傳統區塊鏈多將資料視為附屬,將儲存與執行分開,導致鏈上應用難以直接處理大規模資料,並需仰賴外部服務。Irys 則將「資料儲存、驗證與執行」整合於同一架構,旨在解決此結構性難題。
要理解 Irys,必須掌握其完整資料生命週期:資料如何上傳、在網路中被驗證,以及如何存取與運用。同時,其底層「分區儲存與挖礦機制(Partition Lifecycle)」是理解資料可驗證性的核心所在。
Irys 資料儲存原理:去中心化資料層與可驗證儲存機制
Irys 採用「資料鏈(Datachain)」架構,將資料直接納入區塊鏈共識體系。不同於傳統儲存,資料不再只是被保存,而是成為可驗證的鏈上狀態。
在這一模型下,每筆資料都需經網路確認「確實存在且可存取」。此機制使資料從「被動儲存」轉化為「可證明存在」,提升系統整體可信度。
此外,Irys 將資料與執行環境整合,使資料不僅可讀取,也能參與鏈上運算。這一設計讓其從「儲存協議」升級為「資料基礎設施層」。
資料上傳流程:用戶提交到鏈上記錄的資料寫入路徑
在 Irys 中,資料上傳流程類似區塊鏈交易。用戶先將資料打包並提交至網路,資料隨即進入鏈上處理階段。
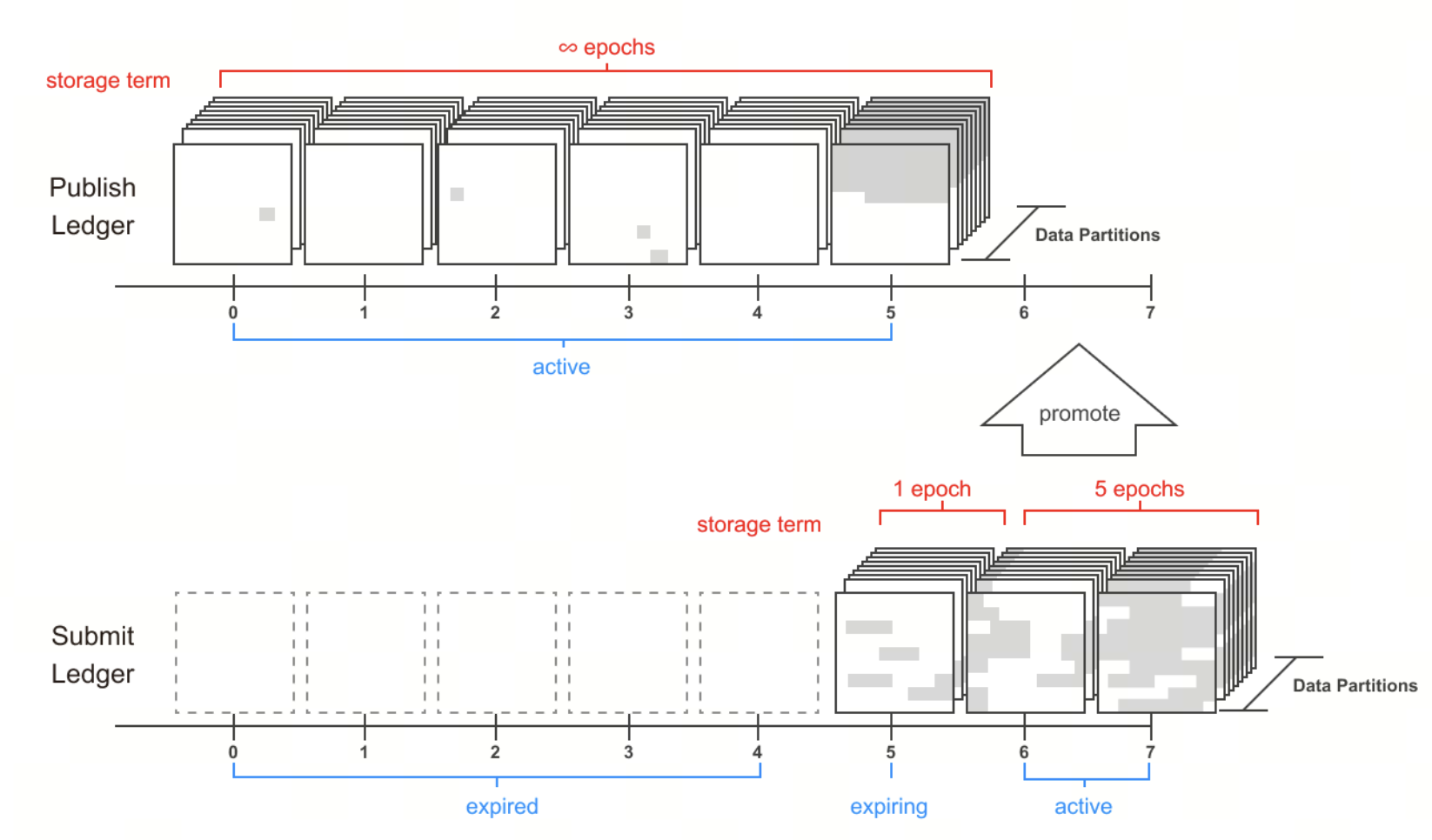
資料不會集中儲存,而是分拆並分配到網路中不同儲存分區(Partition)。分區是 Irys 儲存架構的基本單位,每個分區容量約 16TB,確保網路擴展性與儲存成本可控。
資料寫入區塊後,其狀態記錄於鏈上,進入後續驗證流程。此過程構成完整資料寫入路徑,為後續驗證與讀取奠定基礎。
來源:irys.xyz
資料驗證機制:Irys 如何實現資料可驗證性(Proof of Storage / Availability)
Irys 的創新在於將資料驗證納入共識機制。每個區塊不僅確認交易,也需證明資料仍然存在且可存取。
此機制以「資料抽樣 + 雜湊驗證」運作。網路持續要求節點讀取部分資料並進行運算,驗證資料真實儲存而非偽造存在。
Irys 引入類似「儲存挖礦」機制:節點需不斷讀取並驗證資料區塊,才能參與區塊生成。資料驗證成為網路運作核心,而非附加功能。
此設計解決去中心化儲存的核心問題——如何在無需信任的前提下確認資料存在。
資料讀取與查詢:Irys 資料存取、索引與調用方式解析
資料經儲存與驗證後,用戶可透過資料識別符查詢與讀取。網路節點根據請求回傳對應資料內容。
與傳統儲存不同,Irys 資料不僅可讀取,也能被鏈上應用直接調用。智能合約可根據資料執行邏輯,無須依賴外部 API。
「可讀取 + 可運算」架構,使 Irys 在 Web3 應用中具備更強基礎設施屬性,特別適用資料驅動型場景。
資料可用性(Data Availability)如何保障:節點、共識與分區機制
Irys 以「分區生命週期(Partition Lifecycle)」機制,確保資料長期可用。
整個網路將儲存切分為多個 16TB 分區(Partition),並透過以下流程維持運作:
- 分區質押(Pledging):節點質押代幣申請參與儲存
- 分區打包(Packing):透過 Matrix Packing 將資料與節點身份綁定,防止複製攻擊
- 分區挖礦(Mining):節點持續讀取資料並參與運算,證明資料存在
- 帳本分配(Ledger Assignment):高效節點更有機會被分配真實資料並獲得更高效益
節點需持續證明其儲存能力,否則將失去獎勵甚至遭受懲罰。
此外,節點登出網路時,系統會自動重新分配資料,確保資料不因節點離線而遺失。此機制令資料可用性成為系統內生屬性。
Irys 儲存機制優勢與限制:可驗證性、成本與效能權衡
Irys 最大優勢在於「可驗證資料」。資料不再依賴信任,而是由網路持續證明存在,為高可信應用奠定基礎。
其「資料 + 執行一體化」架構,使應用可直接運用鏈上資料,減少對外部系統依賴。這對 DeFi、AI 資料等場景尤為重要。
但限制亦明顯:系統複雜度高,涉及分區、驗證與共識機制;資源需求高,如儲存與運算成本。
因此,Irys 更適合資料可信度要求高的場景,而非單純檔案儲存需求。
總結
Irys 將資料儲存、驗證與執行整合於同一架構,打造新型 Web3 資料基礎設施。其核心在於資料不僅存在,還能被證明並參與運算。
藉由分區機制與持續驗證模型,Irys 確保資料長期可用,減少對外部系統依賴。這一架構令其有別於傳統儲存協議,成為「可驗證資料層」代表。
FAQ
1.Irys 的資料為何需驗證? 因去中心化網路無法信任單一節點,需透過驗證機制確認資料真實存在。
2.什麼是 Partition(分區)? 分區是 Irys 儲存單位,每個分區用於儲存與驗證一定規模資料。
3.Matrix Packing 有何作用? 用於將資料與節點綁定,防止節點以複製資料方式作弊。
4.Irys 如何保障資料不遺失? 透過分布式儲存與分區重分配機制,即使節點登出亦能維持資料完整。
5.Irys 與傳統儲存最大差異為何? 傳統儲存重視「保存資料」,Irys 則強調「資料可驗證並可參與運算」。
分享
目錄


相關文章

Solana需要 L2 和應用程式鏈?

Sui:使用者如何利用其速度、安全性和可擴充性?

區塊鏈盈利能力和發行 - 重要嗎?

Jito 與 Marinade:Solana 流動性質押協議全面比較

Morpho 代幣經濟學深入解析:MORPHO 的應用、分配方式與價值邏輯
