BlockSec: 人工智能尚无法替代人类进行智能合约审计
Tap Chi Bitcoin
区块链安全公司BlockSec已对由OpenAI和Paradigm开发的名为EVMBench的智能合约AI审计评估标准进行了重新测试。结果显示,面对实际的攻击场景,AI机器人表现明显不佳。
研究团队扩大了测试环境,增加了更多模型配置,同时加入了近期发生的新的安全事件——这些数据此前未曾出现在AI模型的训练数据中。
虽然AI仍无法取代安全专家,但报告强调,机器智能可以自然地作为人类代码审查的辅助工具。
EVMBench初步结果可能过于乐观
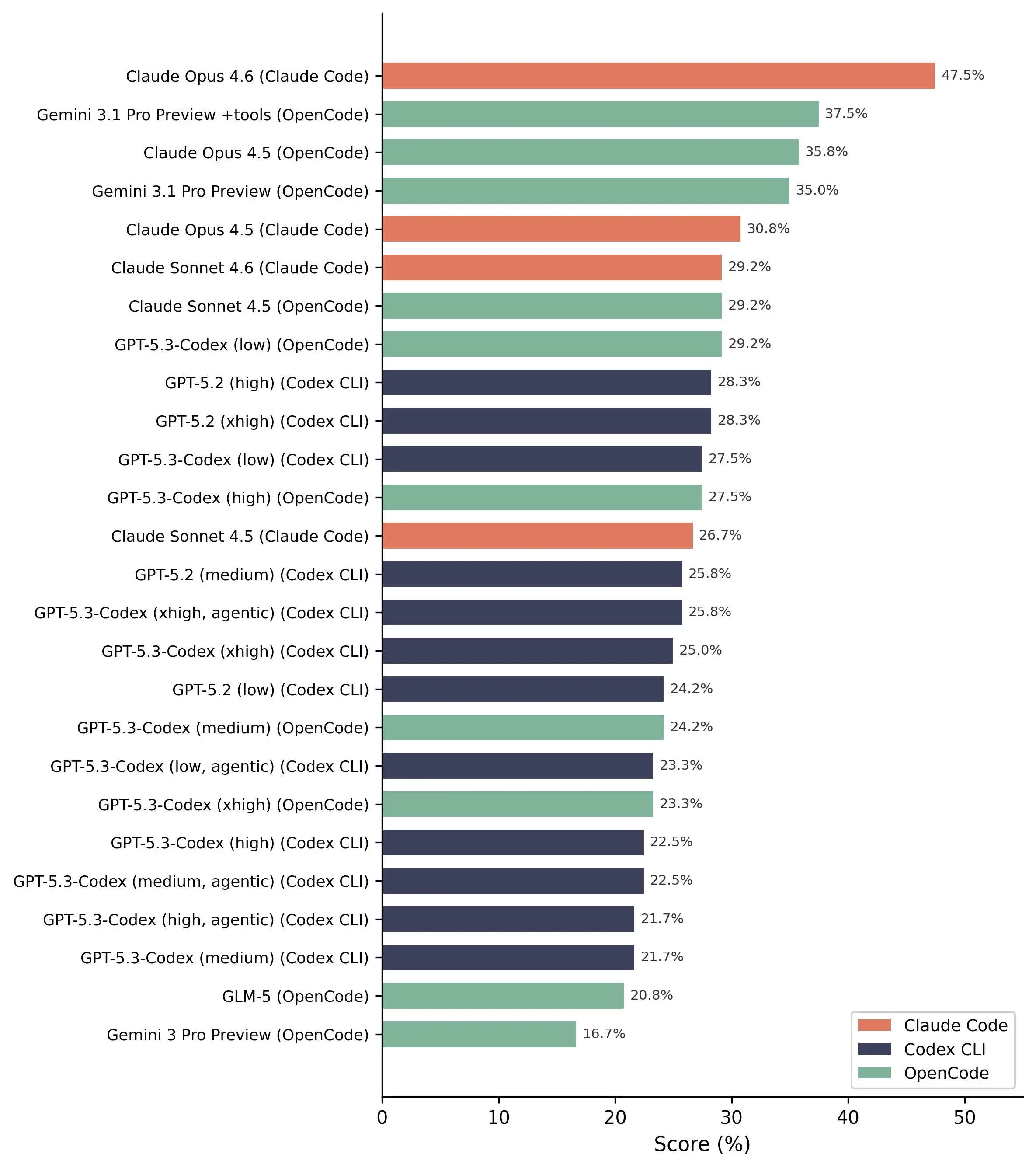
此前,EVMBench评估了智能合约安全任务,如漏洞检测、修复和利用,结果被认为非常令人印象深刻。报告显示,AI在120个经过筛选的Code4rena审计样本中,能成功利用72%,并检测出约45%的漏洞。
然而,BlockSec认为,最初的测试条件可能导致结果偏差。联合创始人周亚金表示,团队在使用更多配置和22个实际攻击事件重新测试后,AI的成功利用率为0%。
扩展配置并排除“数据污染”
研究将模型配置数量从14增加到26,通过灵活组合不同“脚手架”与机器人,而不再局限于各供应商的生态系统。研究团队指出,旧的方法难以区分模型性能是源于模型能力还是架构优势。
此外,BlockSec还质疑“数据污染”现象,即EVMBench使用了已公开的漏洞——这些漏洞可能已包含在AI的训练数据中。为此,团队在2026年2月之后发生的22个安全事件上进行了测试,确保超出模型的“知识窗口”。
AI在实际攻击中完全失败
最引人注目的结果是:在110组代理与漏洞的测试中(5个代理面对22个场景),没有任何一次完整的利用成功。这表明,即使是目前最先进的AI,也距离进行实际攻击还很遥远。
不过,在漏洞检测方面,结果仍相对积极。Claude Opus 4.6模型在实际检测中表现最佳,成功发现了13个中的20个漏洞。
常见、熟悉的漏洞AI较易检测,但更复杂的案例几乎完全被遗漏。
未来是AI与人类的合作
研究得出结论:AI尚不能取代人类进行安全审计,更重要的问题是双方如何高效协作。
AI在覆盖范围和大规模扫描能力方面具有优势,而人类在深度分析、协议理解和对抗推理方面更具优势。这两者相辅相成。
BlockSec认为,正确的方向不是用AI取代人类,而是建立双方合作的模型,以实现更全面的审计效果。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论