本文发布之际,Amazon Web Services 再次遭遇重大宕机,致使加密基础设施广泛受损。自英国时间今日上午 8:00 起,AWS 美国东部 1 区(北弗吉尼亚数据中心)故障,导致 Coinbase 以及 Robinhood、Infura、Base、Solana 等数十家主流加密平台集体下线。
AWS 已确认 Amazon DynamoDB 和 EC2 的“错误率飙升”,这两项核心数据库与计算服务是数千家企业的基础依赖。本次实时宕机事件,鲜明印证了本文的核心观点:加密基础设施依赖中心化云服务,形成系统性脆弱性,并在压力环境下反复暴露。
时间节点极具警示意义。距离 193 亿美元强制平仓瀑布暴露交易所级基础设施失效仅十天,今日 AWS 宕机再次佐证,问题已超越单个平台,蔓延至底层云基础架构。AWS 一旦故障,连锁影响不仅波及中心化交易所,还涉及依赖中心化的“去中心化”平台与众多服务。
这并非孤例,而是反复出现的行业规律。下文分析详尽记录了 AWS 在 2025 年 4 月、2021 年 12 月、2017 年 3 月的类似宕机,每次都致主流加密服务失效。问题不是是否会再有基础设施故障,而是何时发生、由哪些因素引发。
2025 年 10 月 10-11 日强制平仓瀑布:案例分析
2025 年 10 月 10-11 日强制平仓瀑布,为基础设施失效模式提供了极具参考价值的案例。UTC 时间 20:00,一则重大地缘政治消息引发市场全面抛售。一小时内,强制平仓金额达 60 亿美元。至亚洲市场开盘,杠杆持仓总计 193 亿美元在 160 万交易账户中清零。
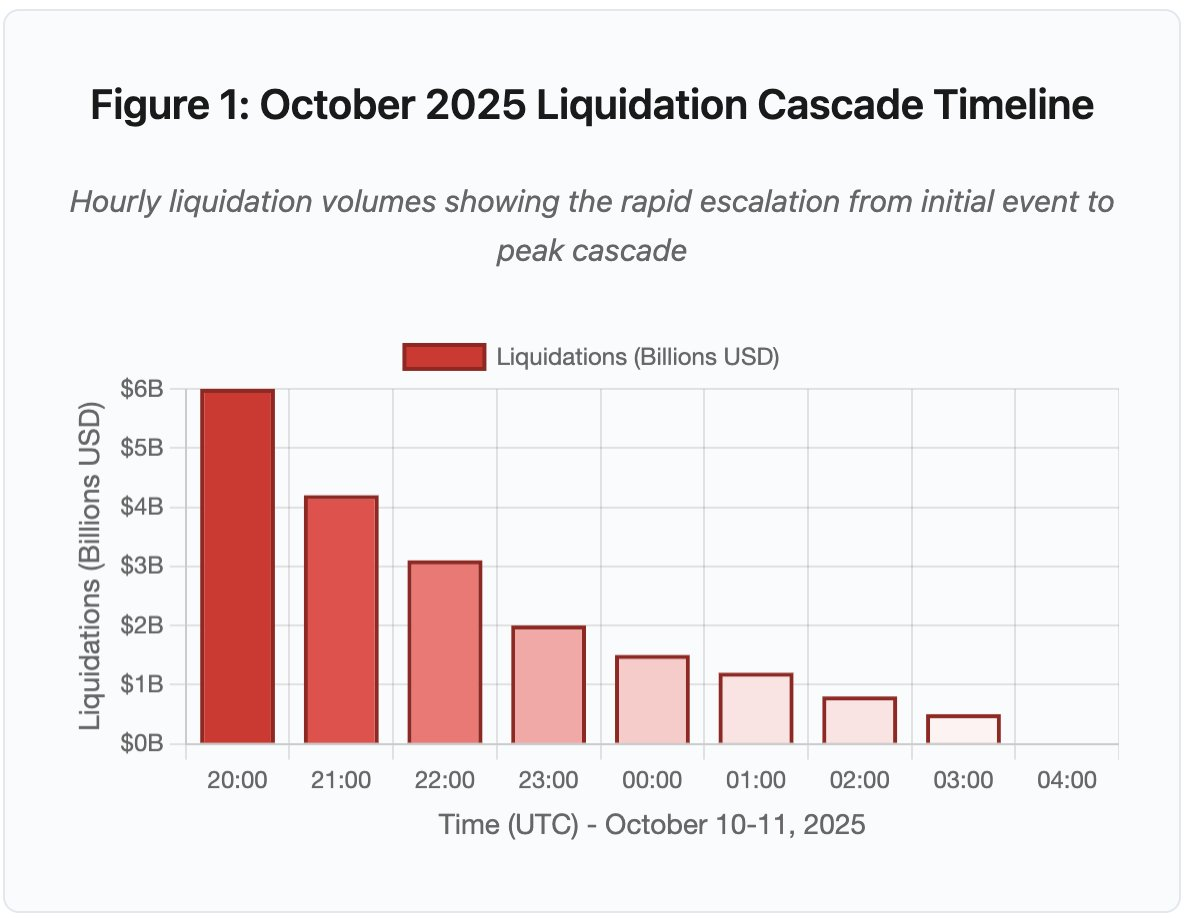
图 1:2025 年 10 月强制平仓瀑布时间线
交互式时间线图展示了强制平仓每小时的剧烈变化。首小时直接蒸发 60 亿美元,第二小时瀑布加速,规模更甚。可视化揭示:
- 20:00-21:00:初始冲击——60 亿美元平仓(红色区)
- 21:00-22:00:瀑布高峰——42 亿美元,API 限流启动
- 22:00-04:00:持续退化——91 亿美元于流动性极薄市场
- 关键拐点:API 速率限制、做市商撤离、订单簿流动性枯竭
本次事件规模至少是以往加密市场事件的十倍。历史对比突显阶梯式特征:
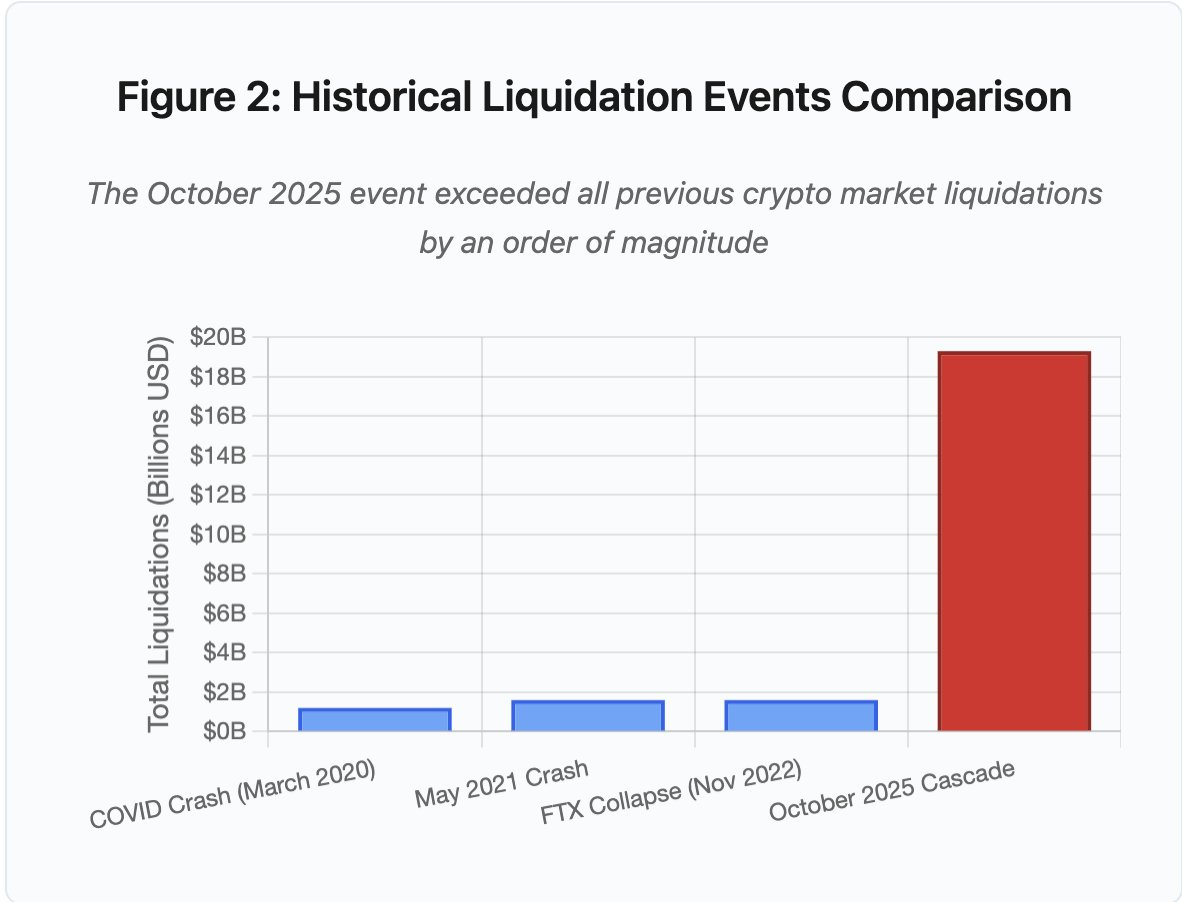
图 2:历史强制平仓事件对比
柱状图对比突出显示 2025 年 10 月的特殊性:
- 2020 年 3 月(新冠):12 亿美元
- 2021 年 5 月(暴跌):16 亿美元
- 2022 年 11 月(FTX):16 亿美元
- 2025 年 10 月:193 亿美元 ⚠️ 较前纪录高 16 倍
但强制平仓数字只是冰山一角。更值得关注的是机制:外部市场事件如何引发特定失效模式?答案揭示中心化交易所基础设施与区块链协议设计的系统性弱点。
链下失效:中心化交易所架构
基础设施过载与速率限制
交易所 API 实施速率限制以防滥用并管理服务器负载。正常运营时,这些限制既保障正常交易,也能拦截攻击行为。极端波动下,数千交易者同时调整仓位,速率限制却成为瓶颈。
CEX 将强制平仓通知限流至每秒一单,即使实际每秒需处理数千单。瀑布期间,用户无法获知真实平仓规模。第三方监控工具显示每分钟有数百笔平仓,而官方通道远低于此。
API 速率限制导致交易者在关键首小时无法调整仓位。连接请求超时,委托提交失败,止损单无法执行,仓位查询返回过时数据。基础设施瓶颈将市场事件转化为运营危机。
传统交易所按常规负载及安全裕度配置基础设施。但常规负载与压力负载差异巨大。日均成交量无法预测极端压力下的需求。瀑布期间成交量可飙升至平时百倍,仓位查询量更增至千倍,每位用户同时查询账户。
图 4.5:AWS 宕机对加密服务的影响
自动扩容云基础设施虽可缓解,但无法即时响应。新增数据库读副本需数分钟,创建新的 API 网关实例亦需数分钟。此期间,保证金系统仍以失真的订单簿价格进行仓位标记。
预言机操控与定价漏洞
瀑布期间,保证金系统关键设计浮现:部分交易所按内部现货价格计算抵押品价值,未采用外部预言机喂价。正常市况下,套利者维持平台间价格一致。但基础设施受压时,这种耦合失效。
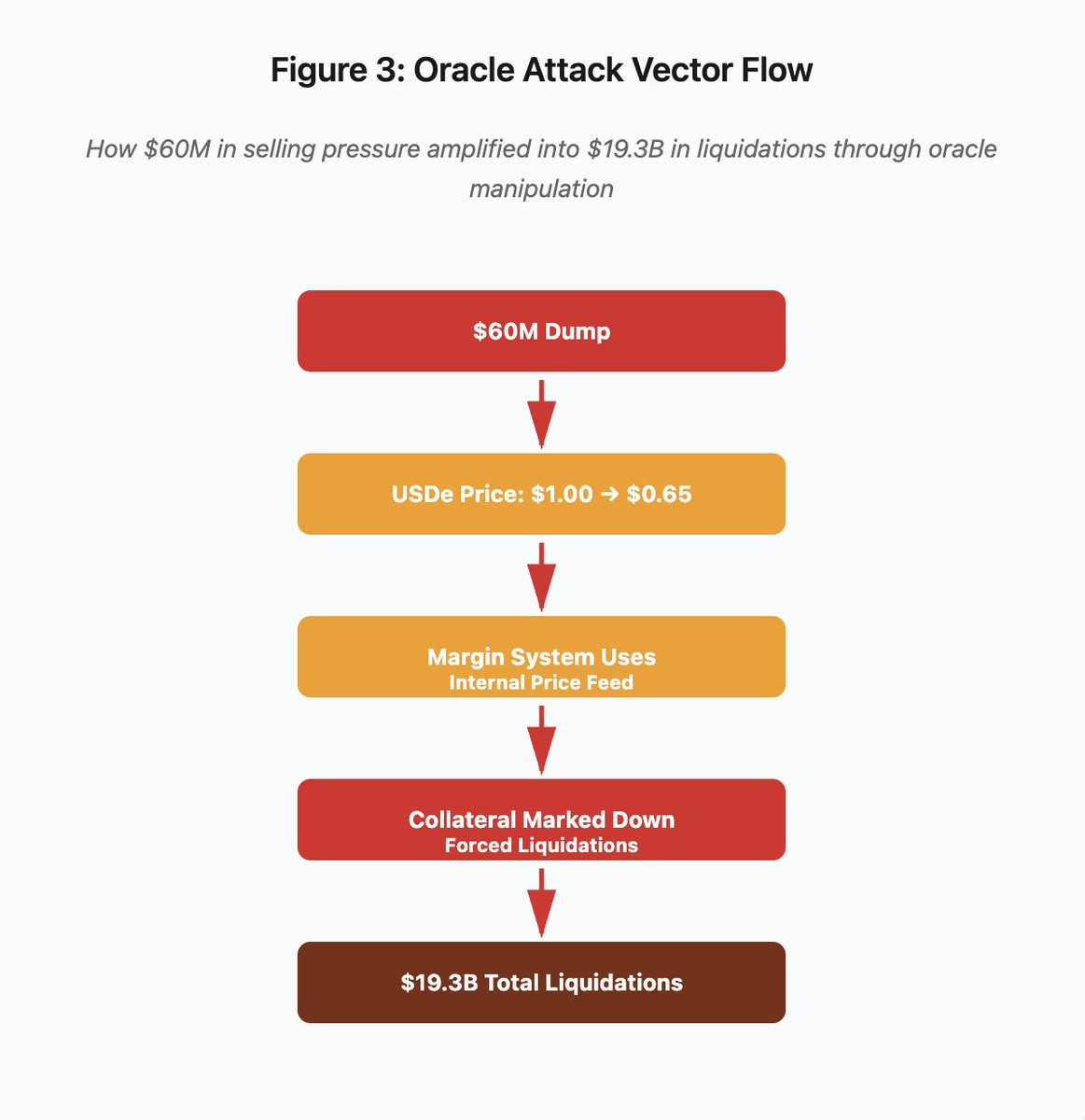
图 3:预言机操控流程图
交互式流程图展示攻击路径五个阶段:
- 初步砸盘:6000 万美元 USDe 抛压
- 价格操控:USDe 单一交易所从 $1.00 跌至 $0.65
- 预言机失效:保证金系统采用失真的内部价格
- 瀑布触发:抵押品标记下调,强制平仓启动
- 放大效应:总平仓 193 亿美元(放大 322 倍)
攻击者利用 Binance 以现货价格评估合成抵押品。当攻击者向流动性薄弱的订单簿抛售 6000 万美元 USDe,现货价从 $1.00 跌至 $0.65。保证金系统按现货价下调 USDe 抵押仓位 35%,触发爆仓和强制平仓。
强制平仓导致更多账户在同一流动性枯竭市场被迫卖出,价格进一步下跌。保证金系统观察到更低价格,继续下调仓位,形成反馈环,将 6000 万美元抛压放大至 193 亿美元强制平仓。

图 4:强制平仓反馈环路
循环反馈图说明瀑布自我强化机制:
价格下跌 → 触发平仓 → 被迫卖出 → 进一步下跌 → [循环重复]
如果预言机系统设计合理,此机制将无法成立。若 Binance 采用多平台加权均价(TWAP),瞬时操控不会影响抵押品估值。若用 Chainlink 等多源预言机聚合价格,攻击也无法奏效。
四天前的 wBETH 事件同样暴露类似漏洞。Wrapped Binance ETH(wBETH)应与 ETH 保持 1:1 兑换。瀑布期间流动性枯竭,wBETH/ETH 现货出现 20% 折价。保证金系统据此下调 wBETH 抵押品,导致原本全额抵押的账户也被强制平仓。
自动减仓(ADL)机制
市场价格无法执行平仓时,交易所通过 Auto-Deleveraging 机制,将亏损社交化分摊至盈利交易者。ADL 按当前价格强制平掉盈利仓位,以弥补爆仓仓位的亏损。
瀑布期间,Binance 在多交易对启用 ADL。盈利多头仓位被强制平掉,原因并非自身风控失误,而是其他账户爆仓导致系统性亏损。
ADL 体现了中心化衍生品交易的根本架构选择。交易所保证自身不亏损,意味着亏损必须由以下方式吸收:
- 保险基金(交易所专设的风险准备金)
- ADL(强制平掉盈利仓位)
- 损失社会化(分摊至所有用户)
保险基金与未平仓头寸的比例决定 ADL 频率。2025 年 10 月 Binance 保险基金约 20 亿美元,对 BTC、ETH、BNB 永续合约未平仓 40 亿美元,仅有 50% 覆盖。但瀑布期间,总未平仓头寸突破 200 亿美元,保险基金远远无法覆盖缺口。
瀑布后,Binance 宣布当 BTC、ETH、BNB USDⓈ-M 合约未平仓头寸低于 40 亿美元时,不启用 ADL。这带来激励机制:交易所可扩大保险基金以避免 ADL,但这会占用可盈利的资金。
链上失效:区块链协议局限
柱状图对比各类事件的宕机时长:
- Solana(2024 年 2 月):5 小时——投票吞吐瓶颈
- Polygon(2024 年 3 月):11 小时——验证节点版本不一致
- Optimism(2024 年 6 月):2.5 小时——排序器超载(空投)
- Solana(2024 年 9 月):4.5 小时——交易垃圾攻击
- Arbitrum(2024 年 12 月):1.5 小时——RPC 服务商故障
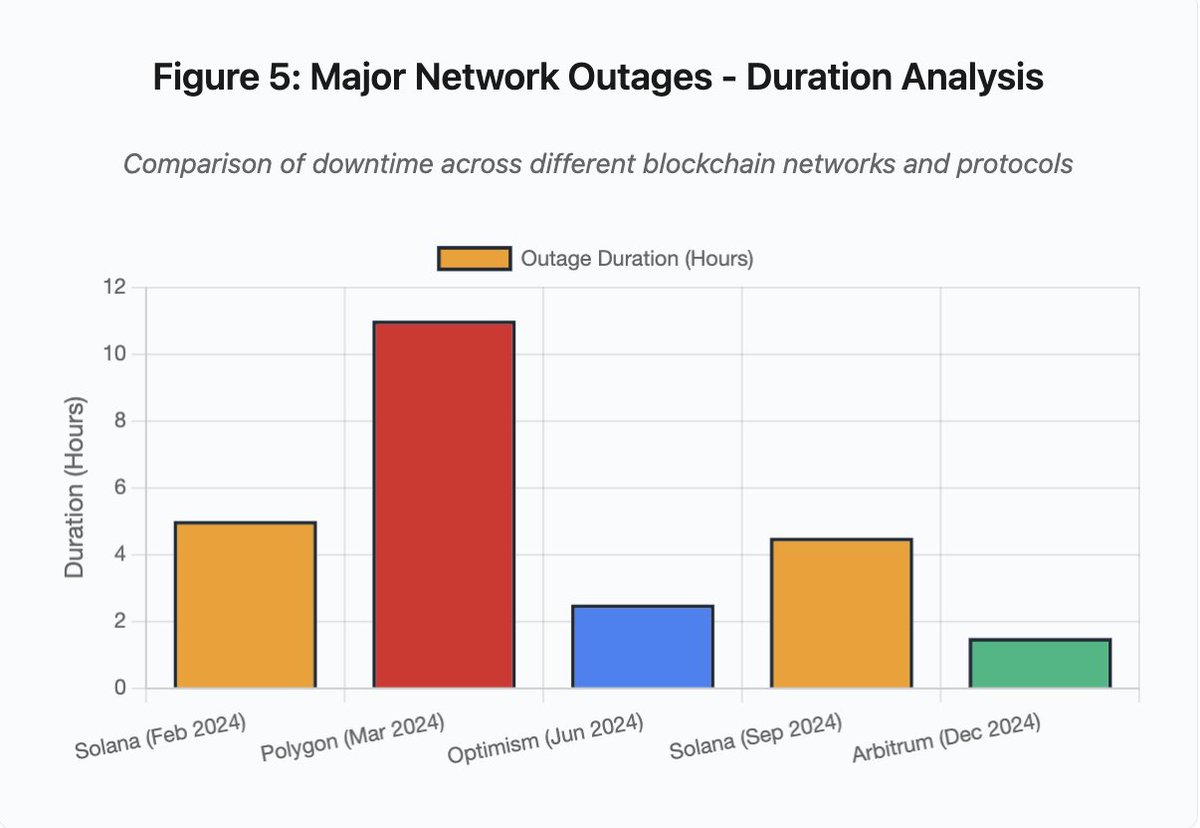
图 5:主网宕机时长分析
Solana:共识瓶颈
Solana 在 2024-2025 年多次宕机。2024 年 2 月故障约持续 5 小时,9 月故障持续 4-5 小时。根本原因一致:网络在垃圾攻击或极端高负载下无法处理交易量。
图 5 细节:Solana 的宕机(2 月 5 小时、9 月 4.5 小时)凸显网络韧性在压力下反复失效。
Solana 架构追求高吞吐。理想情况下,网络每秒处理 3,000-5,000 笔交易,区块秒级终结,性能远超 Ethereum。但在压力事件下,这种优化带来新漏洞。
2024 年 9 月宕机源于垃圾交易泛滥,验证者投票机制被压垮。Solana 验证者需投票以实现共识。正常运行时,验证者优先处理投票交易以保障共识进展。但协议此前将投票交易与普通交易无差别对待。
当内存池被数百万垃圾交易挤满,验证者难以传播投票交易。投票不足,区块无法终结,链被迫停止。用户的待处理交易卡在内存池,新交易提交失败。
StatusGator 记录了 2024-2025 年 Solana 多次服务中断,而官方未公开承认。这造成信息不对称。用户难以区分本地连接问题与全网故障。第三方监测服务提升了透明度,但平台应设立完善的状态信息页。
Ethereum:Gas 费激增
Ethereum 在 2021 年 DeFi 热潮期间出现极端 gas 费暴涨。简单转账费用高达 $100,复杂智能合约交互达 $500-1000。高费用令小额交易难以进行,同时引入新的攻击向量——MEV 提取。
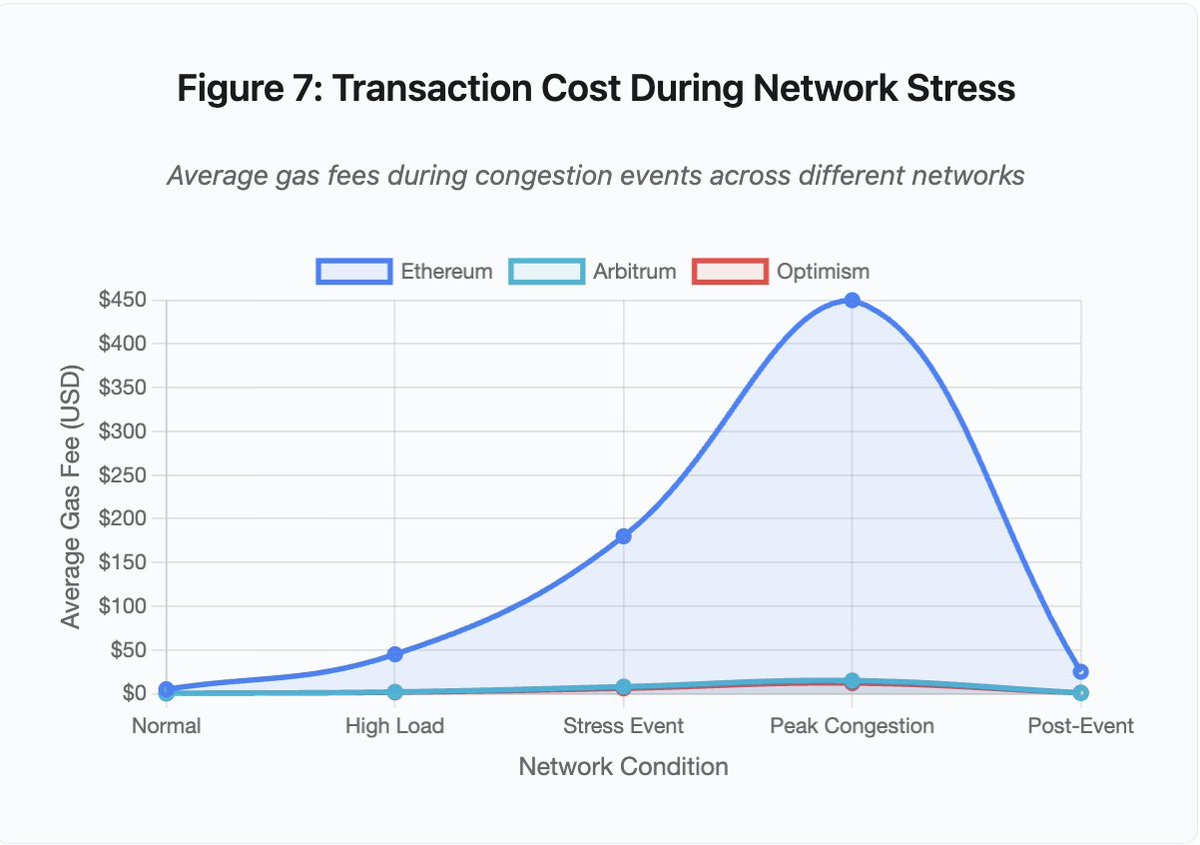
图 7:网络压力下的交易费用
折线图清晰展现压力事件期间各网络 gas 费激增:
- Ethereum:$5(正常)→ $450(高峰)——增长 90 倍
- Arbitrum:$0.50 → $15——增长 30 倍
- Optimism:$0.30 → $12——增长 40 倍
即使 Layer2 方案,也会在高峰期间出现费用暴涨,只是基数较低。
最大可提取价值(MEV)指验证者通过重新排序、包含或排除交易获利。在高 gas 费环境下,MEV 变得极为诱人。套利者竞相抢先 DEX 大额交易,清算机器人争先平掉不足抵押仓位,形成 gas 费竞价。
用户若想在拥堵时确保交易被包含,需与 MEV 机器人竞价。有时交易费甚至高于交易额。想领取 $100 空投?需支付 $150 gas 费。想追加抵押防止爆仓?需与机器人竞价 $500 争取优先。
Ethereum 的 gas 限制决定每区块的总计算量。拥堵时用户为稀缺区块空间竞价,费用市场如设计般运作:高价优先。设计导致网络高使用时成本高涨,恰逢用户最需要访问时却最难成交。
Layer2 方案试图将计算移至链下,通过定期结算继承 Ethereum 安全性。Optimism、Arbitrum 等 rollup 将数千交易链下处理,压缩后提交至 Ethereum。这架构正常运行时显著降低单笔交易成本。
Layer2:排序器瓶颈
Layer2 也引入新瓶颈。Optimism 在 2024 年 6 月遭遇 25 万地址同时领取空投,排序器(负责交易排序并提交 Ethereum)被压垮,用户数小时无法提交交易。
此次故障揭示链下计算并未消除基础设施需求。排序器需处理、排序、执行交易并生成欺诈证明或 ZK 证明提交 Ethereum。极端流量下,排序器面临与独立区块链相同的扩展难题。
多家 RPC 服务商必须保持可用。主服务商故障时,用户应自动切换至备选。Optimism 宕机期间,部分 RPC 服务商仍在运行,部分失效。默认失效服务商的钱包无法交互,链本身仍在线。
AWS 宕机反复揭示加密生态基础设施集中风险:
- 2025 年 10 月 20 日(今日):美国东部 1 区宕机,Coinbase、Venmo、Robinhood、Chime 受影响。AWS 已承认 DynamoDB、EC2 错误率飙升。
- 2025 年 4 月:区域宕机同时影响 Binance、KuCoin、MEXC,多家主流交易所 AWS 组件失效。
- 2021 年 12 月:美国东部 1 区宕机,Coinbase、Binance.US、“去中心化”交易所 dYdX 宕机 8-9 小时,影响 Amazon 仓库及主流流媒体服务。
- 2017 年 3 月:S3 宕机致 Coinbase、GDAX 无法登录 5 小时,互联网大范围受损。
模式非常明确:这些交易所将关键组件托管于 AWS。一旦 AWS 区域宕机,多家主流交易所和服务同步失效。宕机期间,用户无法访问资金、执行交易或调整仓位——而此时市场波动可能迫切需要即时操作。
Polygon:共识版本不一致
Polygon(原 Matic)2024 年 3 月出现 11 小时宕机。问题根源在于验证节点版本不一致,部分节点使用旧版软件,部分已升级,新旧版本对状态转换计算存在差异。
图 5 细节:Polygon 事件(11 小时)为分析中最长宕机,凸显共识故障的严重性。
验证者对正确状态无法达成一致,导致无法出块。旧版节点拒绝新版节点出块,新版节点拒绝旧版出块,形成死锁。
解决需协调验证者集体升级。宕机期间需联系每位节点运营者,部署正确版本并重启。在去中心化网络中,协调升级需数小时乃至数天。
硬分叉通常采用区块高度触发,所有节点在指定高度前升级,确保同步激活。但需提前协调。渐进升级则易导致 Polygon 本次版本不一致宕机。
架构权衡
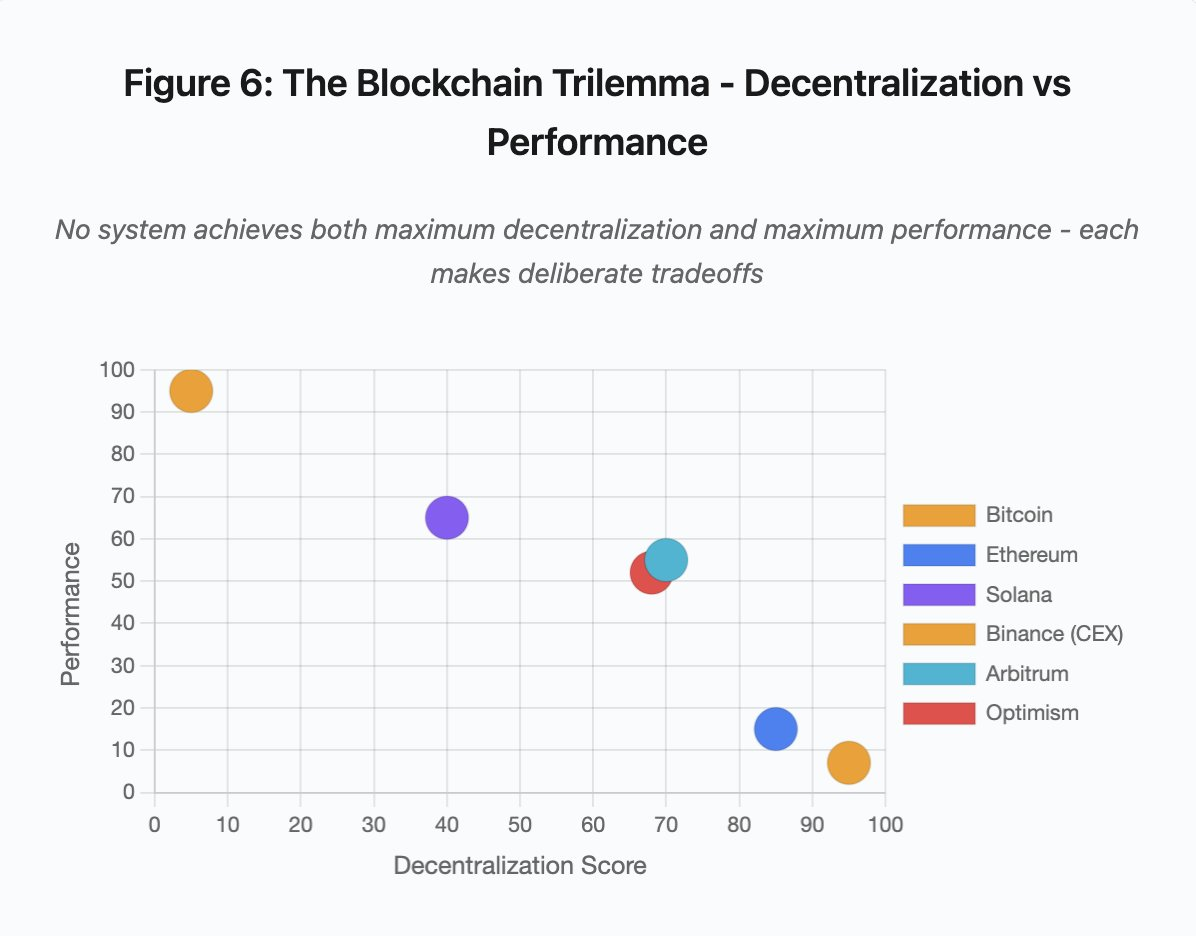
图 6:区块链三难——去中心化与性能权衡
散点图将不同系统映射于两大维度:
- Bitcoin:高去中心化,低性能
- Ethereum:高去中心化,中等性能
- Solana:中等去中心化,高性能
- Binance(CEX):极低去中心化,极高性能
- Arbitrum/Optimism:中高去中心化,中等性能
关键洞察:没有系统能同时实现最大去中心化与最大性能。每种设计都是针对不同需求做出权衡。
中心化交易所通过架构简化实现低延迟。撮合引擎微秒级处理订单,状态存于中心数据库,无需共识协议,无额外开销。但这种简化带来单点故障,压力环境下失效可级联传导。
去中心化协议将状态分布于验证者,消除单点故障。高吞吐链即使宕机也仅暂时失活,用户资金安全。但分布式共识需验证者达成一致,增加计算开销。验证者版本不兼容或流量过载时,共识可能暂时停滞。
增加副本提升容错性但提高协调成本。拜占庭容错系统每增一验证者,通讯开销增加。高吞吐架构通过优化验证者通讯降低开销,实现高性能但对部分攻击模式更敏感。安全导向架构优先验证者多样性与共识强韧性,牺牲底层吞吐以换取韧性。
Layer2 方案尝试通过分层设计兼得两者,继承 Ethereum 安全性(L1 结算),链下计算实现高吞吐。但排序器与 RPC 层引入新瓶颈,说明架构复杂度带来新失效模式。
扩展性始终是根本难题
这些事件揭示出系统按常规负载配置,压力下灾难性失效的规律。Solana 能够应对日常流量,但在交易量暴增一万倍时崩溃。Ethereum gas 费用本可控,DeFi 采用后即拥堵。Optimism 正常运行,25 万地址同时空投即宕机。Binance API 平时运行顺畅,瀑布期间限流成致命瓶颈。
2025 年 10 月事件在交易所层面体现了这一动态。正常时,Binance 的 API 速率限制和数据库连接足以应对需求。但瀑布期间,所有交易者同时调整仓位,这些限制成为瓶颈。保证金系统为保护交易所而设计强制平仓,却在最关键时刻加剧危机,制造强制卖方。
自动扩容难以应对阶跃式激增。新增服务器需数分钟,期间保证金系统按失真订单簿价格标记仓位。等新容量上线,瀑布已蔓延。
为极端压力事件超额配置,日常运营成本高昂。交易所运营者按典型负载优化,偶发失效被视为经济合理。宕机成本外部化给用户,导致他们在关键行情期间爆仓、卡单或无法访问资金。
基础设施优化建议
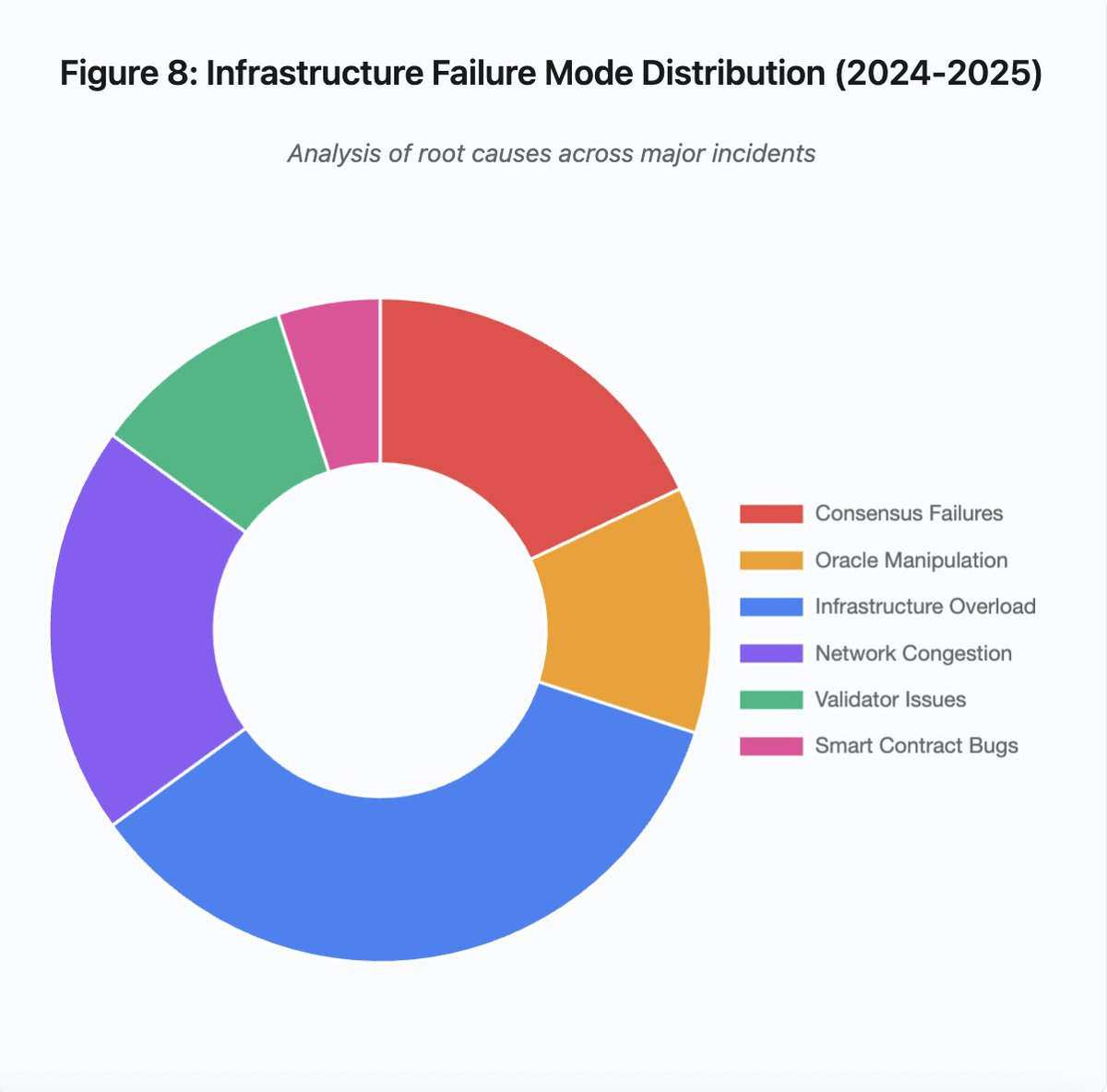
图 8:2024-2025 年基础设施失效模式占比
饼图揭示根本原因分布:
- 基础设施过载:35%(最常见)
- 网络拥堵:20%
- 共识失效:18%
- 预言机操控:12%
- 验证者问题:10%
- 智能合约漏洞:5%
多项架构调整可降低失效频率与影响,但每项均需权衡:
1. 定价与强制平仓系统分离
10 月事件部分源于保证金计算与现货价格耦合。若采用换算比率而非现货价,wBETH 错价可避免。广义而言,关键风控系统不应依赖易被操控的市场数据。多源聚合与 TWAP 计算的独立预言机系统,可带来更强韧的价格喂价。
2. 超额配置与冗余基础设施
2025 年 4 月 AWS 宕机影响 Binance、KuCoin、MEXC,暴露基础设施依赖风险。将关键组件部署于多云供应商,运营复杂度与成本提升,但可消除相关故障。Layer2 网络应配置多 RPC 服务商并自动切换。日常运营时多余开支虽显浪费,但高峰期可避免数小时宕机。
3. 强化压力测试与容量规划
系统“正常即可,失效即垮”的模式说明压力测试不足。应以常规负载百倍进行压力模拟。开发阶段发现瓶颈成本远低于实战宕机。然真实流量难以完全模拟,实际崩盘时用户行为远异于测试。
未来路径
超额配置最可靠,但与经济激励冲突。为应对罕见事件配置十倍冗余,日常运营成本极高,只为防止年内一次故障。除非灾难性失效带来足够高成本,系统才会为压力环境配置冗余,否则仍将压力下失效。
监管压力或将推动变革。若法规要求 99.9% 在线率或限制最大宕机时长,交易所需超额配置。但监管往往事后出台,难以预防。Mt.Gox 2014 年崩盘后,日本才建立加密交易所监管。2025 年 10 月瀑布事件或将引发类似监管响应。最终是规定结果(最大可接受宕机、强制平仓最大滑点)还是指定具体方案(指定预言机、断路器阈值),尚未明朗。
根本难题在于,这些系统全天候运作于全球市场,却依赖按传统办公时间设计的基础设施。压力事件发生在凌晨 2 点,团队临时修复,用户损失持续扩大。传统市场压力下停市,加密市场则直接崩溃。这究竟是特色还是缺陷,取决于角度与立场。
区块链系统在短时间内取得了技术突破。全网数千节点分布式共识是工程壮举。但压力环境下的可靠性,需从原型架构迈向生产级基础设施。这一转型既需资金,也需将韧性优先于功能迭代。
难点在于牛市期间优先增长而非韧性,人人赚钱,宕机似乎只是旁人的问题。下轮周期压力再临,新的漏洞必然出现。行业能否从 2025 年 10 月事件吸取教训,或继续重复模式,仍未可知。历史表明,下一次关键漏洞将通过又一次数十亿美元压力事件显现。
分析基于公开市场数据及平台信息。观点仅代表本人,不代表任何机构。
免责声明:
- 本文转载自 [yq_acc],著作权归原作者 [yq_acc] 所有。如有异议请联系 Gate Learn 团队,将及时处理。
- 免责说明:本文观点仅代表作者立场,不构成任何投资建议。
- 其他语种译文由 Gate Learn 团队完成,未经授权禁止复制、分发或抄袭译文。
分享
目录


相关文章

不可不知的比特币减半及其重要性

如何选择比特币钱包?


Master Protocol:激活 BTC 生息潜力

CKB:闪电网络促新局,落地场景需发力
