曲線は伝説の一部を完全に表している:初期の急上昇、ピーク(約400試合目付近)の絶対的支配、そして後期の変動。
しかし、最も衝撃的なのは、フェデラーと1985年以来のすべてのATP選手を同じグラフに重ねたときだ。
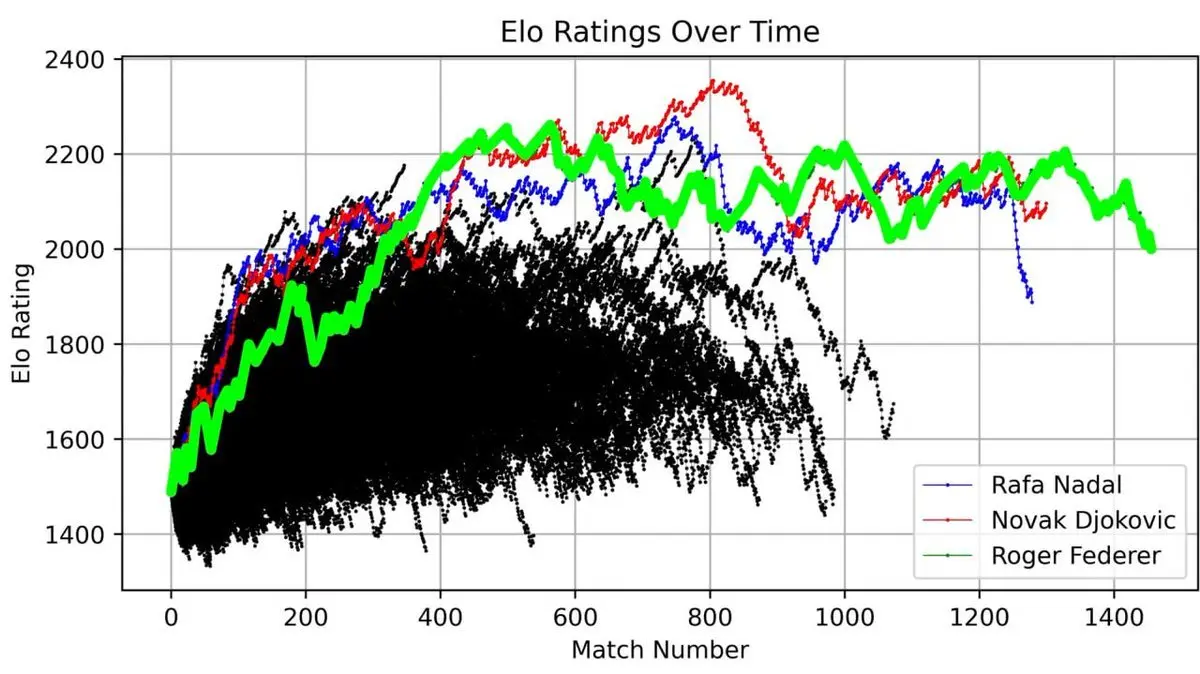
三つの曲線は高くそびえ、他の選手を圧倒している——フェデラー(緑)、ナダル(青)、ジョコビッチ(赤)。
「グランドスラムのビッグ3」という称号は単なる呼称ではない。40年の試合データを可視化すると、この支配力が数学的に明確に見て取れる。
彼のカスタムELOシステムによると、現在の世界一はヤニック・シナー(2176点)、次いでジョコビッチ(2096点)、アルカラス(2003点)だ。

シナーがトップにいることを覚えておいてほしい。これが後の重要なポイントとなる。
第六段階:コートの種類がすべてを変える変数
テニスの試合会場の種類は、その運動の様相を根本から変える。
- クレーコート:遅く、跳ね高い
- 芝コート:速く、跳ね低い
- ハードコート:中間
あるコートで絶対的な支配者だった選手も、別のコートでは全く通用しなくなる。
そこで彼は、3種類のコートごとにELO評価を作った:クレー、芝、ハード。
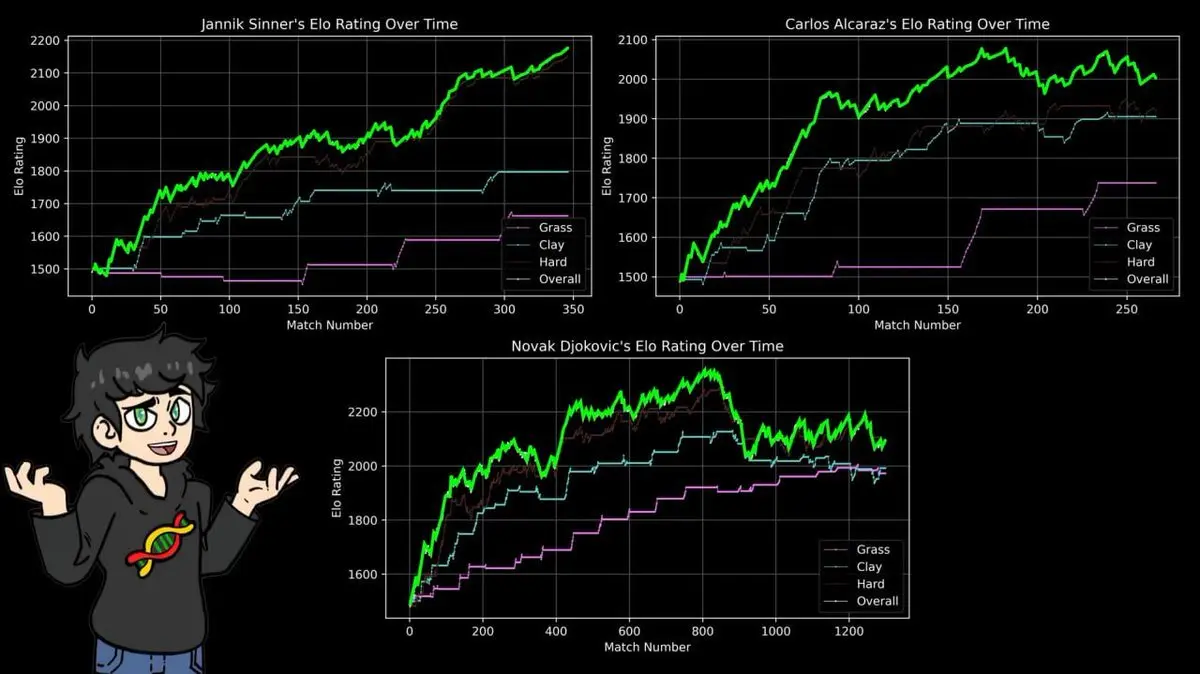
結果は、多くのテニスファンが知っている事実を証明し、40年分のデータで裏付けた。
ナダルのクレーでの最高評価は、フェデラーの芝での最高評価を超え、ジョコビッチのハードコート最高評価をも凌駕し、どの選手も歴史上の最高峰に達している。
112勝4敗のロラン・ギャロス14勝の記録。
ELO公式は、物語や名声を気にしない。勝敗記録だけを扱い、その結論は40年のスポーツ報道と完全に一致している。
第七段階:天井にぶつかる
データ準備とELOシステムの構築が完了し、彼は分類器の訓練を開始した。この過程は、アルゴリズム選択の重要性を完璧に示している。
決定木:正確率74%
単一の決定木は、完全なデータセットで74%の正確率を達成した。良さそうに思える——しかし、ELO差だけで勝者を予測すれば72%に達する。
この時点で、彼の手作りELOシステムに基づく予測はほとんど変わらなかった。
ランダムフォレスト:正確率76%
決定木の問題は「高分散」にある——訓練時に選ばれたデータサブセットに過敏すぎることだ。標準的な解決策はランダムフォレスト:何十本、何百本もの決定木を作り、それぞれ異なるランダムなデータと特徴のサブセットで訓練し、多数決で予測を決める。

94本の異なる決定木が、それぞれの試合に投票。

結果は76%。少し向上したが、天井にぶつかった。ハイパーパラメータをいくら調整しても、特徴を再設計しても、データをいじっても、正確率は77%を超えられなかった。
第八段階:天井を突破する
次に彼はXGBoostを試した——彼はこれを「ランダムフォレストのステロイド版」と呼んだ。
主な違いは、ランダムフォレストは並列で木を作り平均を取るのに対し、XGBoostは逐次的に木を構築し、各新しい木が前のすべての木の誤りを修正する点だ。正則化を導入して過学習を防ぎ、各木を小規模に保つことで、訓練データの丸暗記を避けている。
結果:正確率85%。
これは、ランダムフォレストの76%の壁を大きく突破した。同じデータ、同じ特徴を使いながら、唯一の違いはアルゴリズムだ。
XGBoostも最も重要な3つの特徴量は、ELO差、コート別ELO差、総合ELOだった。このチェスから借用した評価システムは、81列の特徴の中で最も強力な予測因子と証明された。
比較のために、同じデータでニューラルネットワークも訓練したが、正確率83%。悪くはないが、XGBoostに負けている。このデータセットでは、木構造に基づく方法が勝利した。
第九段階:決戦の時——2025年オーストラリア・オープン
これまでのすべては、2024年12月までのデータで訓練された。
2025年1月のオーストラリア・オープンは訓練データに含まれていないため、完璧なテスト場となった。モデルは本当にテニスのルールを理解しているのか、それともただ過去のパターンを記憶しているだけなのか?

彼は試合の全スケジュールを入力し、各試合を予測させた。
結果:116試合中99試合を正確に予測し、誤りはわずか17試合、正確率は85.3%。
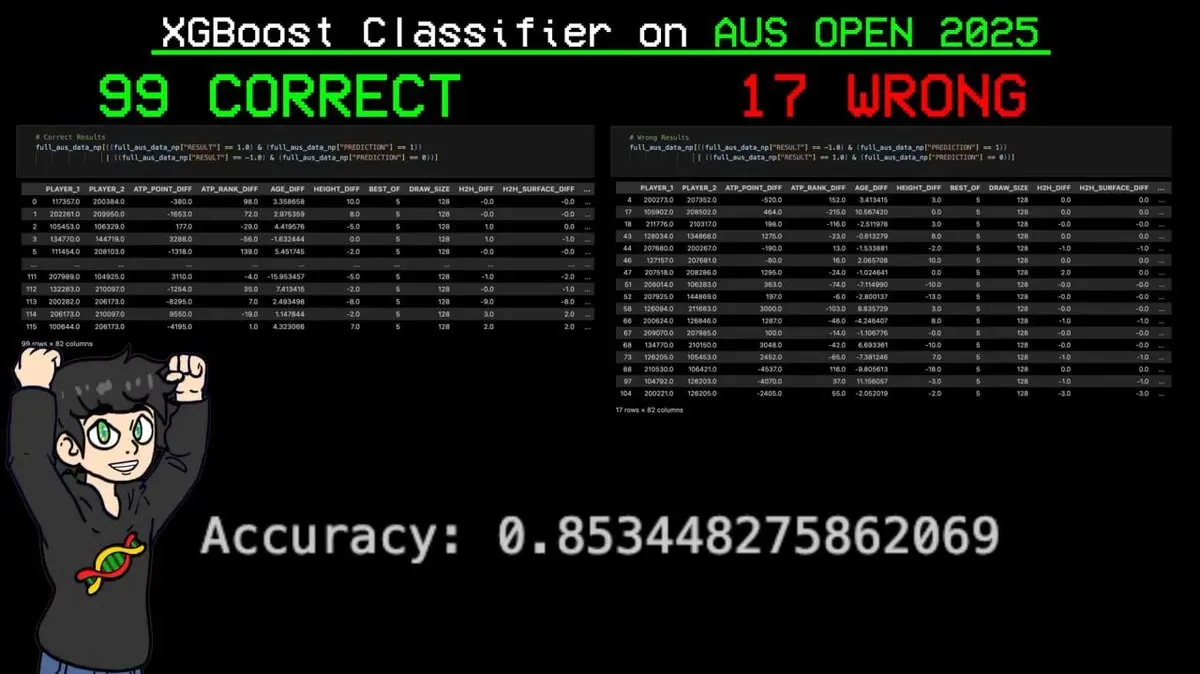
最も重要な予測は、シナー(ELOシステムで世界一の選手)が大会中のすべての勝利を正確に予測したことだ。
試合開始前に、AIはすでにグランドスラムの優勝者を予測していた。
結び
一人の人間、一台のノートパソコン、専用データも高価なインフラも研究チームもなしに、プロテニスの予測モデルを構築し、正確率85%を達成し、大会前にグランドスラムの優勝者を予測した。
テニスのデータはGitHubにあり、完全に再現可能だ。
奇跡を起こすことは、今日ほど身近になったことはない。
本当の差は資源ではなく、あなたがそれをやる意志があるかどうかだ。
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし