
Автор: Phosphen
Переклад; Gans 甘斯, Bagel прогноз ринку спостереження
Цей чоловік зібрав дані всіх професійних тенісних матчів за останні 43 роки, ввів їх у модель машинного навчання і поставив лише одне питання: чи зможете ви передбачити, хто виграє?
Модель відповіла всього одним словом: так.
Після цього вона у цьому році на Australian Open правильно передбачила 99 з 116 матчів, точність склала 85%!
Це матчі, яких модель раніше не бачила під час тренування, і вона навіть у фіналі передбачила кожну перемогу чемпіона.

Все це було зроблено лише за допомогою ноутбука, безкоштовних даних і відкритого коду, створеного @theGreenCoding.
Далі я повністю розберу цей проект, від початкових даних до успішних прогнозів. Це буде один із найвражаючих прикладів AI + успішного прогнозування, які ви коли-небудь бачили.
Початок: папка з даними про теніс за 43 роки
Історія починається з набору даних, який можна назвати «святим Граалем спортивних даних».
Цей набір охоплює всі професійні матчі ATP (Міжнародна асоціація професійного тенісу) з 1985 по 2024 рік.
Розбір геймплейних моментів, подвійних помилок, форхенд, бекхенд, зріст гравця, вік, рейтинг, історія особистих зустрічей, майданчик… Усі статистичні дані по кожному розіграшу, які коли-небудь відслідковувалися ATP.
Чотири десятиліття CSV-файлів, зібраних у одну папку.
Коли він відкрив цей великий набір даних, його комп’ютер просто завис.
Але він не здався. Для 95 491 матчу у наборі він додатково обчислив багато похідних ознак:
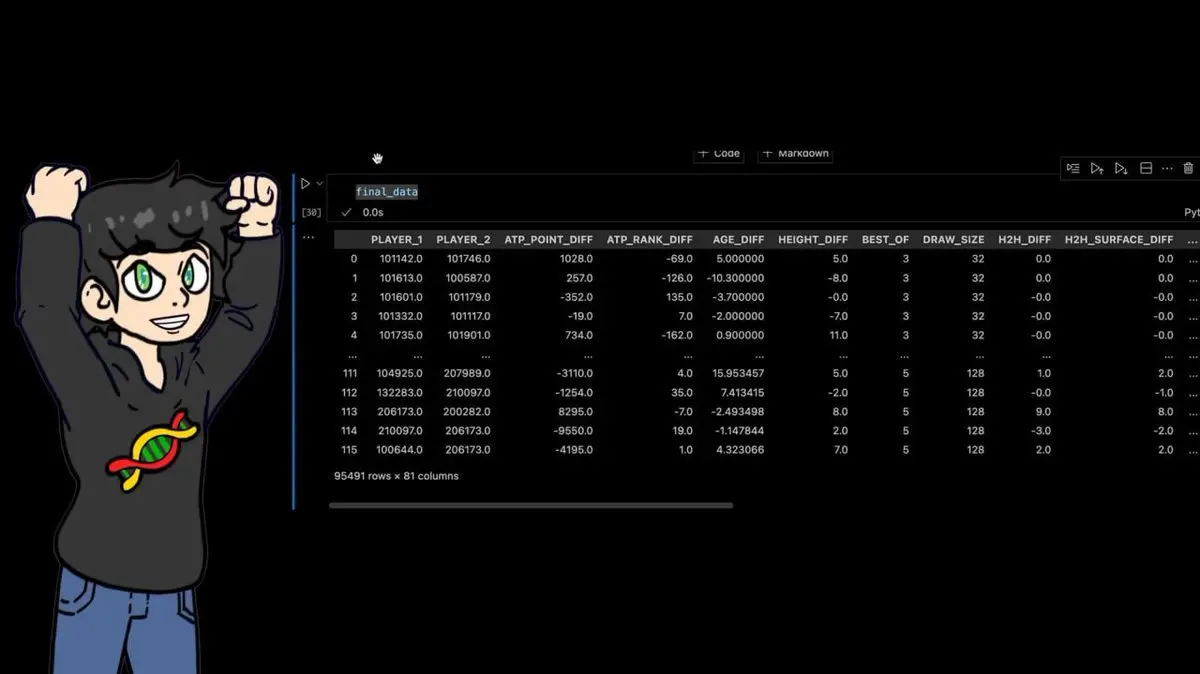
- Історія особистих зустрічей двох гравців
- Різниця у віці, зрості
- Відсоток перемог у останніх 10, 25, 50, 100 матчах
- Різниця у відсотках очок з першої подачі
- Різниця у відсотках врятованих брейк-пойнтів
- Власна система оцінки ELO, запозичена з шахів (ключовий момент)
Загальний набір даних: 95 491 рядок × 81 стовпець.
Кожен матч за останні 40 років із десятками ручних обчислень ознак.
Другий крок: алгоритм, запозичений із «Титаніка»

Перед тим, як вводити дані у класифікатор, він вирішив спершу глибоко зрозуміти, як працює алгоритм. Для цього він з нуля написав на numpy дерево рішень.
Дерево рішень працює як логічна гра — через послідовність питань поступово наближає до відповіді.
Щоб пояснити цю концепцію, він взяв зовсім інший набір даних — «Титанік».
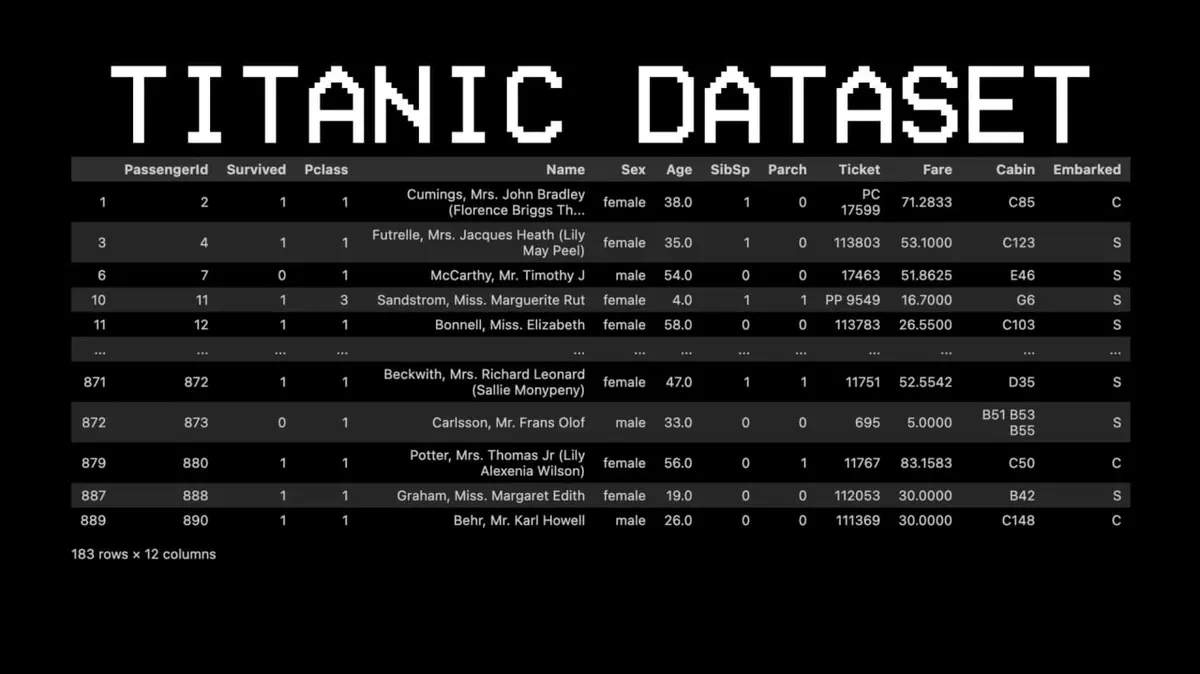
Приклад: чи вижив пасажир №11?
- Питання 1: Він у першому класі? → Так.
- Питання 2: Він жінка? → Так.
- Прогноз: вижив.
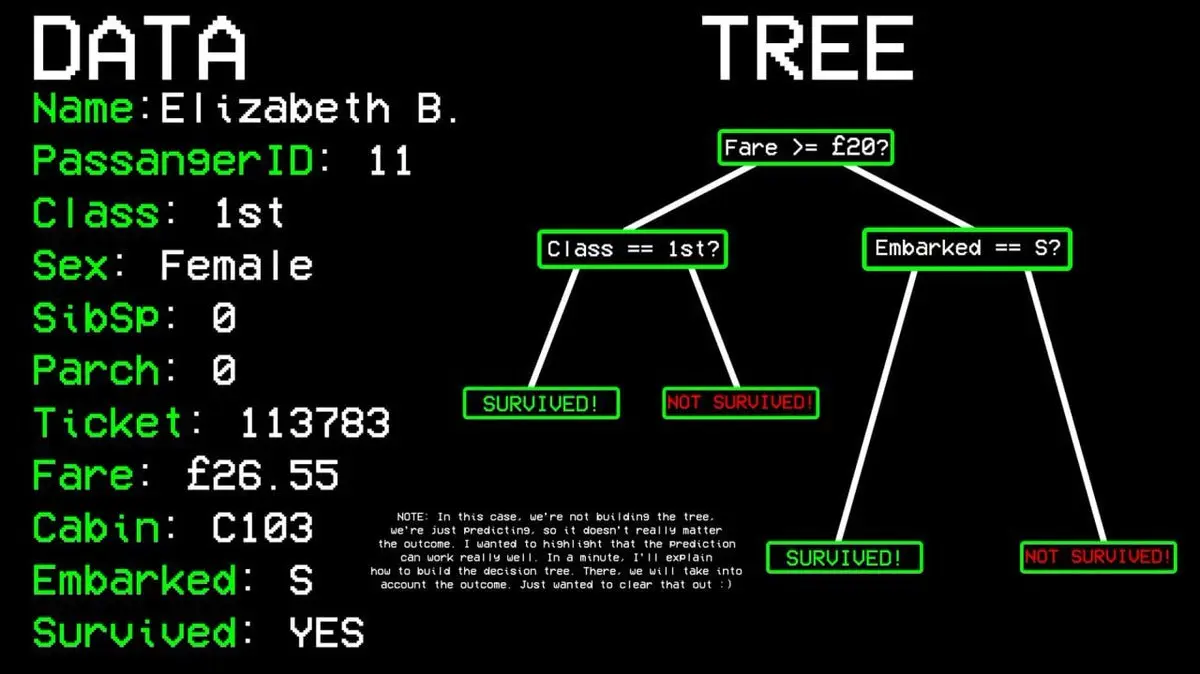
Як алгоритм вирішує, які питання ставити?
Він починає з усіх даних і шукає найкращий одноваріантний розподіл — найкращий ознаковий критерій для розділення «вижив» і «не вижив». У даних «Титаніка» цим критерієм стала класність каюти. Пасажири першого класу — одне, інші — інше.
Але й серед перших класів траплялися випадки загибелі, тому розподіл був неповним. Алгоритм шукає далі, наступний найкращий критерій — стать. Усі жінки з першого класу вижили, і ця гілка стала «чистою» — подальше розбиття не потрібно.
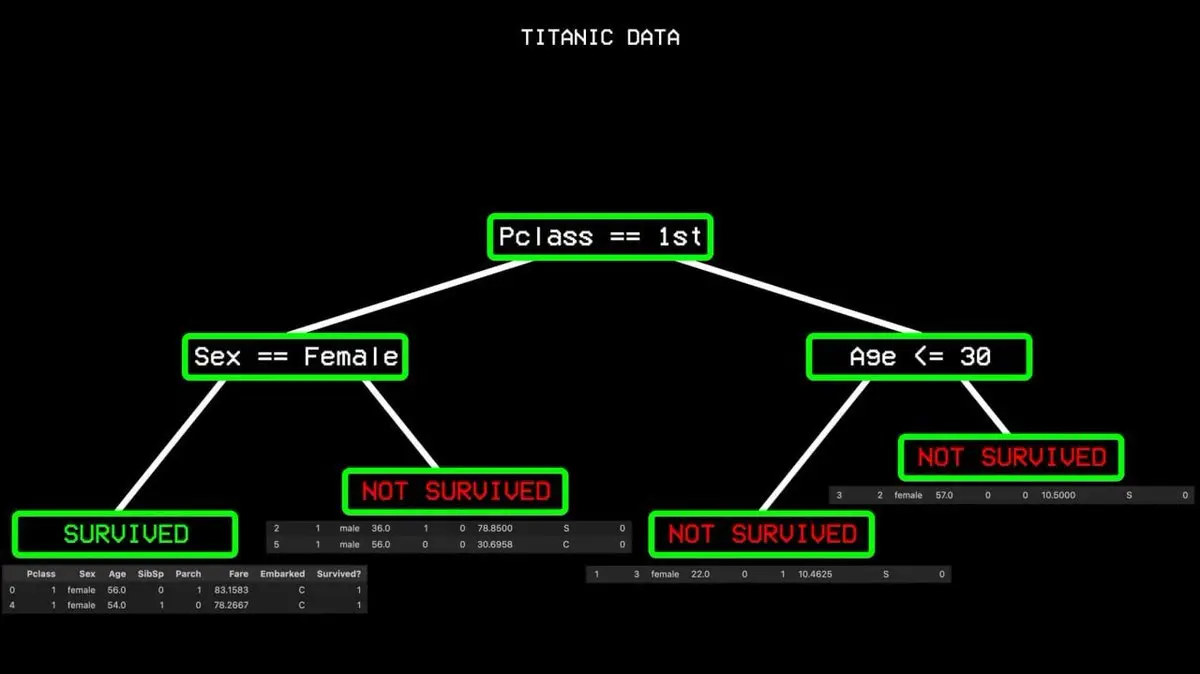
Процес повторюється, доки не побудується повне дерево, що охоплює всі можливі ситуації.
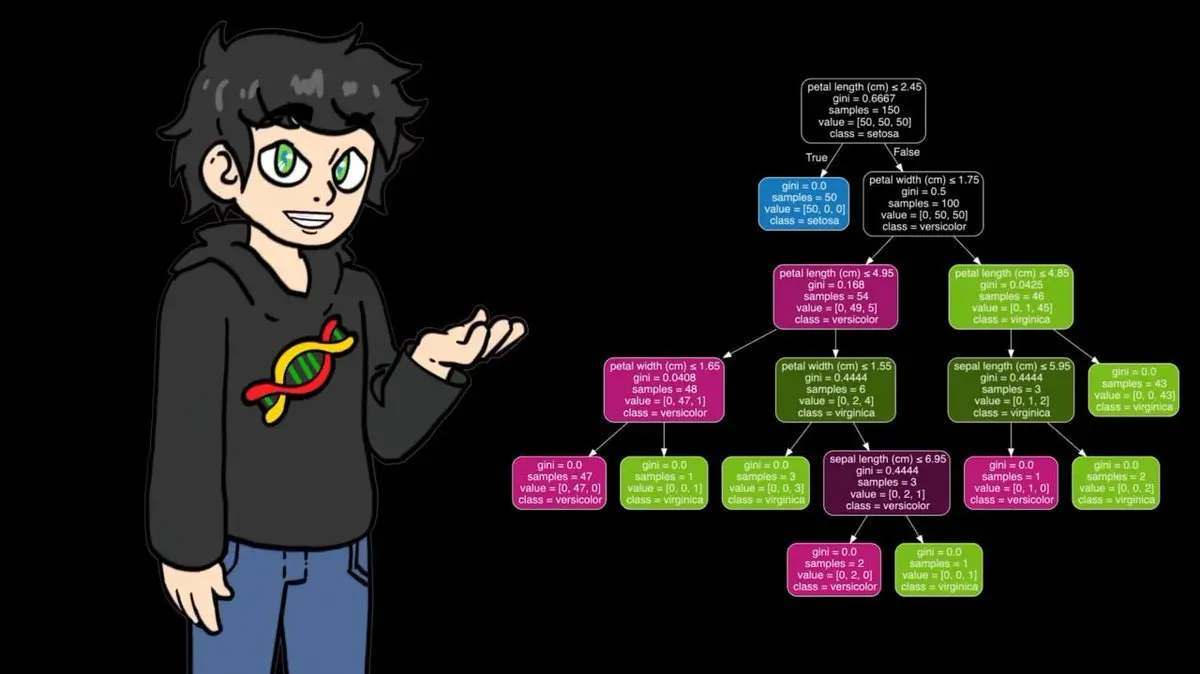
Його реалізація на numpy добре працювала на невеликих наборах, але при 95 000 матчах швидкість стала надто повільною. Тому під час тренування він перейшов на оптимізовану версію з sklearn — та сама логіка, але значно швидше.
Третій крок: пошук ключових ознак для визначення переможця
Перед тренуванням він побудував матрицю парних графіків (SNS pairplot), щоб візуально знайти ознаки, що найкраще розділяють переможців і програвших.

Більшість ознак — шум. ID гравця явно не має значення. Різниця у відсотках перемог — має закономірності, але недостатньо очевидні для надійної класифікації.
Єдина ознака, що значно переважає інші — різниця у ELO (ELO_DIFF).
Графіки ELO_DIFF і ELO_SURFACE_DIFF чітко показують розподіл між двома класами, інші ознаки не йдуть поруч.
Це відкриття стало ядром усього проекту.
Четвертий крок: застосування системи оцінки ELO з шахів до тенісу
ELO — це система оцінки рівня гравця, вперше застосована у шахах. Найвищий рейтинг у світі — Магнус Карлсен із 2833 балами.

Він вирішив адаптувати цю систему до тенісу:
- Початковий рейтинг кожного гравця — 1500 балів
- Перемога — підвищення рейтингу; поразка — зниження
Механіка: кількість набраних або втратених балів залежить від різниці у рейтингах з опонентом. Перемога над сильнішим — більше балів, програш слабшому — більше штрафів.
На прикладі фіналу Вімблдону 2023 року: Карлос Алькарас (2063) проти Новака Джоковича (2120). Алькарас переміг — отримав +14 балів, Джокович — -14.
Обчислення просте, але при застосуванні до 43 років історичних даних — вражаюче ефективне.
П’ятий крок: візуалізація домінування трійки великих
Він побудував графік ELO для Федерера за всю кар’єру — від дебюту до відходу. Кожна гра — точка на графіку.
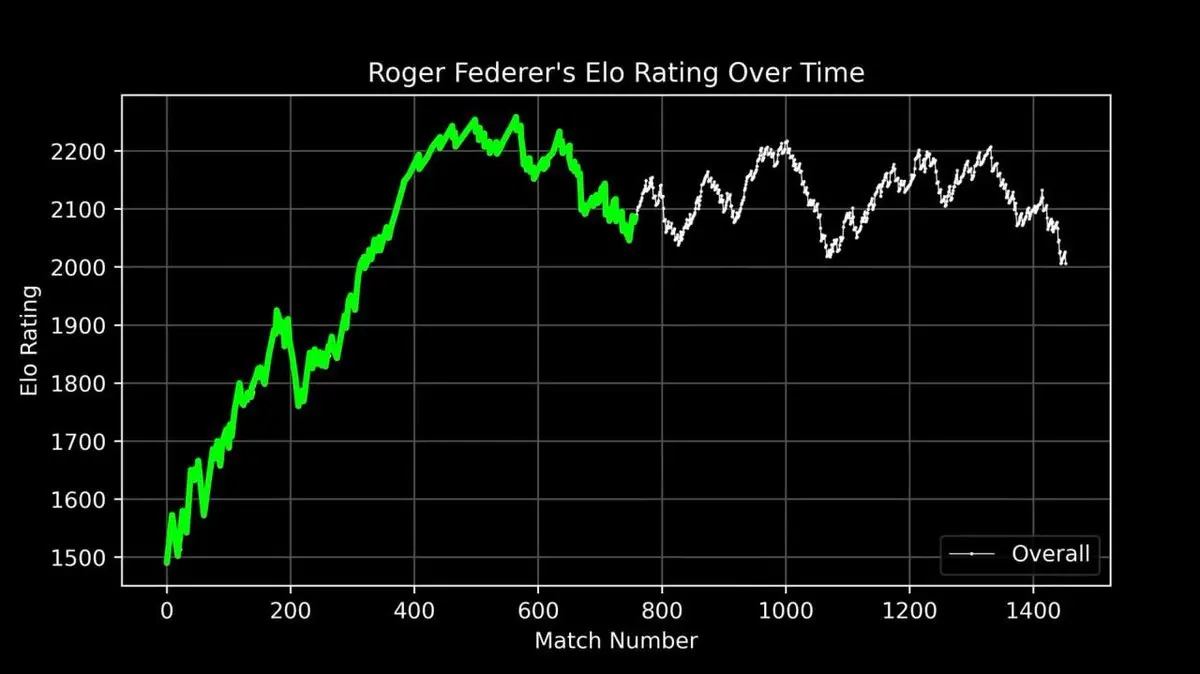
Ця крива показує швидкий підйом, пік (близько 400 матчів), абсолютне домінування і коливання наприкінці.
Але справжній шок — коли він наклав на один графік усіх ATP-гравців з 1985 року:
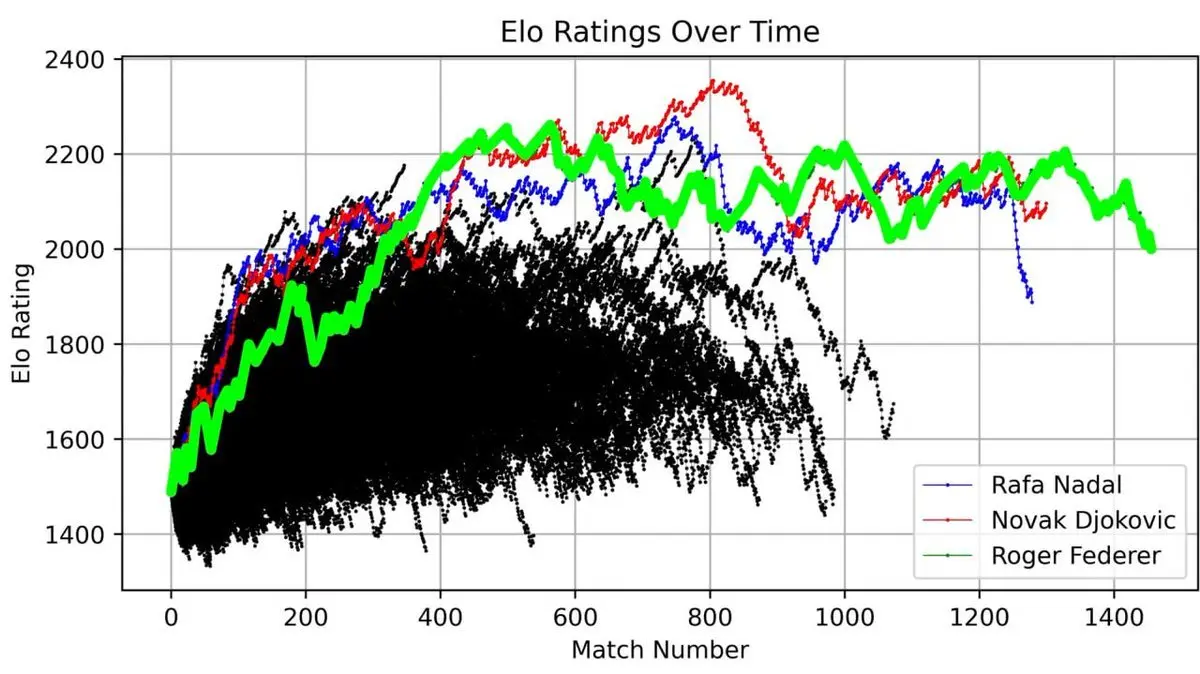
Три лінії — Федерер (зелений), Надаль (синій), Джокович (червоний) — значно вище за інших.
«Велика трійка» — не просто титул. Візуалізація 40-річних даних показує цю домінуючу силу у числах.
За його системою ELO, зараз перший у світі — Яннік Сіннер (2176), далі — Джокович (2096) і Алькарас (2003).

Запам’ятайте, що Сіннер — перший у рейтингу — це важливо для подальших висновків.
Шостий крок: майданчик — змінює все
Тип покриття у тенісі кардинально змінює гру:
- ґрунт — повільний, високий відскок
- трава — швидкий, низький відскок
- тверде покриття — між ними
Гравець, який домінує на одному майданчику, може повністю провалитися на іншому.
Тому він створив окремі ELO для кожного типу покриття: ґрунт, трава, тверде.
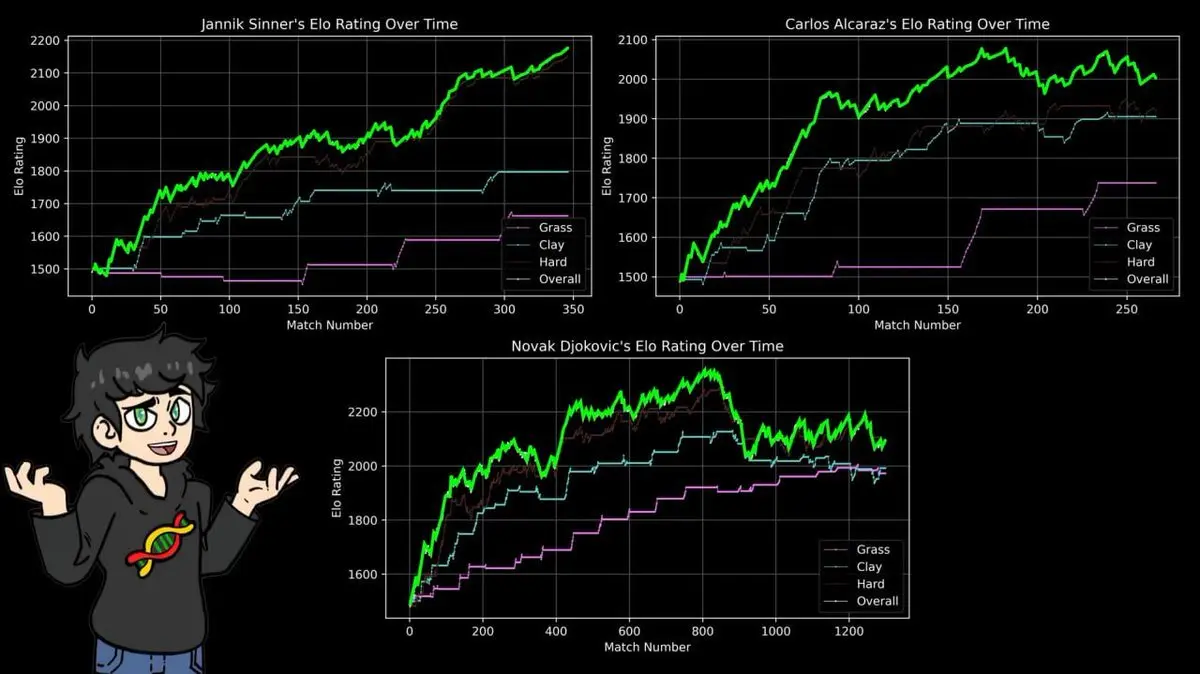
Результати підтвердили відомий факт: Надаль на ґрунті має найвищий рейтинг, перевищуючи найкращі показники Федерера на траві і Джоковича на твердому. Всі 14 титулів на Ролан Гаррос — 112 перемог і 4 поразки.
ELO не враховує історії, слави чи популярності — він просто рахує перемоги і поразки. І висновки збігаються з 40-річними спортивними новинами.
Сьомий крок: «стеля» у даних
Дані зібрано, система ELO налаштована — він почав тренувати класифікатор. Це показує, наскільки важливий вибір алгоритму.
Дерево рішень: точність 74%
Одне дерево на всьому наборі — 74%. Звучить непогано — але вже можна сказати, що простий ELO-прогноз дає 72%.
Дерево на базі вже створеної системи — майже не дає приросту.
Random Forest: точність 76%
Проблема одного дерева — високий «варіативність» (variance). Щоб її зменшити, створюють багато дерев — «ліс» — і голосують більшістю.

94 різних дерева голосують за кожен матч.

Результат — 76%. Це вже максимум, що вдалося досягти. Зміни гіперпараметрів, нові ознаки, додаткові дані — все одно не більше 77%.
Восьмий крок: прорив через «стелю»
Далі він спробував XGBoost — «стандартний» градієнтний бустинг, що називає «стертим» варіантом «лісу».
Основна різниця — у послідовному навчанні: кожна нова модель коригує помилки попередніх. Вводиться регуляризація, щоб уникнути переобучення, і обмежується розмір кожної моделі.
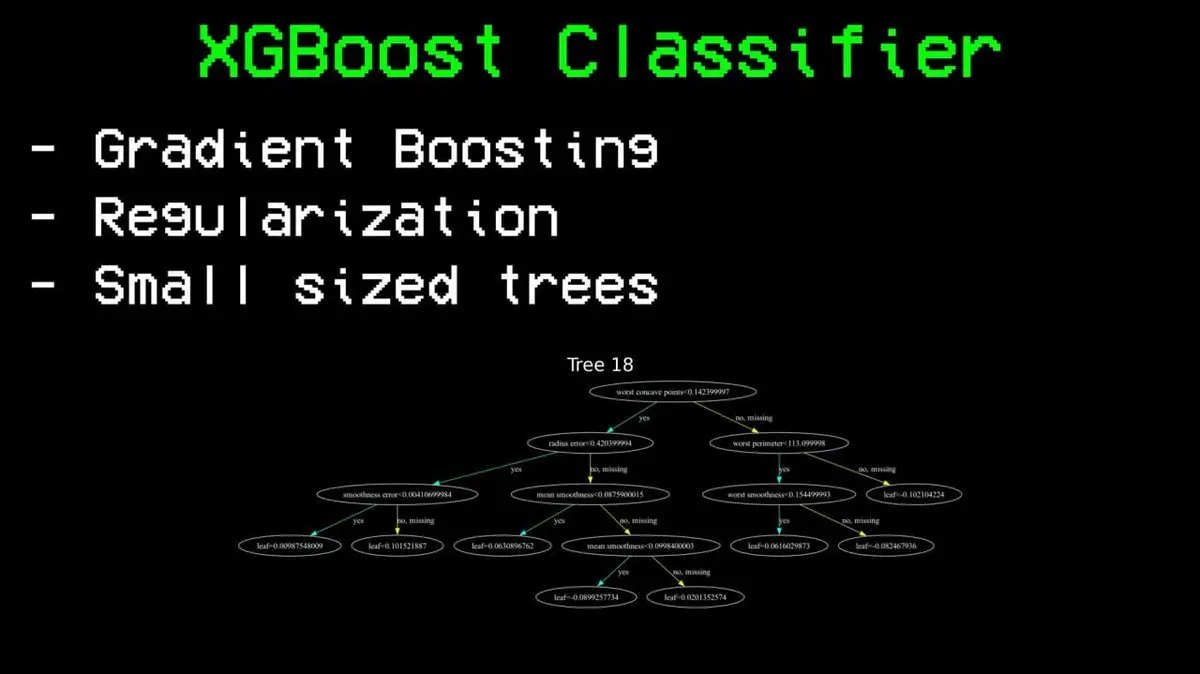
Результат — точність 85%.
Це значний прорив порівняно з 76%. За однакових даних, з однаковими ознаками — лише зміна алгоритму.
XGBoost знову визначив три найважливіші ознаки: різницю у ELO, різницю у ELO для конкретного майданчика і загальний ELO. Ця система, запозичена з шахів, виявилася найкращим предиктором.
Для порівняння, він натренував нейромережу — і отримав 83%. Це теж добре, але програє XGBoost. На цьому наборі даних дерева — найкращий варіант.
Дев’ятий крок: фінальна битва — Australian Open 2025
Все вище — тренування на даних до грудня 2024 року.
Australian Open 2025 — безпосередньо перед турніром, і його дані не входили у тренувальний набір. Це ідеальний тест: чи навчився AI розуміти справжні закономірності тенісу, чи просто запам’ятовує історичні патерни?

Він подав усі матчі турніру у модель і передбачив кожен результат.
Результат: з 116 матчів правильно — 99, помилка 17. Точність — 85.3%.
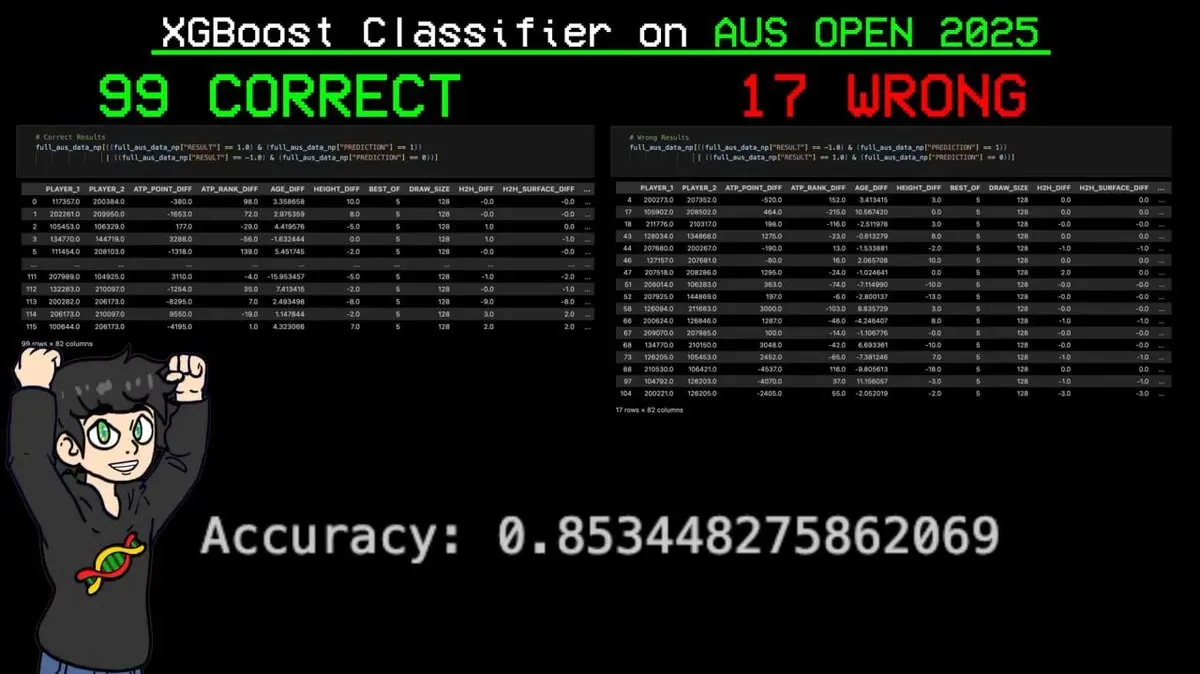
Найважливіше — модель точно передбачила перемогу Янніка Сіннера (найвищий рейтинг у світі) у всьому турнірі.
Ще до першого удару AI передбачив переможця «Великого шлему».
Підсумок
Один чоловік, один ноутбук, без власних даних, без дорогих ресурсів, без дослідницької команди — і створив модель прогнозування професійного тенісу з точністю 85%, яка передбачила чемпіона ще до початку турніру.
Дані з тенісу — на GitHub, їх можна відтворити.
Створювати чудеса ніколи не було так просто.
Різниця не в ресурсах — у бажанні щось зробити.
