Kurzfassung
- OpenAI hat GPT-5.4 Mini und Nano vorgestellt, zwei schnellere und günstigere Modelle, die für hochvolumige KI-Arbeitslasten entwickelt wurden.
- Die Modelle opfern etwas an Genauigkeit zugunsten von Geschwindigkeit und Kosten, um Aufgaben wie Kundensupport und automatisierte Workflows zu erleichtern.
- Entwickler können jetzt hybride KI-Systeme betreiben, bei denen ein Flaggschiff-Modell Aufgaben plant, während kleinere Modelle den Großteil der Arbeit übernehmen.
OpenAI lässt nicht nach. Weniger als zwei Wochen nach der Einführung von GPT-5.4—das selbst nur zwei Tage nach GPT-5.3 veröffentlicht wurde—brachte das Unternehmen am Dienstag zwei weitere Modelle heraus: GPT-5.4 Mini und GPT-5.4 Nano.
Diese sind keine abgespeckten Versionen des Flaggschiff-Modells—sie sind speziell für Arbeiten konzipiert, bei denen es keine Option ist, eine halbe Minute auf eine Antwort zu warten.
OpenAI bezeichnet sie als seine „leistungsfähigsten kleinen Modelle bisher“ und sagt, dass GPT-5.4 Mini mehr als doppelt so schnell ist wie GPT-5 Mini. Wenn Sie jemals einen Programmierassistenten 45 Sekunden lang nachdenken gesehen haben, bevor er drei Zeilen Code bearbeitet, verstehen Sie den Reiz eines schnellen Modells.
Wir stellen GPT-5.4 mini und nano vor, unsere bisher leistungsfähigsten kleinen Modelle.
GPT-5.4 mini ist mehr als doppelt so schnell wie GPT-5 mini. Optimiert für Programmierung, Computeranwendungen, multimodales Verständnis und Subagenten.
Für leichtere Aufgaben ist GPT-5.4 nano unser kleinstes und günstigstes… pic.twitter.com/cdp5HWtM2M
— OpenAI Entwickler (@OpenAIDevs) 17. März 2026
Warum sollte jemand absichtlich ein weniger genaues Modell veröffentlichen? Die kurze Antwort: Weil Genauigkeit nicht immer der Engpass ist. Wenn Sie einen Kundenservice-Chatbot betreiben, der den ganzen Tag die gleichen 200 Fragen beantwortet, brauchen Sie nicht das Modell, das bei Chemie-Examen auf Doktorandenniveau die beste Punktzahl erzielt. Sie brauchen das, das in weniger als einer Sekunde antwortet und nur einen Bruchteil eines Cents pro Antwort kostet. Dafür sind diese Modelle gebaut.
Das bedeutet jedoch nicht, dass diese Modelle dumm oder unzuverlässig sind. In Programmierbenchmarks erzielte GPT-5.4 Mini 54,4 % auf SWE-Bench Pro—einem Test, der die Fähigkeit eines Modells misst, echte GitHub-Probleme zu beheben—im Vergleich zu 45,7 % für das alte GPT-5 Mini und 57,7 % für das vollständige GPT-5.4.
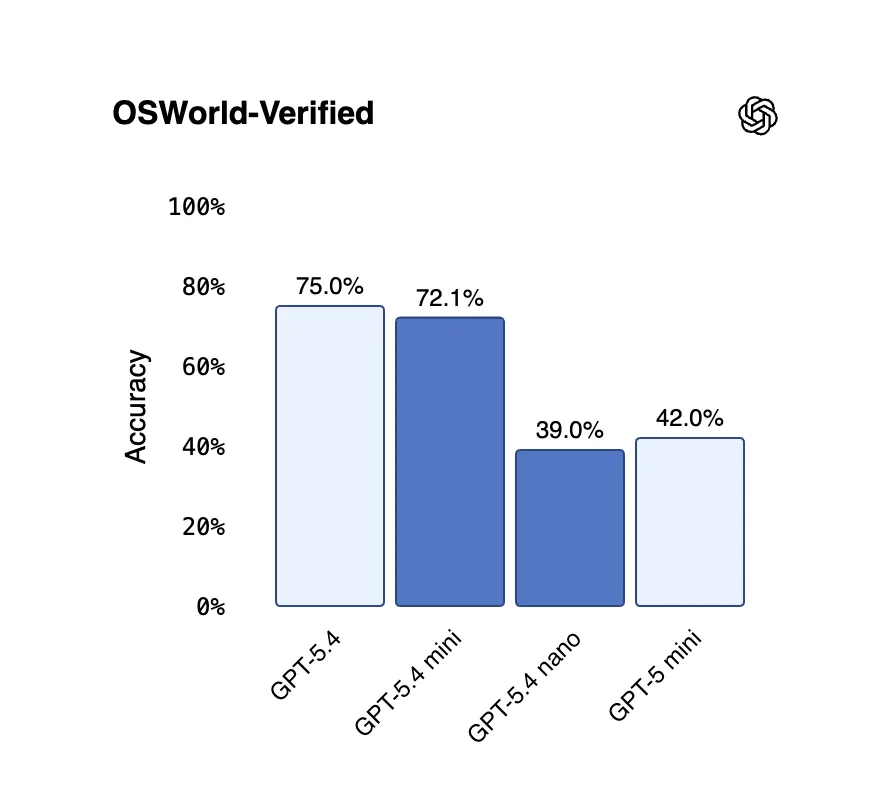
Auf OSWorld-Verified, einem Test, bei dem die Fähigkeit eines Modells geprüft wird, einen Desktop-Computer anhand von Screenshots zu bedienen, erreichte Mini 72,1 %, knapp hinter dem Flaggschiff mit 75,0 %—und beide übertreffen den menschlichen Durchschnitt von 72,4 %. GPT-5.4 Nano erzielt dagegen 52,4 % auf SWE-Bench Pro und 39,0 % auf OSWorld—niedriger als Mini, aber immer noch ein bedeutender Fortschritt gegenüber früheren Nano-Modellen.
„GPT-5.4 stellt einen Fortschritt für sowohl Mini- als auch Nano-Modelle in unseren internen Bewertungen dar“, sagte Perplexity-CTO Jerry Ma nach Tests beider Modelle. „Mini bietet starke Argumentationsfähigkeiten, während Nano reaktionsschnell und effizient für Live-Konversations-Workflows ist.“
Anstatt jede einzelne Aufgabe durch ein teures Flaggschiff-Modell zu leiten, können Sie jetzt Systeme aufbauen, bei denen das große Modell plant und koordiniert, während kleinere Modelle die eigentliche Arbeit parallel erledigen—hier eine Codebasis durchsuchen, dort ein Dokument lesen oder an anderer Stelle ein Formular verarbeiten. Wie wir in unserem Vergleich GPT-5.4 vs. Grok 4.20 gesehen haben, ist es genauso wichtig, wo das Modell im Workflow sitzt, wie welches Modell Sie wählen.
GPT-5.4 Mini kostet 0,75 USD pro Million Eingabetokens und 4,50 USD pro Million Ausgabetokens über die API. GPT-5.4 Nano ist noch günstiger: 0,20 USD pro Million Eingabetokens und 1,25 USD pro Million Ausgabetokens—ein Preis, der es Startups ermöglicht, täglich eine große Anzahl von Anfragen finanziell zu bewältigen. Zum Vergleich: Nano ist etwa viermal günstiger bei Eingaben als Mini.
Für reguläre ChatGPT-Nutzer ist GPT-5.4 Mini heute für Free- und Go-Nutzer über die „Denken“-Option im Plus-Menü verfügbar. Bezahlte Abonnenten, die ihre GPT-5.4-Geschwindigkeitslimits erreichen, werden automatisch auf Mini umgestellt. GPT-5.4 Nano ist vorerst nur über die API verfügbar—OpenAI positioniert es klar als Entwicklerwerkzeug, nicht als Verbraucherprodukt.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
