Купить криптовалюту
Оплатить в
USD
Купить и Продажа
HOT
Покупайте и продавайте криптовалюту через Apple Pay, карты, Google Pay, банковские переводы и т. д
P2P
0 Fees
Нулевые комиссии, более 400 способов оплаты и простая покупка и продажа криптовалюты
Gate Card
Криптовалютная платежная карта, обеспечивающая бесперебойные глобальные транзакции.
Торговля
Основа
Спот
Торгуйте криптовалютой свободно
Маржа
Увеличьте свою прибыль с помощью кредитного плеча
Конвертация и блочная торговля
0 Fees
Торгуйте любым объемом без комиссий и проскальзываний
Токены с кредитным плечом
Получите простой доступ к позициям с кредитным плечом
Премаркет
Торгуйте новыми токенами до их официального листинга
Фьючерсы
Фьючерсы
Сотни контрактов, рассчитанных в USDT или BTC
Опционы
HOT
Торги опционами Vanilla в европейском стиле
Единый счет
Увеличьте эффективность вашего капитала
Демо-торговля
Начало фьючерсов
Подготовьтесь к торговле фьючерсами
Фьючерсные события
Участвуйте в мероприятиях и выигрывайте щедрые награды
Демо-торговля
Используйте виртуальные средства для торговли без риска
Earn
Запуск
CandyDrop
Собирайте конфеты, чтобы заработать аирдропы
Launchpool
Быстрый стейкинг, заработайте потенциальные новые токены
HODLer Airdrop
Удерживайте GT и получайте огромные аирдропы бесплатно
Launchpad
Будьте готовы к следующему крупному токен-проекту
Alpha Points
NEW
Торгуйте ончейн активами и получайте награды аирдропа!
Фьючерсные баллы
NEW
Зарабатывайте баллы и получайте награды аирдропа
Инвестиции
Simple Earn
Зарабатывайте проценты с помощью неиспользуемых токенов
Автоинвест.
Автоинвестиции на регулярной основе.
Бивалютные инвестиции
Покупайте дешево и продавайте дорого, чтобы получить прибыль от колебаний цен
Мягкий стейкинг
Получайте вознаграждения с помощью гибкого стейкинга
Криптозаймы
0 Fees
Заложите одну криптовалюту, чтобы занять другую
Центр кредитования
Единый центр кредитования
VIP-центр богатства
Настроенное вами управление капиталом способствует росту ваших активов
Управление частным капиталом
Индивидуальное управление активами для роста ваших цифровых активов
Количественный фонд
Лучшая команда по управлению активами поможет вам получить прибыль без лишних хлопот
Стейкинг
Делайте стейкинг криптовалюты, чтобы заработать на продуктах PoS
Умное плечо
NEW
Без принудительной ликвидации до погашения, беззаботный прирост с кредитным плечом
Минтинг GUSD
Используйте USDT/USDC чтобы минтить GUSD для доходности на уровне казначейских облигаций
Еще
X планирует «умные Cashtags» для связывания криптовалютных и фондовых тикеров с актуальными ценами
6ч назад
Должны ли политики иметь право использовать рынки предсказаний? Законопроект в Палате представителей предлагает запрет
7ч назад
Популярные темы
Подробнее471 Популярность
497 Популярность
299 Популярность
5.89K Популярность
84.02K Популярность
Горячее на Gate Fun
Подробнее- РК:$0.1Держатели:10.00%
- РК:$0.1Держатели:10.00%
- РК:$0.1Держатели:10.00%
- РК:$3.57KДержатели:10.00%
- РК:$3.62KДержатели:20.09%
Закрепить
Инсайдеры утверждают, что DeepSeek V4 превзойдет Claude и ChatGPT в программировании, запуск состоится в течение нескольких недель
Вкратце
Сообщается, что DeepSeek планирует выпустить свою модель V4 примерно в середине февраля, и если внутренние тесты что-то показывают, гиганты искусственного интеллекта из Кремниевой долины должны нервничать. Ханчжоуский стартап в области ИИ может ориентироваться на релиз около 17 февраля — Лунного Нового года, естественно — с моделью, специально разработанной для задач кодирования, согласно The Information. Люди, обладающие прямыми знаниями о проекте, утверждают, что V4 превосходит как Claude от Anthropic, так и серию GPT от OpenAI в внутренних бенчмарках, особенно при работе с очень длинными кодовыми подсказками. Конечно, ни один бенчмарк или информация о модели публично не опубликованы, поэтому невозможно прямо подтвердить такие заявления. DeepSeek также не подтверждает слухи.
Тем не менее, сообщество разработчиков не ждет официальных заявлений. Reddit-ресурсы r/DeepSeek и r/LocalLLaMA уже активно обсуждают, пользователи копят API-кредиты, а энтузиасты на X быстро делятся своими прогнозами, что V4 может закрепить за DeepSeek статус бойца-андердога, который отказывается играть по правилам Кремниевой долины за миллиарды долларов.
Это не будет первым прорывом DeepSeek. Когда компания выпустила свою модель рассуждений R1 в январе 2025 года, это вызвало глобальную распродажу на сумму $1 триллион. Причина? Модель DeepSeek R1 совпадала с моделью o1 от OpenAI по математическим и логическим бенчмаркам, несмотря на то, что, по сообщениям, стоила всего $6 миллион на разработку — примерно в 68 раз дешевле, чем тратили конкуренты. Позже модель V3 достигла 90,2% по бенчмарку MATH-500, опередив Claude с 78,3%, а недавнее обновление “V3.2 Speciale” улучшило её показатели ещё больше.
Изображение: DeepSeek
Фокус V4 на кодировании станет стратегическим поворотом. В то время как R1 делал упор на чистое рассуждение — логику, математику, формальные доказательства — V4 представляет собой гибридную модель (рассуждение и нерассуждающие задачи), ориентированную на корпоративный рынок разработчиков, где высокая точность генерации кода напрямую приносит доход. Чтобы занять доминирующее положение, V4 нужно превзойти Claude Opus 4.5, который в настоящее время держит рекорд Verified на тесте SWE-bench с 80,9%. Но если судить по прошлым запускам DeepSeek, то даже при всех ограничениях, с которыми сталкивается китайская лаборатория ИИ, это может быть достижимо. Не так секретный секрет Если слухи правдивы, как эта небольшая лаборатория может добиться такого результата? Секретным оружием компании может стать её исследовательская статья от 1 января: Manifold-Constrained Hyper-Connections, или mHC. Совместно с основателем Лян Вэнфэнгом, новый метод обучения решает фундаментальную проблему масштабирования больших языковых моделей — как расширить ёмкость модели без её нестабильности или взрыва во время обучения. Традиционные архитектуры ИИ заставляют всю информацию проходить через один узкий канал. mHC расширяет этот канал в несколько потоков, которые могут обмениваться информацией без разрушения процесса обучения.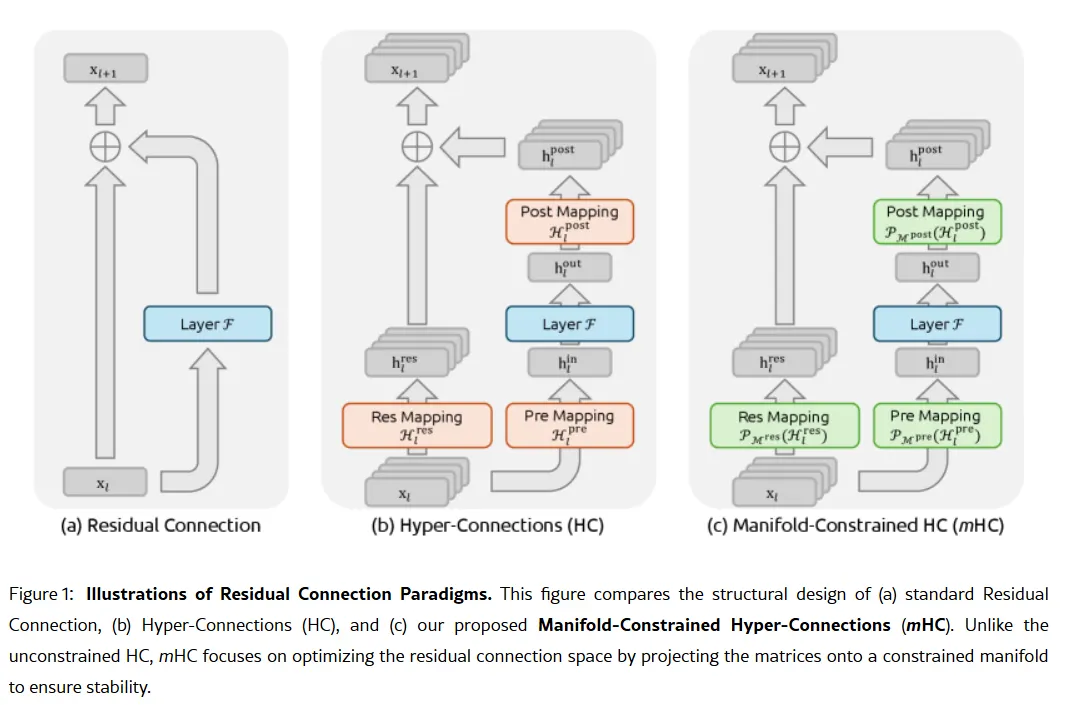
Изображение: DeepSeek
Вэй Су, главный аналитик по ИИ в Counterpoint Research, назвала mHC “поразительным прорывом” в комментариях Business Insider. Она отметила, что эта техника показывает, что DeepSeek может “обойти узкие места вычислений и добиться скачков в интеллекте”, даже при ограниченном доступе к передовым чипам из-за экспортных ограничений США. Лян Цзе Су, главный аналитик Omdia, отметил, что готовность DeepSeek публиковать свои методы свидетельствует о “новообретённой уверенности в китайской индустрии ИИ”. Открытый подход компании сделал её любимицей среди разработчиков, которые видят в ней воплощение того, чем раньше была OpenAI, прежде чем она переключилась на закрытые модели и раунды сбора миллиардных средств.
Не все убеждены. Некоторые разработчики на Reddit жалуются, что модели рассуждений DeepSeek тратят вычисления на простые задачи, в то время как критики утверждают, что бенчмарки компании не отражают реальную сложность мира. Один пост на Medium под названием “DeepSeek отстой — и я перестану притворяться, что это не так” стал вирусным в апреле 2025 года, обвиняя модели в создании “шаблонного бреда с ошибками” и “галлюцинированных библиотек”. DeepSeek также имеет свои проблемы. Вопросы конфиденциальности преследуют компанию, некоторые правительства запрещают нативное приложение DeepSeek. Связи компании с Китаем и вопросы цензуры в её моделях добавляют геополитическую напряжённость в технические дебаты. Тем не менее, динамика очевидна. DeepSeek широко используется в Азии, и если V4 оправдает свои обещания в области кодирования, то внедрение в бизнес-среде на Западе может последовать.
Изображение: Microsoft
Также важен тайминг. Согласно Reuters, DeepSeek изначально планировал выпустить модель R2 в мае 2025 года, но продлил сроки после того, как основатель Лян был недоволен её производительностью. Сейчас, с учетом того, что V4, как сообщается, выйдет в феврале, а R2 — возможно, в августе, компания движется с такой скоростью, которая говорит либо об ощущении срочности, либо о уверенности. Возможно, и то, и другое.