
Autor | ZeR0 Jun Da, Zhi Dong Xi
Redakteur | Mo Ying
Xin Dong Xi Las Vegas 5. Januar Bericht, gerade hat Nvidia-Gründer und CEO Huang Renxun auf der Internationalen Consumer Electronics Show CES 2026 seine erste Keynote im Jahr 2026 gehalten. Huang Renxun trug wie gewohnt Lederjacke und kündigte innerhalb von 1,5 Stunden acht bedeutende Ankündigungen an, von Chips, Racks bis hin zu Netzdesigns, und gab eine tiefgehende Einführung in die gesamte neue Generation der Plattform.

Im Bereich der beschleunigten Berechnung und KI-Infrastruktur veröffentlicht Nvidia den NVIDIA Vera Rubin POD AI Supercomputer, NVIDIA Spectrum-X Ethernet-gekapselte optische Bauelemente, NVIDIA Inferenz-Kontext-Interner Speicherplattform, sowie den NVIDIA DGX SuperPOD basierend auf DGX Vera Rubin NVL72.

Der NVIDIA Vera Rubin POD verwendet sechs eigens entwickelte Nvidia-Chips, die CPU-, GPU-, Scale-up-, Scale-out-, Speicher- und Verarbeitungskapazitäten abdecken. Alle Komponenten sind koordiniert gestaltet, um fortschrittliche Modelle zu erfüllen und die Rechenkosten zu senken.
Der Vera CPU basiert auf der maßgeschneiderten Olympus-Kernarchitektur, Rubin GPU bringt nach Einführung des Transformer-Engines eine NBFP4-Inferenzleistung von bis zu 50PFLOPS, mit NVLink-Bandbreite von bis zu 3,6TB/s pro GPU, unterstützt die dritte Generation der allgemeinen vertraulichen Berechnung (erster rack-level TEE), und schafft eine vollständige vertrauenswürdige Ausführungsumgebung für CPU und GPU über Domänen hinweg.

Alle Chips sind bereits in Produktion, Nvidia hat das gesamte NVIDIA Vera Rubin NVL72 System verifiziert, Partner haben bereits begonnen, ihre internen KI-Modelle und Algorithmen zu betreiben. Das gesamte Ökosystem bereitet sich auf die Bereitstellung von Vera Rubin vor.
Bei den weiteren Ankündigungen optimiert NVIDIA Spectrum-X optische Bauelemente mit Ethernet-Kapselung erheblich in Bezug auf Energieeffizienz und Betriebszeit; die NVIDIA Inferenz-Kontext-Interner Speicherplattform definiert den Speicher-Stack neu, um redundante Berechnungen zu reduzieren und die Inferenzleistung zu steigern; das DGX SuperPOD auf Basis von DGX Vera Rubin NVL72 reduziert die Token-Kosten für große MoE-Modelle auf 1/10.

Im Bereich der offenen Modelle kündigte Nvidia die Erweiterung der Open-Source-Modellfamilie an, mit neuen Modellen, Datensätzen und Bibliotheken, darunter die NVIDIA Nemotron-Open-Source-Modellreihe mit neuen Agentic RAG-Modellen, Sicherheitsmodellen, Sprachmodellen sowie einer brandneuen offenen Modellplattform für alle Robotertypen. Huang Renxun gab dazu jedoch keine detaillierten Informationen im Vortrag.
Im Bereich Physische KI ist die Zeit für ChatGPT im Bereich Physische KI gekommen, Nvidia’s Full-Stack-Technologie ermöglicht es dem globalen Ökosystem, Branchen durch KI-gesteuerte Robotik zu verändern; die umfangreiche KI-Toolkit-Bibliothek von Nvidia, inklusive der neuen Alpamayo-Open-Source-Modellkombination, ermöglicht es der globalen Verkehrsbranche, schnell sichere L4-Fahrten zu realisieren; die NVIDIA DRIVE Autonomes Fahrsystem ist bereits in Produktion, verbaut in allen neuen Mercedes-Benz CLA, für L2++ KI-gesteuertes Fahren.

01.Neue KI-Supercomputer: 6 Eigenentwickelte Chips, Rechenleistung pro Rack bis zu 3,6EFLOPS
Huang Renxun ist der Ansicht, dass alle 10 bis 15 Jahre die Computerbranche eine umfassende Neugestaltung erlebt. Doch diesmal geschehen zwei Plattform-Revolutionen gleichzeitig: vom CPU zum GPU, vom „Programmier-Software“ zum „Trainings-Software“. Beschleunigte Berechnung und KI rekonstruieren den gesamten Rechen-Stack. Die letzten zehn Jahre mit einem Wert von 10 Billionen US-Dollar in der Rechenindustrie durchlaufen eine Modernisierung.
Gleichzeitig steigt die Nachfrage nach Rechenleistung rapide. Die Modellgrößen wachsen jährlich um das Zehnfache, die Token-Anzahl für Denkprozesse um das Fünfzehnfache, während die Kosten pro Token jährlich um das Zehnfache sinken.
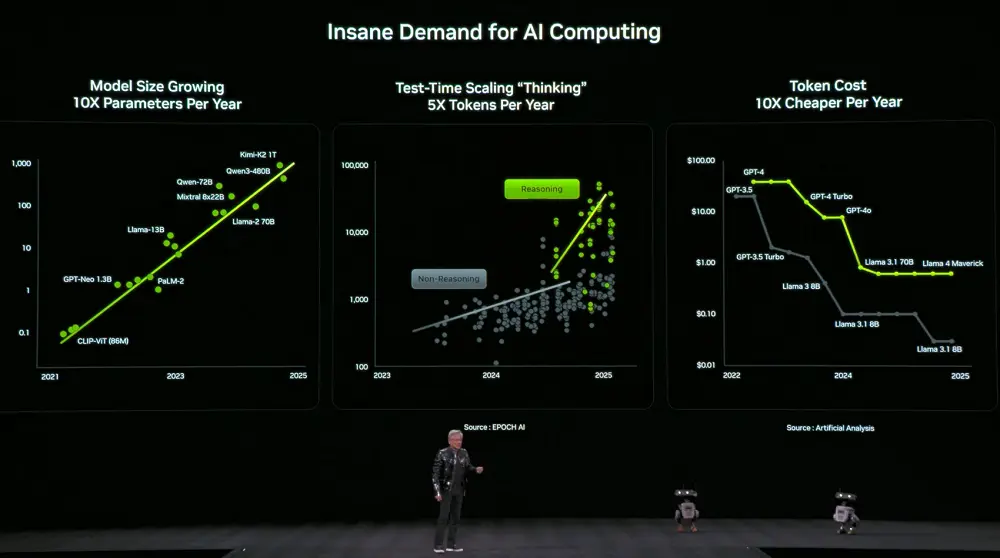
Um dieser Nachfrage gerecht zu werden, kündigt Nvidia an, jährlich neue Rechenhardware zu veröffentlichen. Huang Renxun verrät, dass Vera Rubin bereits vollständig in Produktion ist.
Der neue KI-Supercomputer NVIDIA Vera Rubin POD nutzt 6 eigens entwickelte Chips: Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 (CX9) intelligente Netzwerkkarte, BlueField-4 DPU, Spectrum-X 102,4T CPO.
Vera CPU: Für Datenübertragung und Agentenverarbeitung konzipiert, mit 88 Nvidia-eigenen Olympus-Kernen, 176 Threads, Nvidia-Sprach-Multithreading, 1,8TB/s NVLink-C2C, unterstützt CPU:GPU-vereinheitlichte Speicherarchitektur, Systemarbeitsspeicher bis zu 1,5TB (dreimal so viel wie Grace CPU), SOCAMM LPDDR5X-Speicherbandbreite von 1,2TB/s, unterstützt rack-level vertrauliche Berechnungen, doppelte Datenverarbeitungsleistung.

Rubin GPU: Einführung des Transformer-Engines, NVFP4-Inferenzleistung bis zu 50PFLOPS, das Fünf-fache der Blackwell GPU, rückwärtskompatibel, bei gleichbleibender Inferenzgenauigkeit Verbesserung der BF16/FP4-Leistung; NVFP4-Trainingsleistung erreicht 35PFLOPS, das 3,5-fache von Blackwell.
Rubin ist auch die erste Plattform mit HBM4-Unterstützung, HBM4-Bandbreite bis zu 22TB/s, 2,8-mal so hoch wie die Vorgängergeneration, geeignet für anspruchsvolle MoE-Modelle und KI-Workloads.

NVLink 6 Switch: Einzelne Lane-Geschwindigkeit auf 400Gbps erhöht, mit SerDes-Technologie für Hochgeschwindigkeits-Signalübertragung; jede GPU kann 3,6TB/s vollständige Vernetzungskommunikation erreichen, doppelt so viel wie die Vorgängergeneration, Gesamtbandbreite 28,8TB/s, FP8-Genauigkeit in Netzwerkberechnungen bis zu 14,4TFLOPS, unterstützt 100% Flüssigkeitskühlung.

NVIDIA ConnectX-9 SuperNIC: Jede GPU bietet 1,6Tb/s Bandbreite, für groß angelegte KI optimiert, vollständig softwaredefiniert, programmierbar, beschleunigte Datenpfade.

NVIDIA BlueField-4: 800Gbps DPU, für intelligente Netzwerkkarten und Speicherprozessoren, mit 64-Kern Grace CPU, kombiniert mit ConnectX-9 SuperNIC, für die Entlastung von Netzwerk- und Speicherberechnungen, erhöht die Netzwerksicherheit, Rechenleistung sechsmal höher als die Vorgängergeneration, Speicherbandbreite dreimal so hoch, GPU-Zugriffsgeschwindigkeit auf Daten um das Doppelte.

NVIDIA Vera Rubin NVL72: In Systemebene werden alle oben genannten Komponenten zu einem einzelnen Rack-Processing-System integriert, mit 2 Billionen Transistoren, NVFP4-Inferenzleistung 3,6EFLOPS, NVFP4-Training 2,5EFLOPS.
Der Arbeitsspeicher dieses Systems umfasst 54TB LPDDR5X, 2,5-mal so viel wie die Vorgängergeneration; die gesamte HBM4-Speicherkapazität beträgt 20,7TB, 1,5-mal so viel; die HBM4-Bandbreite liegt bei 1,6PB/s, 2,8-mal so hoch wie die Vorgängergeneration; die gesamte vertikale Erweiterungsbandbreite erreicht 260TB/s, übertrifft die globale Internet-Bandbreite.

Dieses System basiert auf dem dritten Generation MGX-Rack-Design, der Berechnungsträger ist modular, ohne Host, ohne Kabel, ohne Lüfter, was den Aufbau und die Wartung um das 18-fache beschleunigt. Früher dauerte die Montage etwa 2 Stunden, jetzt nur noch ca. 5 Minuten. Das System verwendet ursprünglich etwa 80% Flüssigkeitskühlung, jetzt sind es 100%. Ein einzelnes System wiegt inklusive Wassergekühlung bis zu 2,5 Tonnen.

NVLink Switch Tray-Module ermöglichen Null-Ausfallwartung und Fehlertoleranz, das Rack kann weiterlaufen, auch wenn Module entfernt oder teilweise installiert werden. Der zweite RAS-Engine ermöglicht Zero-Downtime-Statusüberwachung.
Diese Eigenschaften erhöhen die Betriebszeit und den Durchsatz des Systems, senken die Trainings- und Inferenzkosten weiter, erfüllen die Anforderungen an hohe Zuverlässigkeit und Wartbarkeit in Rechenzentren.
Mehr als 80 MGX-Partner sind bereit, die Bereitstellung von Rubin NVL72 in großem Maßstab zu unterstützen.
02. Drei neue Produkte revolutionieren die KI-Inferenzleistung: Neue CPO-Komponenten, neue Kontext-Speicherebenen, neues DGX SuperPOD
Gleichzeitig veröffentlicht Nvidia drei wichtige neue Produkte: NVIDIA Spectrum-X Ethernet-gekapselte optische Bauelemente, NVIDIA Inferenz-Kontext-Interner Speicherplattform, basierend auf DGX Vera Rubin NVL72, sowie den NVIDIA DGX SuperPOD.
1. NVIDIA Spectrum-X Ethernet-gekapselte optische Bauelemente
NVIDIA Spectrum-X Ethernet-gekapselte optische Bauelemente basieren auf der Spectrum-X-Architektur, mit 2 Chips, 200Gbps SerDes, jeder ASIC bietet 102,4Tb/s Bandbreite.
Das Switch-Platform umfasst ein 512-Port Hochdichte-System und ein 128-Port Kompakt-System, jeder Port mit 800Gb/s Geschwindigkeit.

CPO (gekapselte optische) Switch-Systeme bieten 5-fache Energieeffizienz, 10-fache Zuverlässigkeit, 5-fache Betriebszeitsteigerung.
Das bedeutet, dass täglich mehr Token verarbeitet werden können, was die Gesamtkosten des Rechenzentrums (TCO) weiter senkt.
2. NVIDIA Inferenz-Kontext-Interner Speicherplattform
Die NVIDIA Inferenz-Kontext-Interner Speicherplattform ist eine POD-ähnliche KI-native Speicherinfrastruktur für die Speicherung von KV-Cache, basiert auf BlueField-4 und Spectrum-X Ethernet, eng gekoppelt mit NVIDIA Dynamo und NVLink, um eine koordinierte Steuerung zwischen Speicher, Speicher und Netzwerk zu ermöglichen.
Diese Plattform behandelt Kontexte als erstklassige Datentypen, erzielt 5-fache Inferenzleistung und 5-fache Effizienzsteigerung.

Dies ist entscheidend für die Verbesserung von Multi-Runden-Dialogen, RAG, Agentic Multi-Step-Inferenz und anderen Langzeit-Kontextanwendungen, die stark auf effiziente Speicherung, Wiederverwendung und Teilen von Kontexten im gesamten System angewiesen sind.
KI entwickelt sich vom Chatbot zum Agentic AI (Intelligent Agent), der inferiert, Werkzeuge aufruft und langfristigen Status pflegt. Das Kontextfenster wurde auf mehrere Millionen Token erweitert. Diese Kontexte werden im KV-Cache gespeichert, wiederholtes Neuberechnen kostet GPU-Zeit und verursacht große Verzögerungen, daher ist Speicherung notwendig.
Doch GPU-Grafikspeicher ist schnell, aber knapp. Traditionelle Netzwerkspeicher sind für kurzfristige Kontexte ineffizient. Die Flaschenhälse bei KI-Inferenz verschieben sich von Berechnung zu Kontextspeicherung. Es braucht eine neue Speicherschicht zwischen GPU und Speicher, die auf Inferenz optimiert ist.

Diese Schicht ist kein nachträgliches Patch, sondern muss gemeinsam mit Netzwerkspeichern gestaltet werden, um Kontextsdatentransfer mit minimalen Kosten zu ermöglichen.
Als neue Speicherebenen existiert die NVIDIA Inferenz-Kontext-Interner Speicherplattform nicht direkt im Host-System, sondern wird über BlueField-4 außerhalb der Recheneinheit verbunden. Der entscheidende Vorteil ist die effizientere Erweiterung des Speicherpools, um redundante KV-Cache-Berechnungen zu vermeiden.
Nvidia arbeitet eng mit Speicherpartnern zusammen, um die NVIDIA Inferenz-Kontext-Interner Speicherplattform in das Rubin-System zu integrieren, sodass Kunden es als Teil einer vollständig integrierten KI-Infrastruktur bereitstellen können.
3. Basierend auf Vera Rubin: NVIDIA DGX SuperPOD
Auf Systemebene ist der NVIDIA DGX SuperPOD eine Blaupause für groß angelegte KI-Fabriken, bestehend aus 8 DGX Vera Rubin NVL72 Systemen, mit NVLink 6 vertikaler Erweiterung, Spectrum-X Ethernet horizontaler Erweiterung, integriertem NVIDIA Inferenz-Kontext-Interner Speicherplattform und validiert durch Engineering.
Das gesamte System wird durch die NVIDIA Mission Control Software verwaltet, um maximale Effizienz zu erreichen. Kunden können es als schlüsselfertige Plattform einsetzen, um Trainings- und Inferenzaufgaben mit weniger GPUs zu bewältigen.
Durch die hochgradige Koordination bei den 6 Chips, den Trays, Racks, Pods, Rechenzentren und Software wurde die Trainings- und Inferenzkosten des Rubin-Systems deutlich gesenkt. Für das Training eines gleich großen MoE-Modells werden nur noch 1/4 der GPUs benötigt; bei gleicher Latenz sinken die Token-Kosten für große MoE-Modelle auf 1/10.
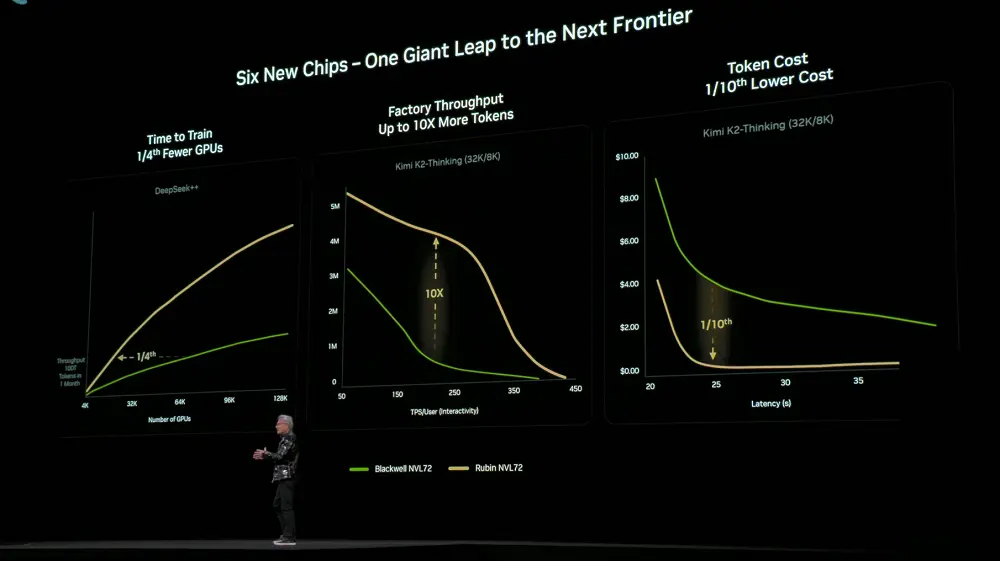
Der NVIDIA DGX SuperPOD mit DGX Rubin NVL8 Systemen wurde ebenfalls vorgestellt.
Mit der Vera Rubin-Architektur baut Nvidia gemeinsam mit Partnern und Kunden das weltweit größte, fortschrittlichste und kostengünstigste KI-System, um die Mainstream-Adoption von KI zu beschleunigen.

Die Rubin-Infrastruktur wird ab der zweiten Jahreshälfte über CSPs und Systemintegratoren bereitgestellt, Microsoft und andere werden die ersten Implementierer sein.
03. Erweiterung des offenen Modell-Universums: Neue Modelle, Daten, offene Ökosysteme
Im Software- und Modellbereich investiert Nvidia weiterhin stark in Open Source.
Mainstream-Entwicklungsplattformen wie OpenRouter zeigen, dass die Nutzung von KI-Modellen im letzten Jahr um das 20-fache gestiegen ist, etwa ein Viertel der Token stammen aus Open-Source-Modellen.
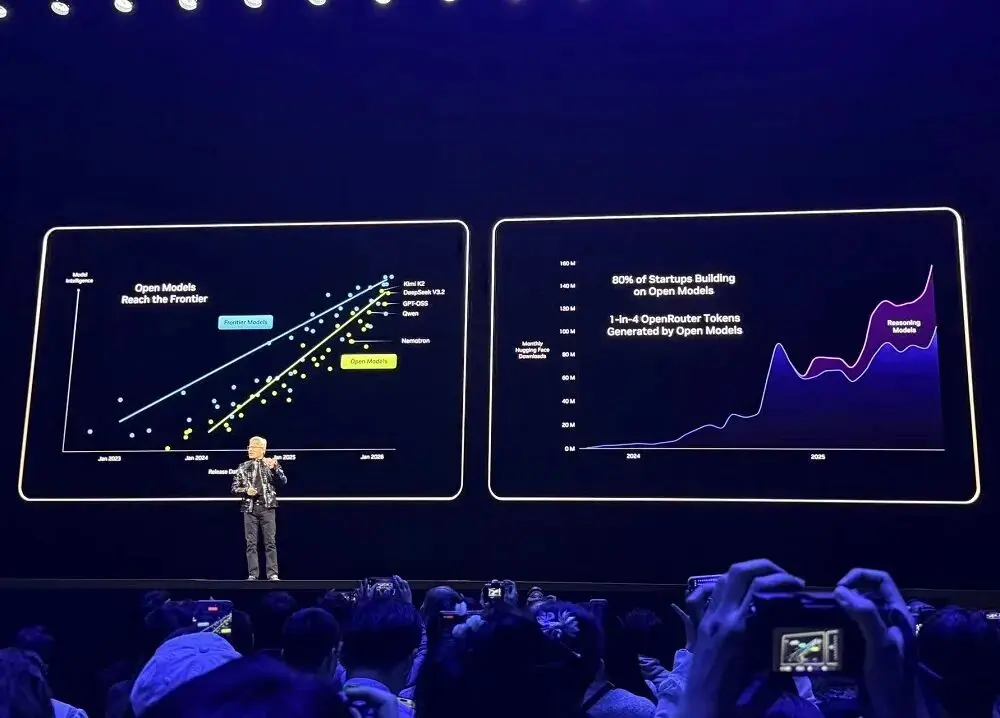
2025 war Nvidia der größte Beitragende bei Open-Source-Modellen, Daten und Rezepten auf Hugging Face, mit 650 veröffentlichten Open-Source-Modellen und 250 offenen Datensätzen.

Nvidia-Open-Source-Modelle rangieren in mehreren Rankings an der Spitze. Entwickler können diese Modelle nicht nur nutzen, sondern auch daraus lernen, sie kontinuierlich trainieren, Datensätze erweitern und Open-Source-Tools sowie dokumentierte Techniken verwenden, um KI-Systeme aufzubauen.

Inspiriert von Perplexity beobachtete Huang Renxun, dass Agents aus Multi-Modell-, Multi-Cloud- und Hybrid-Cloud-Architekturen bestehen sollten, was die Grundstruktur von Agentic AI-Systemen ist, und fast alle Start-ups setzen darauf.
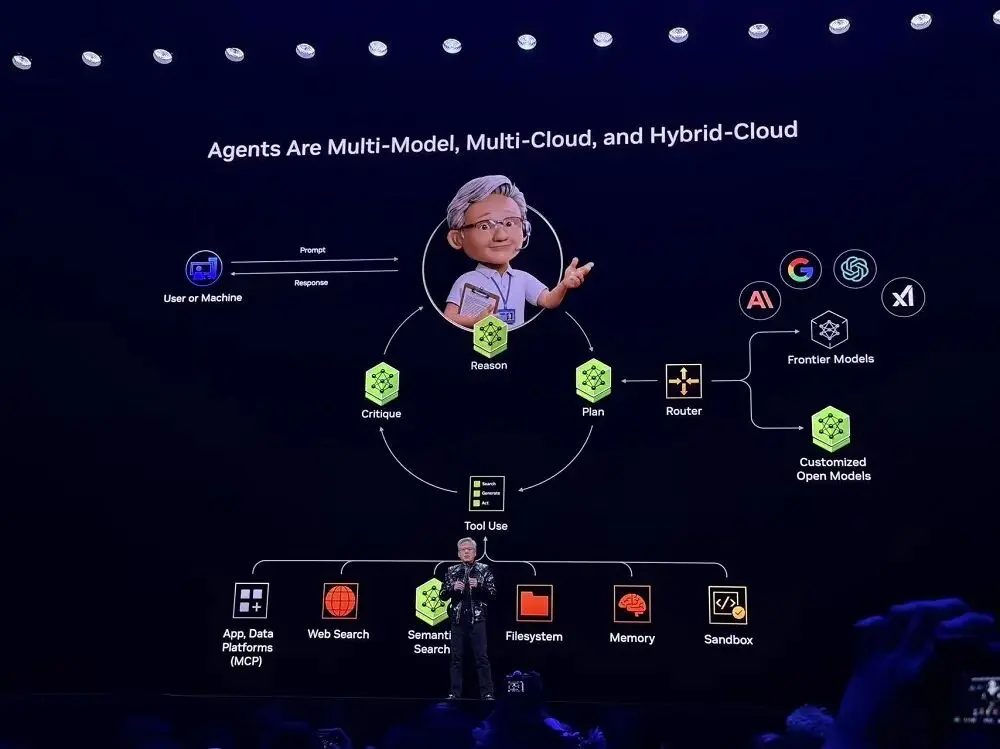
Mit den von Nvidia bereitgestellten Open-Source-Modellen und Tools können Entwickler nun eigene KI-Systeme anpassen und modernste Modelle nutzen. Nvidia hat diese Frameworks bereits in „Blaupausen“ integriert und in SaaS-Plattformen eingebunden. Nutzer können diese Blaupausen für schnelle Deployments verwenden.
In Demo-Beispielen kann das System anhand der Nutzerabsicht automatisch entscheiden, ob die Aufgabe von einem lokalen privaten Modell oder einem Cloud-Front-End-Modell verarbeitet werden soll, externe Tools (wie E-Mail-APIs, Robotersteuerungsschnittstellen, Kalenderdienste) aufrufen und multimodal fusionieren, um Text, Sprache, Bilder und Robotersensor-Signale einheitlich zu verarbeiten.
Diese komplexen Fähigkeiten waren früher unvorstellbar, sind heute aber kaum noch wegzudenken. In Plattformen wie ServiceNow, Snowflake sind ähnliche Fähigkeiten bereits im Einsatz.
04. Open-Source Alpha-Mayo-Modell: Autonomes Fahren „Denken“ lassen
Nvidia glaubt, dass Physische KI und Robotik letztlich die größte Consumer-Elektronik-Nische weltweit werden. Alles Bewegliche wird letztlich vollständig autonom, angetrieben durch Physische KI.
KI hat bereits die Phasen Wahrnehmungs-KI, Generative KI und Agentic KI durchlaufen und befindet sich nun im Zeitalter der Physischen KI, bei der intelligente Systeme die physikalischen Gesetze verstehen und direkt aus Wahrnehmungen der realen Welt Handlungen generieren können.
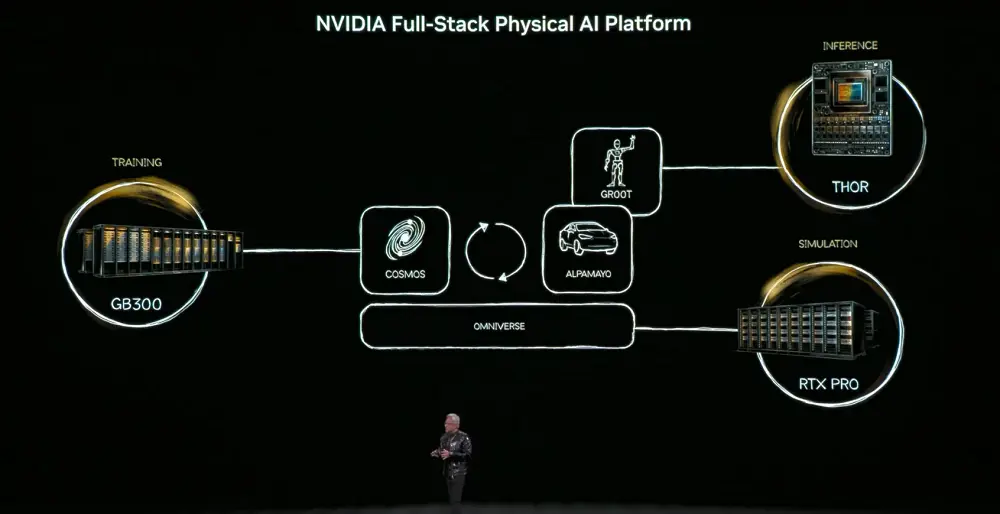
Um dieses Ziel zu erreichen, muss Physische KI Weltwissen erlernen – Objektpermanenz, Schwerkraft, Reibung. Der Erwerb dieser Fähigkeiten hängt von drei Computern ab: Trainingscomputer (DGX) für die Entwicklung der KI-Modelle, Inferenzcomputer (Roboter/Fahrzeug-Chips) für Echtzeit-Ausführung, Simulationscomputer (Omniverse) für die Generierung synthetischer Daten und die Überprüfung physikalischer Logik.
Das Kernmodell ist das Cosmos-Weltgrundlagenmodell, das Sprache, Bilder, 3D und physikalische Gesetze ausrichtet und die gesamte Kette vom Simulationsgenerieren bis zum Training unterstützt.
Physische KI wird in drei Entitäten erscheinen: Gebäude (z.B. Fabriken, Lager), Roboter, autonome Fahrzeuge.
Huang Renxun ist der Meinung, dass autonomes Fahren die erste groß angelegte Anwendung von Physischer KI sein wird. Solche Systeme müssen die reale Welt verstehen, Entscheidungen treffen und Aktionen ausführen, was höchste Sicherheits-, Simulations- und Datenanforderungen stellt.
Dafür hat Nvidia Alpha-Mayo veröffentlicht, ein vollständiges System aus Open-Source-Modellen, Simulationswerkzeugen und physischen KI-Datensätzen, um die sichere, inferenzbasierte Entwicklung von Physischer KI zu beschleunigen.
Dieses Produktportfolio bietet Automobilherstellern, Zulieferern, Start-ups und Forschern die Grundbausteine für die Entwicklung von L4-Autonom-Fahr-Systemen.

Alpha-Mayo ist das erste echte Modell in der Branche, das autonomes Fahren „denken“ lässt, und ist bereits open source. Es zerlegt Probleme in Schritte, führt Inferenz für alle Möglichkeiten durch und wählt den sichersten Weg.

Dieses reasoning-based Task-Action-Modell ermöglicht es autonomen Systemen, komplexe Randfälle zu bewältigen, z.B. bei ausgefallener Ampel an einer belebten Kreuzung.
Alpha-Mayo hat 10 Milliarden Parameter, ausreichend für autonome Fahraufgaben, ist aber leicht genug, um auf Workstations für Forscher zu laufen.
Es kann Text, Rundum-Kameras, Fahrzeughistorie und Navigationsdaten aufnehmen, und Fahrspuren sowie Inferenzprozesse ausgeben, damit Passagiere verstehen, warum das Fahrzeug bestimmte Aktionen durchführt.
In einem Demo-Video kann das Fahrzeug mit Alpha-Mayo in 0 Eingriffen Fußgänger umfahren, Linksabbieger vorhersagen und Spurwechsel durchführen.

Huang Renxun sagt, dass der Mercedes-Benz CLA mit Alpha-Mayo bereits in Produktion ist und kürzlich vom NCAP als sicherstes Auto der Welt bewertet wurde. Jeder Code, Chip und jedes System ist sicherheitszertifiziert. Das System wird in den USA eingeführt und später in diesem Jahr mit erweiterten Fahrfähigkeiten, inklusive Highspeed-Autobahn-Hands-off und vollautomatisiertem Stadtverkehr, verfügbar sein.

Nvidia hat auch einige Datensätze für das Training von Alpha-Mayo sowie das Open-Source-Inferenzmodell-Assessment-Framework Alpha-Sim veröffentlicht. Entwickler können eigene Daten für Feinabstimmung verwenden oder Cosmos für synthetische Daten nutzen, um autonome Fahr-Apps auf realen und synthetischen Daten zu trainieren und zu testen. Zudem kündigte Nvidia an, dass die NVIDIA DRIVE Plattform jetzt in Produktion ist.
Nvidia berichtet, dass führende Robotikunternehmen wie Boston Dynamics, Franka Robotics, Surgical Roboter, LG Electronics, NEURA, XRLabs, Zhiyuan Robotics auf NVIDIA Isaac und GR00T aufbauen.

Huang Renxun kündigte auch die neueste Zusammenarbeit mit Siemens an. Siemens integriert Nvidia CUDA-X, KI-Modelle und Omniverse in seine EDA-, CAE- und Digital-Twin-Tools und Plattformen. Physische KI wird in der gesamten Design-, Simulations-, Fertigungs- und Betriebsprozesskette breit eingesetzt.
05. Schlusswort: Linkshändig Open Source umarmen, Rechtshändig Hardware-Systeme unersetzlich machen
Da die KI-Infrastruktur sich zunehmend vom Training auf groß angelegte Inferenz verschiebt, wandelt sich der Plattform-Wettbewerb vom einzelnen Rechenpunkt hin zu Systemingenieurwesen, das Chips, Racks, Netzwerke und Software umfasst. Ziel ist es, mit minimalen TCO maximale Inferenzdurchsatzleistung zu liefern. KI tritt in eine neue Phase des „Fabrikbetriebs“ ein.
Nvidia legt großen Wert auf systemübergreifendes Design. Rubin verbessert gleichzeitig Leistung und Wirtschaftlichkeit beim Training und bei der Inferenz und kann nahtlos als Plug-and-Play-Alternative zu Blackwell dienen, um einen nahtlosen Übergang zu ermöglichen.
In Bezug auf Plattform-Positionierung hält Nvidia weiterhin das Training für essenziell, da nur durch schnelles Training modernster Modelle die Inferenzplattform wirklich profitieren kann. Daher wurde NVFP4-Training in den Rubin-GPU integriert, um Leistung weiter zu steigern und TCO zu senken.
Gleichzeitig verstärkt dieser KI-Rechenriese seine Netzwerkkommunikation durch vertikale und horizontale Architektur massiv, betrachtet Kontext als kritischen Engpass und gestaltet Speicher, Netzwerk und Rechenleistung koordiniert.
Nvidia öffnet einerseits massiv Open Source, andererseits macht es Hardware, Interconnects und Systemdesign immer „unersetzlicher“. Diese kontinuierliche Nachfrageerweiterung, Token-Verbrauchsanreize, Skalierung der Inferenz und Bereitstellung kosteneffizienter Infrastruktur schaffen eine unüberwindbare Verteidigungsmauer für Nvidia.