No momento em que este artigo é publicado, a Amazon Web Services enfrenta uma grave interrupção que, mais uma vez, impacta a infraestrutura do mercado cripto. Por volta das 8:00 (horário do Reino Unido) de hoje, falhas na região US-EAST-1 da AWS (data centers de North Virginia) derrubaram a Coinbase, além de diversas plataformas de destaque, como Robinhood, Infura, Base e Solana.
A AWS reconheceu “taxas de erro elevadas” em seus serviços Amazon DynamoDB e EC2 — principais soluções de banco de dados e computação utilizadas por milhares de empresas. Este apagão evidencia, de forma imediata e contundente, o ponto central deste artigo: a dependência da infraestrutura cripto de provedores de nuvem centralizados gera vulnerabilidades sistêmicas recorrentes em situações de estresse.
O contexto é revelador. Apenas dez dias após o colapso em cascata de US$19,3 bilhões expor falhas de infraestrutura nas exchanges, a pane da AWS mostra que o problema extrapola as plataformas individuais, atingindo a base da infraestrutura de nuvem. Quando a AWS falha, o efeito dominó atinge exchanges centralizadas, plataformas “descentralizadas” com dependências centralizadas e uma série de outros serviços simultaneamente.
Não se trata de um caso isolado, mas de um padrão repetitivo. A análise a seguir documenta quedas semelhantes da AWS em abril de 2025, dezembro de 2021 e março de 2017, todas com impacto em grandes serviços cripto. A questão não é se a próxima falha de infraestrutura vai acontecer, mas quando e qual será o gatilho.
Liquidação em cascata de 10-11 de outubro de 2025: estudo de caso
O evento de liquidação em cascata ocorrido em 10-11 de outubro de 2025 é um estudo de caso sobre falhas de infraestrutura. Às 20:00 (UTC), um anúncio geopolítico relevante desencadeou vendas massivas no mercado. Em uma hora, US$6 bilhões foram liquidados. Quando as bolsas asiáticas abriram, US$19,3 bilhões em posições alavancadas desapareceram de 1,6 milhão de contas de traders.
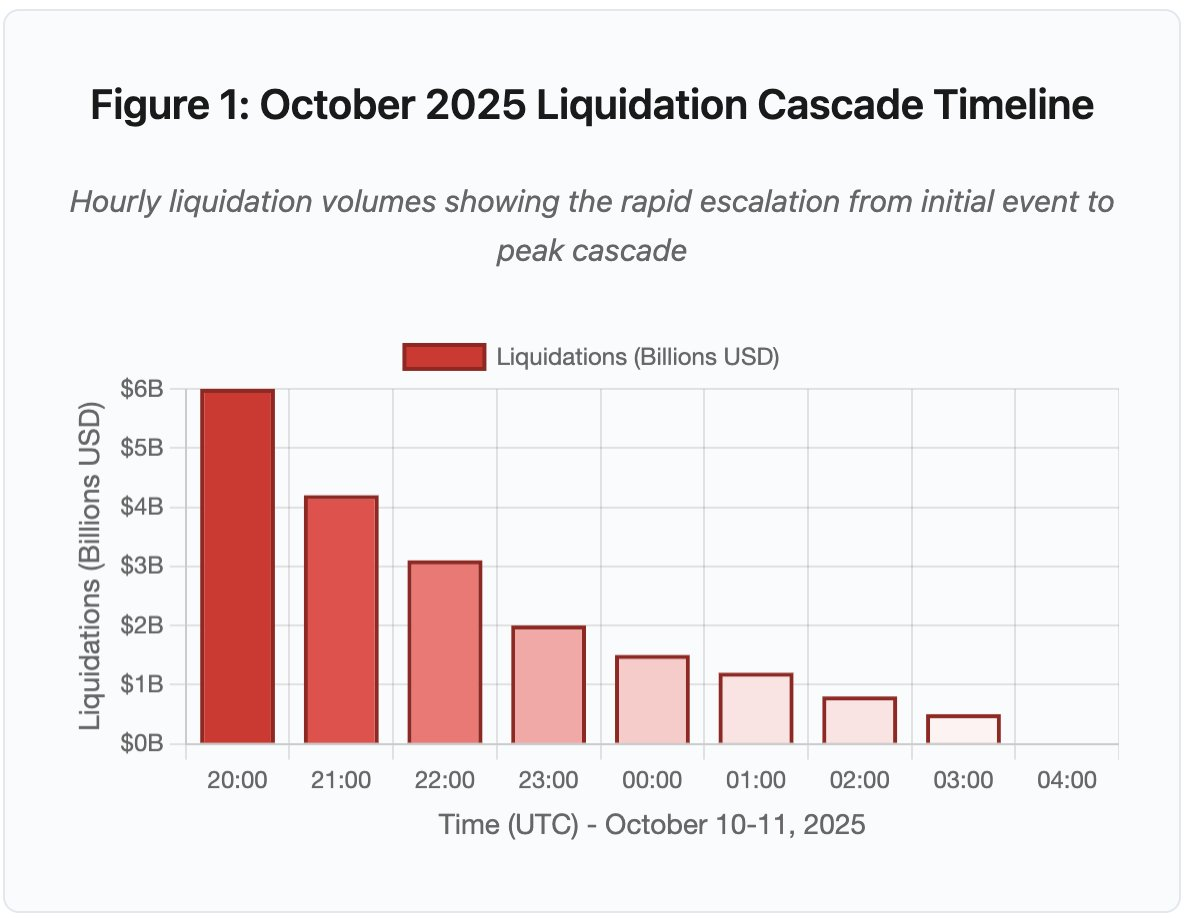
Figura 1: Linha do tempo da liquidação em cascata de outubro de 2025
O gráfico interativo mostra a evolução acelerada das liquidações hora a hora. Só na primeira hora, US$6 bilhões foram eliminados, seguidos por uma segunda hora ainda mais intensa, à medida que a cascata se acelerou. A visualização evidencia:
- 20:00-21:00: Choque inicial — US$6 bilhões liquidados (zona vermelha)
- 21:00-22:00: Pico da cascata — US$4,2 bilhões com início do throttling de APIs
- 22:00-04:00: Degradação prolongada — US$9,1 bilhões em mercados pouco líquidos
- Pontos críticos: limites de taxa de API, retirada de market makers, rarefação do livro de ordens
O volume supera qualquer evento anterior do mercado cripto por uma ordem de grandeza. A comparação histórica mostra o caráter abrupto do fenômeno:
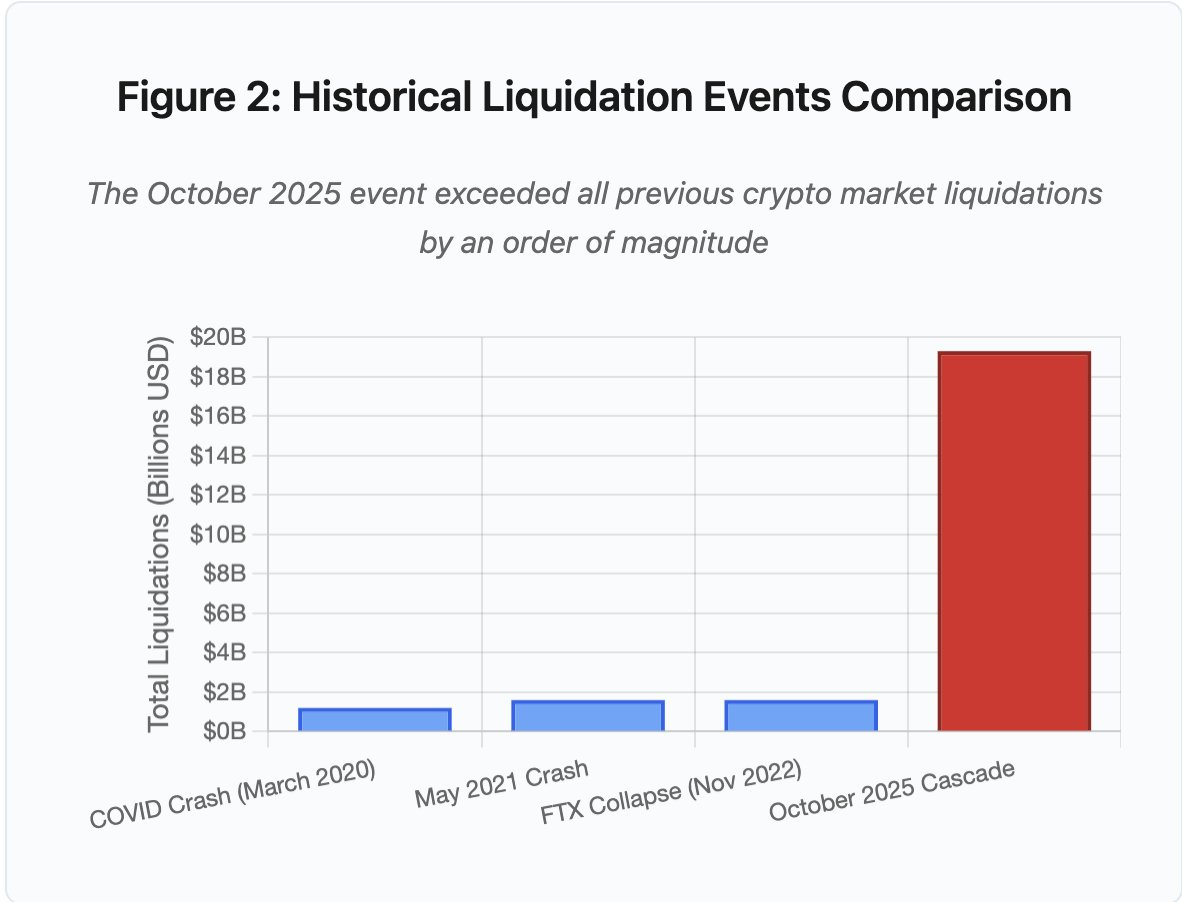
Figura 2: Comparativo de eventos históricos de liquidação
O gráfico de barras mostra o salto de outubro de 2025:
- Março/2020 (COVID): US$1,2 bilhão
- Maio/2021 (Crash): US$1,6 bilhão
- Novembro/2022 (FTX): US$1,6 bilhão
- Outubro/2025: US$19,3 bilhões ⚠️ 16x maior que o recorde anterior
Os valores de liquidação revelam apenas parte do quadro. O aspecto mais relevante é o mecanismo: como eventos externos de mercado provocaram esse tipo específico de falha? A resposta expõe fragilidades sistêmicas na infraestrutura de exchanges centralizadas e no design dos protocolos blockchain.
Falhas off-chain: arquitetura de exchanges centralizadas
Sobrecarga de infraestrutura e limitação de taxa
APIs das exchanges implementam limites de taxa para evitar abusos e controlar o consumo dos servidores. Em operações rotineiras, esses limites permitem negociações legítimas e bloqueiam ataques. Em períodos de alta volatilidade, com milhares de traders ajustando posições ao mesmo tempo, esses limites viram gargalos.
As exchanges limitam notificações de liquidação a uma ordem por segundo, mesmo processando milhares por segundo. Na cascata de outubro, isso gerou falta de transparência: os usuários não tinham acesso à gravidade do evento em tempo real. Ferramentas externas mostravam centenas de liquidações por minuto, enquanto os feeds oficiais registravam bem menos.
Os limites de taxa das APIs impediram traders de modificar posições no momento crítico. Pedidos de conexão expiravam, submissão de ordens falhava, ordens de stop-loss não eram executadas, e consultas de posição retornavam dados desatualizados. Esse gargalo operacional agravou ainda mais o impacto do evento de mercado.
Exchanges tradicionais dimensionam infraestrutura para carga média mais uma margem de segurança. Mas carga média não prevê picos extremos. O volume diário médio pouco indica a demanda sob estresse. Em cascatas, o número de transações pode subir 100x, e consultas de posição aumentam 1000x, já que todos os usuários checam suas contas simultaneamente.
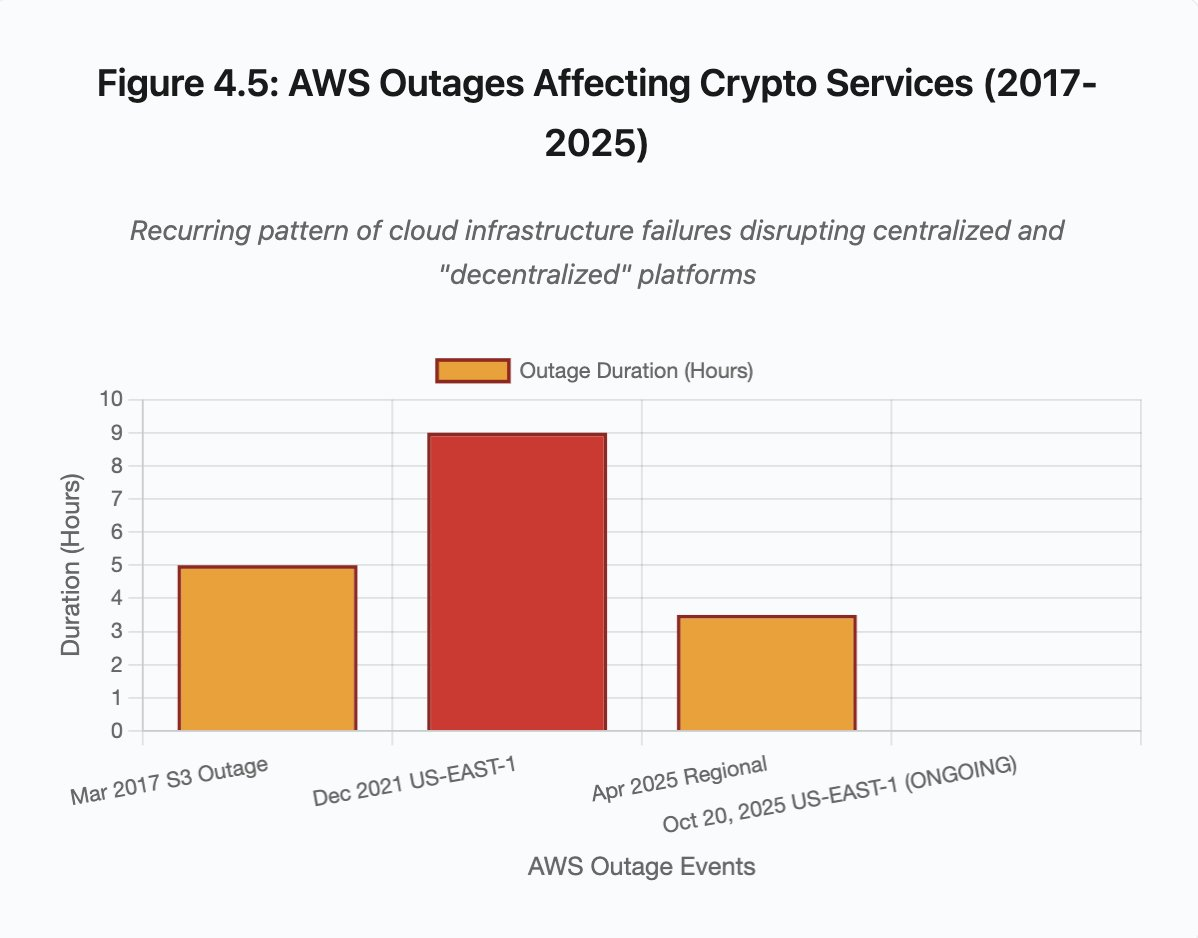
Figura 4.5: Interrupções da AWS em serviços cripto
A auto-escalabilidade da nuvem ajuda, mas não é instantânea. Criar réplicas de banco de dados leva minutos, assim como subir novas instâncias de gateway de API. Durante esse tempo, sistemas de margem continuam marcando posições com dados de preços distorcidos dos livros de ordens sobrecarregados.
Manipulação de oráculos e vulnerabilidades de precificação
Na cascata de outubro, uma decisão crítica de design nos sistemas de margem se destacou: algumas exchanges calcularam o valor do colateral com base nos preços spot internos, e não em feeds externos de oráculo. Em mercados normais, arbitradores mantêm o alinhamento de preços entre plataformas. Mas, sob estresse, esse acoplamento se rompe.
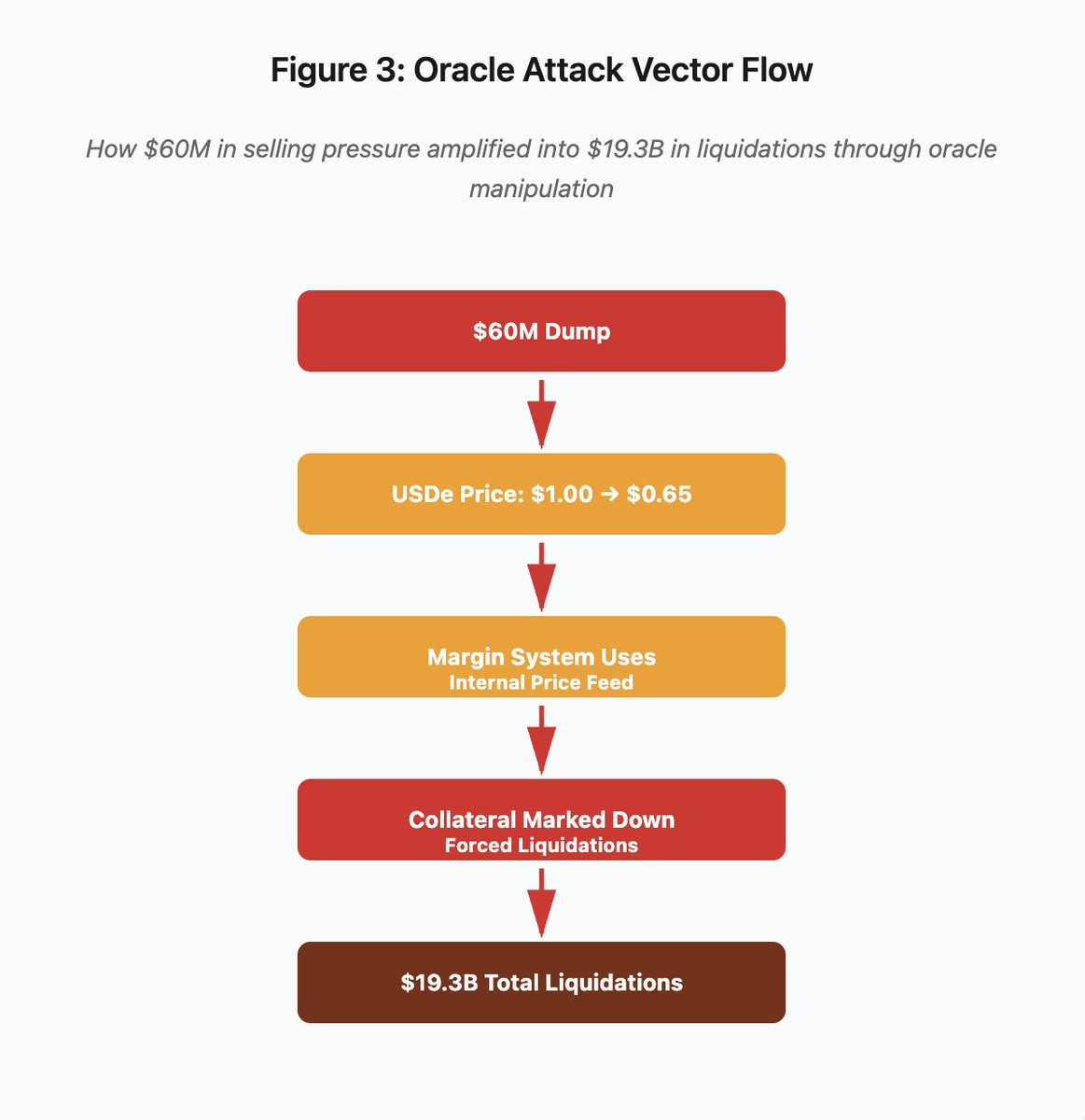
Figura 3: Diagrama de manipulação de oráculo
O diagrama interativo resume o ataque em cinco fases:
- Dump inicial: pressão de venda de US$60 milhões em USDe
- Manipulação de preço: USDe cai de US$1,00 para US$0,65 em uma exchange
- Falha de oráculo: sistema de margem usa feed interno corrompido
- Gatilho da cascata: colateral depreciado, liquidações forçadas
- Amplificação: US$19,3 bilhões em liquidações (amplificação de 322x)
O ataque explorou o uso de preços spot pela Binance para colateral sintético. Quando um atacante despejou US$60 milhões de USDe em livros de ordens pouco líquidos, o preço spot caiu de US$1,00 para US$0,65. O sistema de margem, parametrizado para marcar colateral pelo preço spot, desvalorizou todas as posições lastreadas em USDe em 35%. Isso disparou chamadas de margem e liquidações forçadas em milhares de contas.
Essas liquidações ampliaram a pressão de venda em um mercado já ilíquido, deprimindo os preços ainda mais. O sistema de margem marcava os preços em queda, ampliando o colapso. O ciclo de feedback transformou US$60 milhões de pressão de venda em US$19,3 bilhões em liquidações forçadas.

Figura 4: Ciclo de feedback da liquidação em cascata
O diagrama circular ilustra o ciclo auto-reforçador:
Queda de preço → Liquidações → Venda forçada → Nova queda de preço → [ciclo se repete]
Esse mecanismo seria neutralizado por um sistema de oráculo bem projetado. Se a Binance utilizasse preços médios ponderados por tempo (TWAP) de múltiplas fontes, a manipulação pontual do preço não afetaria o valor do colateral. Feeds agregados da Chainlink ou outros oráculos multi-fonte também teriam bloqueado o ataque.
O caso wBETH, ocorrido quatro dias antes, mostrou vulnerabilidade semelhante. O Wrapped Binance ETH (wBETH) deveria manter paridade 1:1 com ETH. Durante a cascata, a liquidez secou e o mercado spot wBETH/ETH mostrou desconto de 20%. O sistema de margem depreciou o colateral wBETH, disparando liquidações em posições que, na verdade, estavam totalmente colateralizadas por ETH.
Mecanismos de Auto-Deleveraging (ADL)
Quando não é possível liquidar posições pelo preço atual do mercado, as exchanges aplicam Auto-Deleveraging para socializar perdas entre traders lucrativos. O ADL encerra à força posições lucrativas ao preço do momento para cobrir o déficit das liquidações.
Na cascata de outubro, a Binance executou ADL em vários pares. Traders com posições longas lucrativas tiveram seus trades encerrados à força, não por falha de gestão de risco própria, mas pela insolvência de outros participantes.
O ADL reflete uma decisão arquitetural fundamental no trading de derivativos centralizados. As exchanges garantem que não terão prejuízo, ou seja, as perdas precisam ser absorvidas por:
- Fundos de seguro (capital reservado para cobrir déficits de liquidação)
- ADL (encerramento compulsório de posições lucrativas)
- Socialização de prejuízo (distribuição da perda entre todos os usuários)
O tamanho do fundo de seguro em relação ao interesse aberto determina a frequência do ADL. Em outubro de 2025, o fundo de seguro da Binance era de cerca de US$2 bilhões. Contra US$4 bilhões de interesse aberto em futuros perpétuos de BTC, ETH e BNB, esse valor cobre 50%. Porém, durante a cascata, o interesse aberto superou US$20 bilhões em todos os pares, tornando o fundo insuficiente.
Após o evento de outubro, a Binance anunciou garantia de não aplicar ADL para contratos USDⓈ-M de BTC, ETH e BNB enquanto o interesse aberto total permanecer abaixo de US$4 bilhões. Isso incentiva exchanges a manter fundos de seguro maiores para evitar ADL, mas, por outro lado, imobiliza capital que poderia ser usado de forma mais lucrativa.
Falhas on-chain: limitações dos protocolos blockchain
O gráfico de barras compara períodos de indisponibilidade em diferentes incidentes:
- Solana (fev/2024): 5 horas — gargalo de throughput de votação
- Polygon (mar/2024): 11 horas — incompatibilidade de versão entre validadores
- Optimism (jun/2024): 2,5 horas — sobrecarga do sequenciador (airdrop)
- Solana (set/2024): 4,5 horas — ataque de spam de transações
- Arbitrum (dez/2024): 1,5 horas — falha de provedor RPC
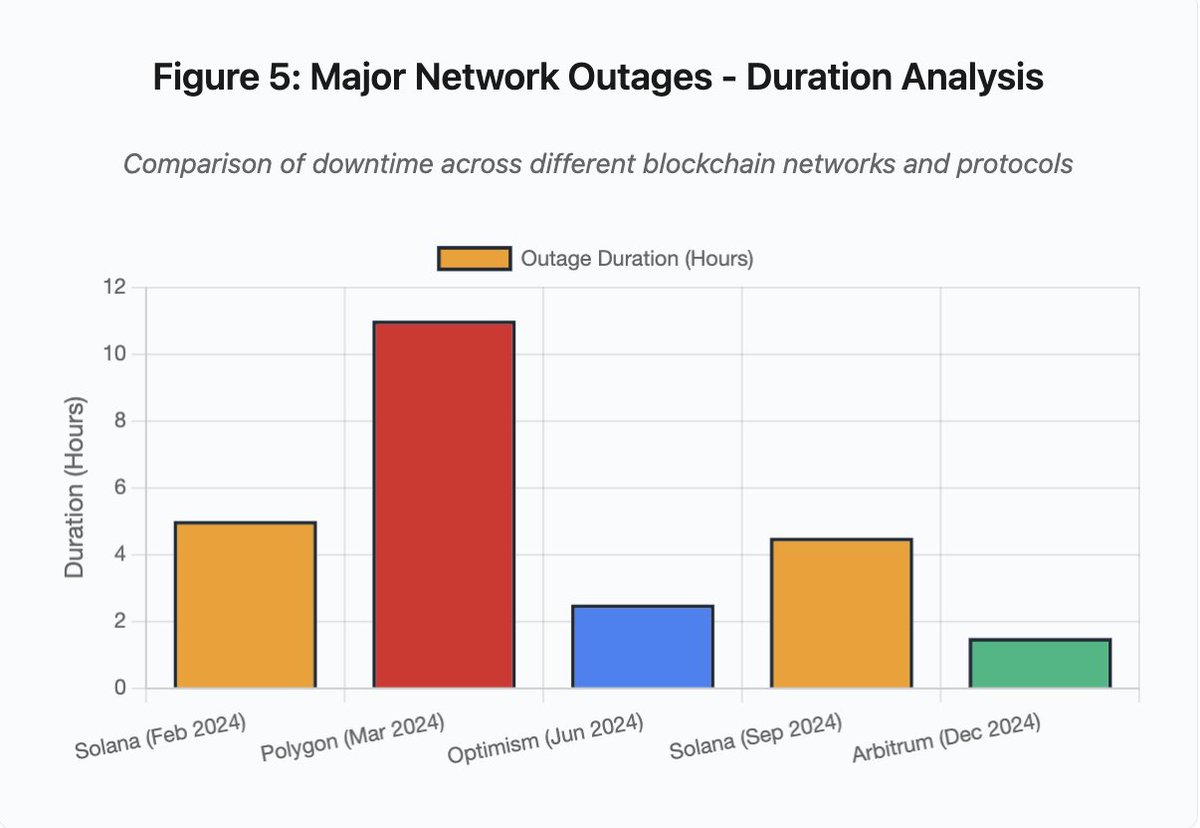
Figura 5: Maiores interrupções de rede — análise de duração
Solana: O gargalo de consenso
Solana passou por várias quedas entre 2024 e 2025. Em fevereiro de 2024, a interrupção durou cerca de 5 horas; em setembro, entre 4 e 5 horas. As causas se repetem: incapacidade de processar o volume de transações em ataques de spam ou atividades extremas.
Detalhe da Figura 5: As quedas da Solana (5 horas em fev, 4,5 horas em set) evidenciam fragilidades recorrentes na resiliência sob estresse.
A arquitetura da Solana privilegia o throughput. Em condições ideais, a rede processa de 3.000 a 5.000 transações por segundo com finalização em menos de um segundo, superando o Ethereum por larga margem. Mas, sob pressão, essa otimização traz vulnerabilidades.
Em setembro de 2024, uma enxurrada de transações de spam sobrecarregou os mecanismos de votação dos validadores. Validadores precisam votar em blocos para alcançar consenso. Em operações normais, priorizam transações de voto para garantir a continuidade do consenso. O protocolo, porém, tratava transações de voto como comuns para efeito de taxas.
Com o mempool saturado por milhões de transações de spam, validadores tiveram dificuldade para propagar votos. Sem votos suficientes, blocos não eram finalizados e a cadeia parou. Transações pendentes ficaram presas no mempool, e novas submissões falhavam.
StatusGator documentou diversas quedas da Solana em 2024–2025 nunca reconhecidas oficialmente. Isso gera assimetria de informação: o usuário não sabe diferenciar falha local de interrupção global. Serviços externos ajudam a monitorar, mas as plataformas deveriam manter páginas de status completas.
Ethereum: A explosão das taxas de gas
A rede Ethereum registrou picos extremos de taxas de gas no boom DeFi de 2021. Transações simples custavam mais de US$100; interações complexas com contratos inteligentes chegavam a US$500–US$1.000. Isso inviabilizou pequenas movimentações e abriu espaço para outro tipo de ataque: extração de MEV.
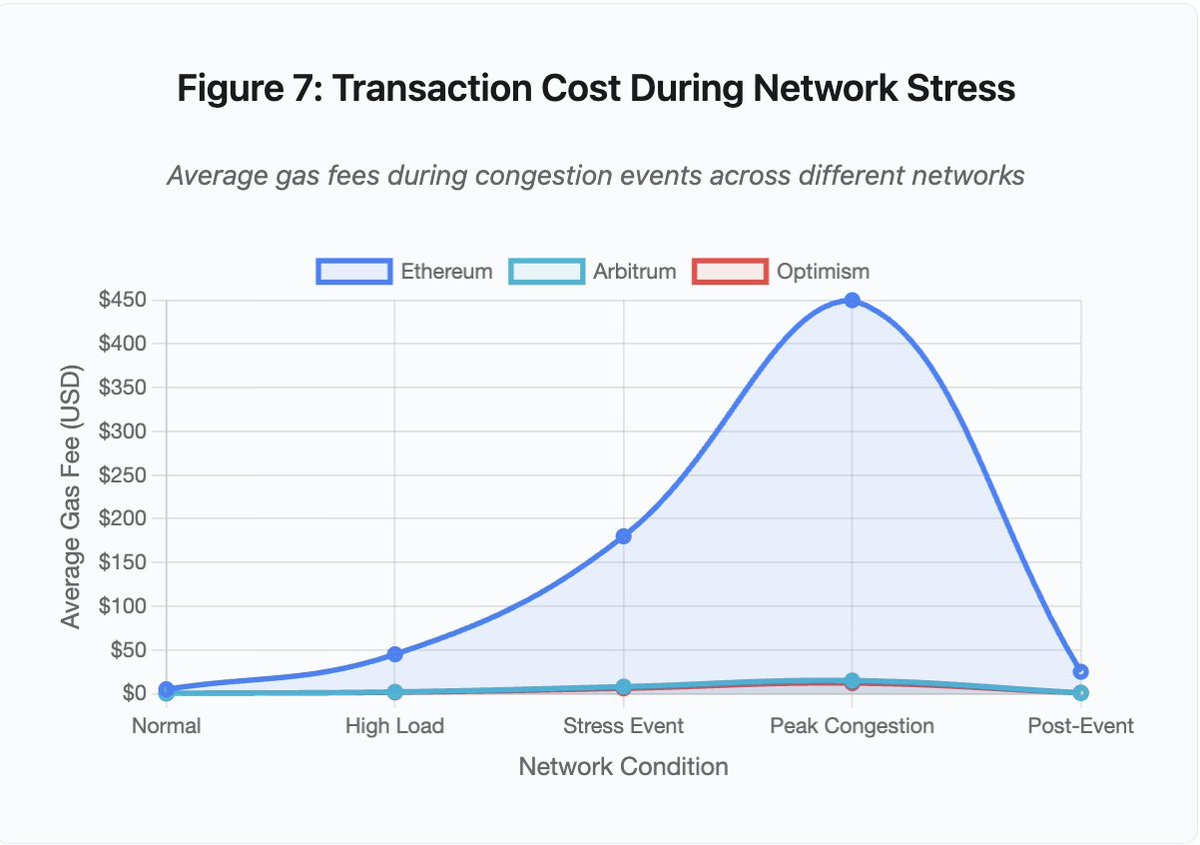
Figura 7: Custo de transação em contexto de estresse de rede
O gráfico mostra o salto das taxas de gas em diferentes redes sob pressão:
- Ethereum: US$5 (normal) → US$450 (congestionamento máximo) — aumento de 90x
- Arbitrum: US$0,50 → US$15 — aumento de 30x
- Optimism: US$0,30 → US$12 — aumento de 40x
Mesmo as soluções Layer 2 sofrem rápida escalada de taxas, ainda que partam de níveis mais baixos.
Maximal Extractable Value (MEV) representa os lucros que validadores extraem ao reordenar, incluir ou excluir transações. Sob taxas altas, o MEV fica especialmente atraente. Arbitradores disputam para antecipar grandes operações em DEXs; bots de liquidação competem para liquidar posições subcolateralizadas primeiro. Essa disputa gera uma guerra por taxas de gas.
Usuários que querem garantir inclusão precisam superar as ofertas dos bots MEV. Isso cria situações em que a taxa paga supera o valor da operação. Quer resgatar US$100 de airdrop? Pague US$150 em gas. Precisa adicionar colateral para evitar liquidação? Dispute com bots pagando US$500 por prioridade.
O limite de gas da Ethereum restringe a computação por bloco. Em congestionamento, usuários disputam espaço escasso. O mercado de taxas funciona: quem paga mais, entra primeiro. Mas isso torna a rede cara exatamente quando o acesso é mais necessário.
Layer 2 tentou resolver o problema movendo computação off-chain, mantendo a segurança via liquidação periódica na Ethereum. Optimism, Arbitrum e outros rollups processam milhares de transações fora da rede principal e submetem provas comprimidas. Isso reduz custos em condições normais.
Layer 2: O gargalo do sequenciador
As soluções Layer 2 geram novos gargalos. O Optimism ficou fora do ar quando 250.000 endereços reivindicaram airdrops ao mesmo tempo em junho de 2024. O sequenciador, responsável por ordenar as transações antes de enviá-las à Ethereum, ficou sobrecarregado, impedindo envios por horas.
O caso mostrou que mover computação off-chain não elimina a necessidade de infraestrutura robusta. O sequenciador precisa processar, ordenar, executar e gerar provas para liquidação na Ethereum. Sob tráfego extremo, enfrenta desafios similares aos blockchains independentes.
É fundamental contar com múltiplos provedores RPC. Se um falha, o usuário deve migrar automaticamente para outro. Na queda do Optimism, alguns provedores seguiram operando, outros pararam. Usuários com wallets configuradas para provedores inativos ficaram sem acesso, mesmo com a rede funcional.
As quedas da AWS expuseram o risco concentrado de infraestrutura no ecossistema cripto:
- 20 de outubro de 2025 (hoje): falha na US-EAST-1 afetando Coinbase, Venmo, Robinhood e Chime. AWS reconheceu taxas de erro elevadas em DynamoDB e EC2.
- Abril/2025: falha regional derrubou Binance, KuCoin e MEXC simultaneamente. Várias exchanges ficaram indisponíveis ao mesmo tempo por falha de componentes hospedados na AWS.
- Dezembro/2021: queda na US-EAST-1 tirou do ar Coinbase, Binance.US e a exchange “descentralizada” dYdX por 8–9 horas, impactando também armazéns da Amazon e serviços de streaming.
- Março/2017: pane no S3 impediu o login na Coinbase e GDAX por cinco horas, além de causar interrupção generalizada na internet.
O padrão é claro: exchanges hospedam componentes críticos na AWS. Quando a AWS tem problemas regionais, várias exchanges e serviços ficam fora do ar simultaneamente. Usuários não conseguem acessar fundos, executar trades ou ajustar posições — justamente quando a volatilidade exige ação imediata.
Polygon: O erro de versão de consenso
Em março de 2024, a Polygon (ex-Matic) passou por uma queda de 11 horas. O problema foi incompatibilidade de versões entre validadores: alguns operavam software antigo, outros já tinham atualizado, o que gerou divergências na computação das transições de estado.
Detalhe da Figura 5: A queda da Polygon (11 horas) foi a mais longa entre os incidentes analisados, evidenciando a gravidade das falhas de consenso.
Com os validadores divergindo sobre o estado correto, o consenso falhou. A cadeia não produzia novos blocos, pois os validadores não concordavam sobre a validade. O impasse: validadores antigos rejeitavam blocos dos novos e vice-versa.
A solução exigiu atualização coordenada dos validadores, processo demorado em redes descentralizadas com centenas de operadores independentes. Cada um precisa ser contatado, atualizar o software e reiniciar o validador, o que pode levar horas ou dias.
Hard forks normalmente usam gatilhos por altura de bloco, garantindo atualização simultânea. Mas isso demanda coordenação prévia. Atualizações graduais criam risco de incompatibilidade de versões, como a que causou a interrupção na Polygon.
Trade-offs arquiteturais
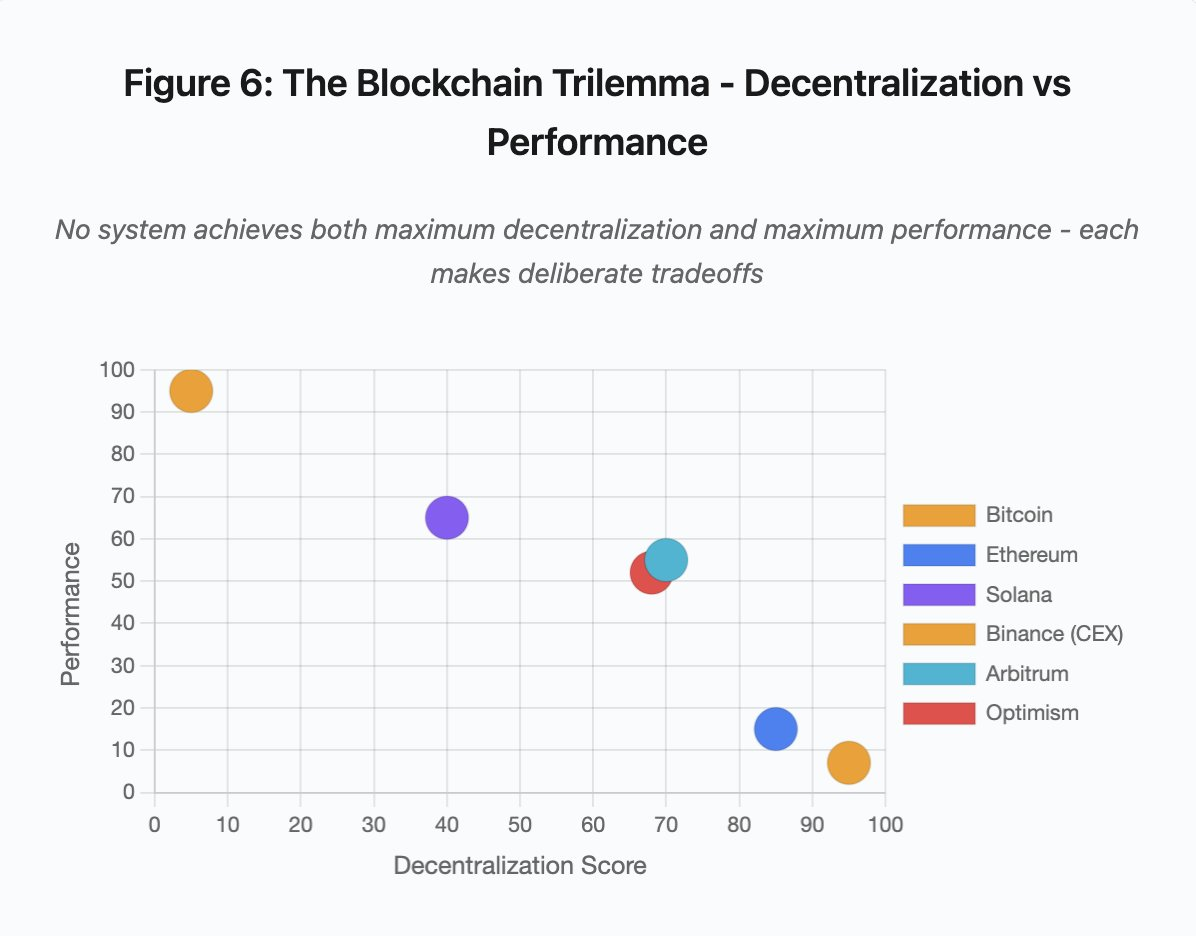
Figura 6: O trilema do blockchain — descentralização versus performance
O gráfico mostra sistemas distribuídos em dois eixos críticos:
- Bitcoin: máxima descentralização, baixa performance
- Ethereum: máxima descentralização, performance moderada
- Solana: descentralização média, alta performance
- Binance (CEX): descentralização mínima, performance máxima
- Arbitrum/Optimism: descentralização média-alta, performance média
Ponto central: nenhum sistema reúne máxima descentralização e máxima performance. Cada arquitetura faz escolhas deliberadas conforme a proposta de valor.
Exchanges centralizadas entregam baixa latência pela simplicidade arquitetural. Matching engines processam ordens em microssegundos, o estado é mantido em bancos de dados centrais e não há overhead de consenso. Mas isso gera pontos únicos de falha, e sob estresse, as falhas propagam em cascata.
Protocolos descentralizados distribuem o estado entre validadores, eliminando pontos únicos de falha. Blockchains de alto throughput mantêm essa característica em quedas — fundos ficam preservados, apenas a disponibilidade é comprometida. Porém, o consenso distribuído exige overhead computacional; validadores precisam concordar antes de finalizar transições de estado. Versões incompatíveis ou tráfego excessivo podem interromper temporariamente o consenso.
Adicionar réplicas melhora tolerância a falhas, mas aumenta a complexidade de coordenação. Em sistemas tolerantes a falhas bizantinas, cada validador extra adiciona overhead de comunicação. Arquiteturas de alto throughput otimizam essa comunicação, ganhando desempenho mas abrindo vulnerabilidades a certos padrões de ataque. Modelos focados em segurança priorizam diversidade e robustez do consenso, limitando o throughput da camada base para maximizar resiliência.
Layer 2 busca reunir ambos os atributos via design hierárquico: segurança herdada da Ethereum (L1) e alto throughput por computação off-chain. Porém, surgem novos gargalos em sequenciadores e RPC, mostrando que maior complexidade traz modos de falha inéditos.
Escalabilidade: o desafio estrutural
Os incidentes mostram um padrão persistente: sistemas são projetados para cargas normais, mas falham de forma abrupta sob estresse. Solana lida bem com tráfego rotineiro, mas entra em colapso com volume 10.000% maior. Taxas de gas da Ethereum são baixas até o DeFi desencadear congestionamento. Infraestrutura do Optimism opera bem até 250.000 endereços reivindicarem airdrop simultaneamente. APIs da Binance funcionam no dia a dia, mas travam nas cascatas de liquidação.
O evento de outubro de 2025 ilustra esse fenômeno ao nível das exchanges. Em operações normais, limites de API e conexões de banco de dados da Binance bastam. Nas cascatas de liquidação, todos os traders tentam ajustar posições ao mesmo tempo, tornando os limites gargalos. O sistema de margem, desenhado para proteger a exchange com liquidações forçadas, amplificou a crise ao criar vendedores compulsórios no pior momento.
A auto-escalabilidade não protege contra saltos abruptos de carga. Subir servidores leva minutos; nesse intervalo, sistemas de margem marcam posições com dados corrompidos de livros de ordens pouco líquidos. Quando a nova capacidade entra em operação, a cascata já se espalhou.
Superprovisionar para eventos raros custa caro no dia a dia. Operadores otimizam para cargas normais, aceitando falhas pontuais como racionalidade econômica. O custo do downtime recai sobre os usuários: liquidações, transações travadas ou inacessibilidade a fundos em momentos críticos.
Avanços em infraestrutura
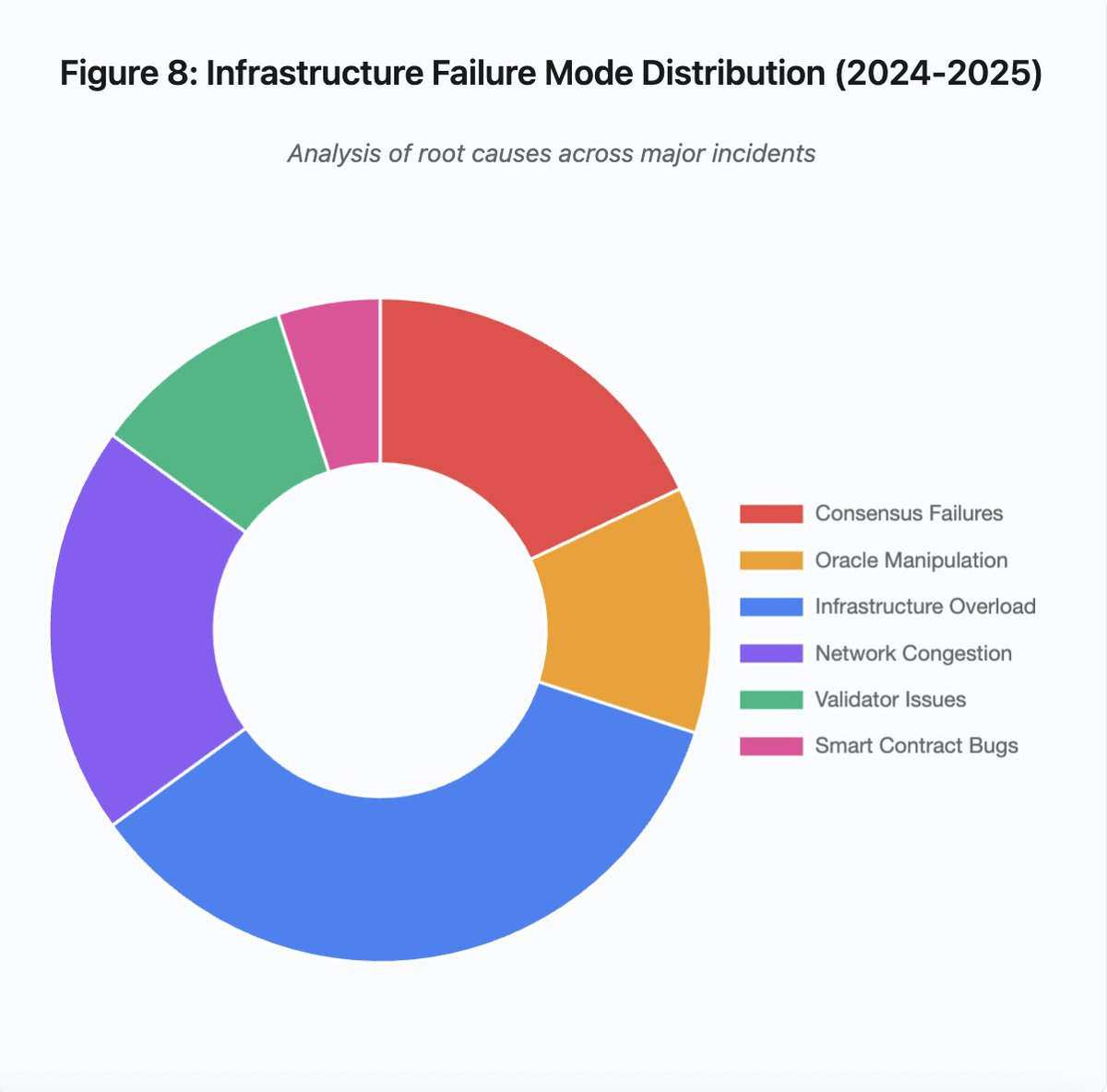
Figura 8: Distribuição dos modos de falha de infraestrutura (2024–2025)
O gráfico de pizza destaca as principais causas:
- Sobrecarga de infraestrutura: 35% (mais recorrente)
- Congestionamento de rede: 20%
- Falhas de consenso: 18%
- Manipulação de oráculo: 12%
- Problemas de validadores: 10%
- Bugs em smart contracts: 5%
Mudanças arquiteturais podem reduzir a frequência e gravidade das falhas, mas sempre trazem trade-offs:
1. Separação entre sistemas de precificação e liquidação
O caso de outubro decorreu do acoplamento das margens ao preço spot. Utilizar razões de conversão para ativos sintéticos, e não preços spot, teria evitado o erro com wBETH. De modo geral, sistemas críticos de gestão de risco não devem depender de dados suscetíveis à manipulação. Oráculos independentes, com feeds multi-fonte e cálculo TWAP, geram precificação robusta.
2. Superprovisionamento e redundância de infraestrutura
A queda da AWS em abril de 2025 mostrou o risco das dependências concentradas. Rodar componentes críticos em múltiplos provedores aumenta custos e complexidade, mas elimina falhas correlacionadas. Layer 2 pode manter vários provedores RPC e failover automático. O custo adicional é pouco relevante em operação normal, mas previne downtime prolongado em picos de demanda.
3. Teste de estresse e planejamento de capacidade aprimorados
Sistemas funcionam bem até falharem sob pressão, indicando falta de testes rigorosos. Simular 100x a carga normal deve ser prática padrão. Identificar gargalos no desenvolvimento é menos custoso do que descobri-los em produção. Porém, testes sintéticos não refletem padrões reais de uso: o comportamento dos usuários em crises é diferente do simulado.
O futuro do setor
Superprovisionar é a solução mais segura, mas contraria os incentivos econômicos. Manter dez vezes a capacidade excedente para eventos raros encarece a operação diária, prevenindo problemas que ocorrem uma vez ao ano. Enquanto falhas catastróficas não justificarem esse custo, sistemas continuarão falhando sob pressão.
Pressão regulatória pode forçar mudanças. Caso normas exijam uptime de 99,9% ou limitem o downtime, exchanges terão de superprovisionar. Mas regulações costumam ser reativas. O colapso Mt. Gox em 2014 levou o Japão a criar normas para exchanges. A cascata de outubro de 2025 deve gerar respostas semelhantes. Não está claro se serão normas de resultado (downtime máximo, slippage máximo nas liquidações) ou de meio (provedores de oráculo específicos, thresholds de circuit breaker).
O desafio é que sistemas operam o tempo todo em mercados globais, mas dependem de infraestrutura pensada para horário comercial tradicional. Quando há estresse às 02:00, equipes correm para consertar enquanto usuários acumulam prejuízos. Mercados tradicionais pausam operações sob estresse; cripto simplesmente colapsa. Se isso é recurso ou falha depende do ponto de vista.
O setor blockchain evoluiu rapidamente em termos técnicos. Garantir consenso distribuído entre milhares de nós é um feito de engenharia. Mas confiabilidade sob pressão exige migrar de arquitetura protótipo para infraestrutura de produção, o que demanda investimento e foco em robustez acima de velocidade de inovação.
O desafio é priorizar estabilidade em bull markets, quando todos ganham e downtime parece problema alheio. No próximo ciclo de estresse, novas vulnerabilidades vão surgir. Se o setor aprender com outubro de 2025 ou repetir padrões, é incerto. Historicamente, novas falhas críticas só ficam evidentes após prejuízos multibilionários sob pressão.
Análise baseada em dados de mercado públicos e declarações de plataformas. As opiniões aqui expressas são exclusivamente do autor e não representam qualquer entidade.
Aviso legal:
- Este artigo é uma republicação de [yq_acc]. Todos os direitos autorais pertencem ao autor original [yq_acc]. Caso haja objeção à republicação, entre em contato com a equipe Gate Learn, que tomará as providências necessárias.
- Aviso de responsabilidade: As opiniões e informações contidas neste artigo são exclusivamente do autor e não constituem recomendação de investimento.
- A tradução do artigo para outros idiomas é feita pela equipe Gate Learn. Salvo indicação contrária, é proibida a reprodução, distribuição ou plágio dos artigos traduzidos.








