
ผู้เขียน: Phosphen
การแปล; Gans 甘斯, Bagel ตลาดทำนายแนวโน้มสังเกตการณ์
ชายคนนี้รวบรวมข้อมูลการแข่งขันเทนนิสอาชีพตลอด 43 ปีที่ผ่านมา ทั้งหมดป้อนเข้าสู่โมเดลการเรียนรู้ของเครื่อง แล้วถามคำถามเดียว: คุณสามารถทำนายได้ไหมว่าใครจะชนะ?
โมเดลตอบคำเดียวว่า: ได้
จากนั้น ในออสเตรเลียนโอเพ่นปีนี้ มันทำนายถูก 99 จาก 116 แมตช์ ความแม่นยำสูงถึง 85%!
นี่เป็นการแข่งขันที่โมเดลไม่เคยเห็นมาก่อนในระหว่างการฝึก มันสามารถทำนายแม้แต่แชมป์สุดท้ายที่ชนะทุกแมตช์ได้อย่างแม่นยำ

ทั้งหมดนี้ใช้แค่แล็ปท็อปเครื่องเดียว ข้อมูลฟรี และโค้ดโอเพ่นซอร์ส ผลงานโดย @theGreenCoding
ต่อไปนี้ ผมจะแยกแยะโครงการนี้อย่างละเอียด ตั้งแต่ข้อมูลดิบจนถึงความสำเร็จในการทำนายสุดท้าย นี่จะเป็นหนึ่งในตัวอย่าง AI + การทำนายที่น่าประทับใจที่สุดที่คุณเคยเห็น
จุดเริ่มต้น: โฟลเดอร์ข้อมูลเทนนิส 43 ปี
เรื่องราวเริ่มจากชุดข้อมูลที่เรียกได้ว่าเป็น “ถ้วยรางวัลแห่งข้อมูลกีฬา” ชุดหนึ่ง
ชุดข้อมูลนี้ครอบคลุมการแข่งขันอาชีพของ ATP (สมาคมเทนนิสอาชีพชาย) ตั้งแต่ปี 1985 ถึง 2024 บันทึกทุกแมตช์
สถิติทุกอย่าง ตั้งแต่จุดเบรก, การทำผิดสองครั้ง, การตีลูกด้วยมือขวา, ซ้าย, ความสูงนักกีฬา, อายุ, อันดับ, สถิติการพบกันก่อนหน้า, สนามแข่ง… ATP ได้บันทึกข้อมูลสถิติทุกแต้มอย่างละเอียด
ไฟล์ CSV กว่า 40 ปี ถูกบรรจุในโฟลเดอร์เดียว
เมื่อเขาเปิดข้อมูลชุดเต็ม คอมพิวเตอร์ก็ล่มทันที
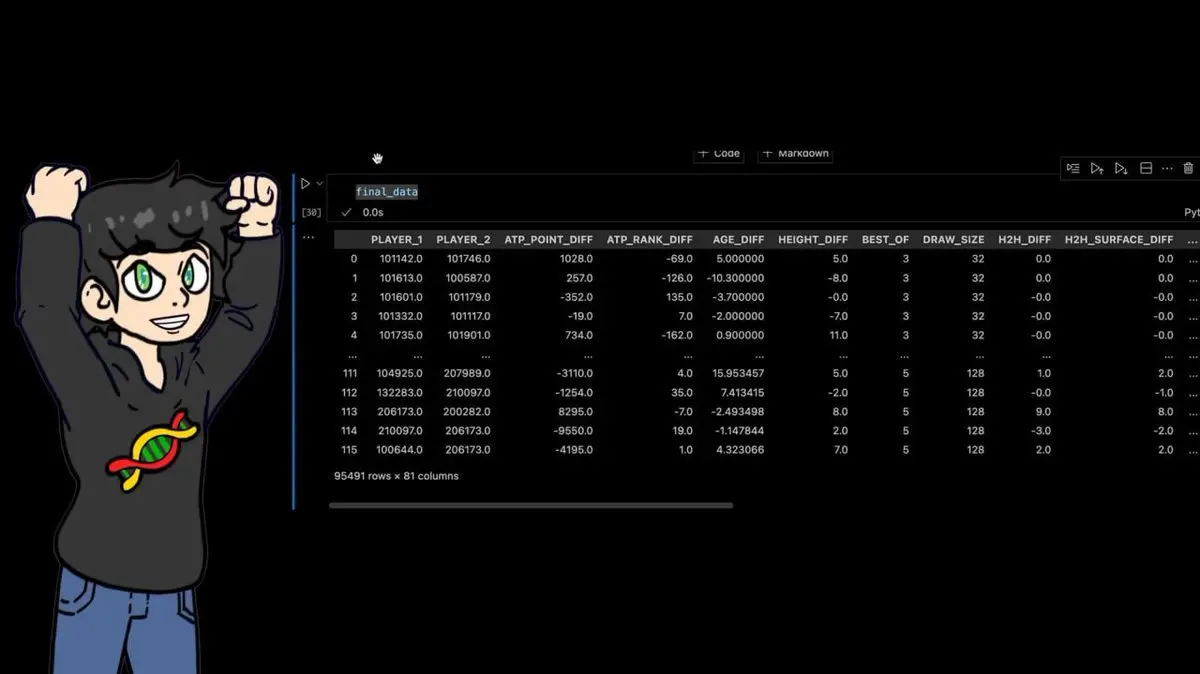
แต่เขาไม่ยอมแพ้ สำหรับการแข่งขัน 95,491 แมตช์ในชุดข้อมูล เขาคำนวณคุณสมบัติอนุพันธ์เพิ่มเติมอีกมากมาย:
- สถิติการพบกันก่อนหน้าของทั้งสองฝ่าย
- ความต่างของอายุ, ความสูง
- อัตราชนะใน 10, 25, 50, 100 แมตช์ล่าสุด
- ความแตกต่างของอัตราการทำคะแนนจากการเสิร์ฟแรก
- ความแตกต่างของอัตราการกู้จุดเบรก
- ระบบคะแนน ELO ที่ปรับแต่งเองจากหมากรุก (สำคัญมาก)
สุดท้าย ชุดข้อมูลประกอบด้วย: 95,491 แถว × 81 คอลัมน์
แมตช์เทนนิสอาชีพ 40 ปีที่ผ่านมา พร้อมคุณสมบัติที่คำนวณด้วยมือเป็นสิบๆ ตัว
ขั้นตอนที่สอง: อิงโมเดลจาก “ไททานิค”

ก่อนจะป้อนข้อมูลเข้าโมเดลจำแนก เขาตัดสินใจเข้าใจกลไกของอัลกอริทึมอย่างลึกซึ้ง ก่อนหน้านั้น เขาเขียน Decision Tree ด้วย numpy ตั้งแต่ศูนย์
Decision Tree ทำงานคล้ายเกมการวิเคราะห์ — ถามคำถามทีละข้อ ค่อยๆ ใกล้คำตอบ
เพื่ออธิบายแนวคิดนี้ เขาเลือกชุดข้อมูลที่แตกต่างอย่างสิ้นเชิง: ไททานิค
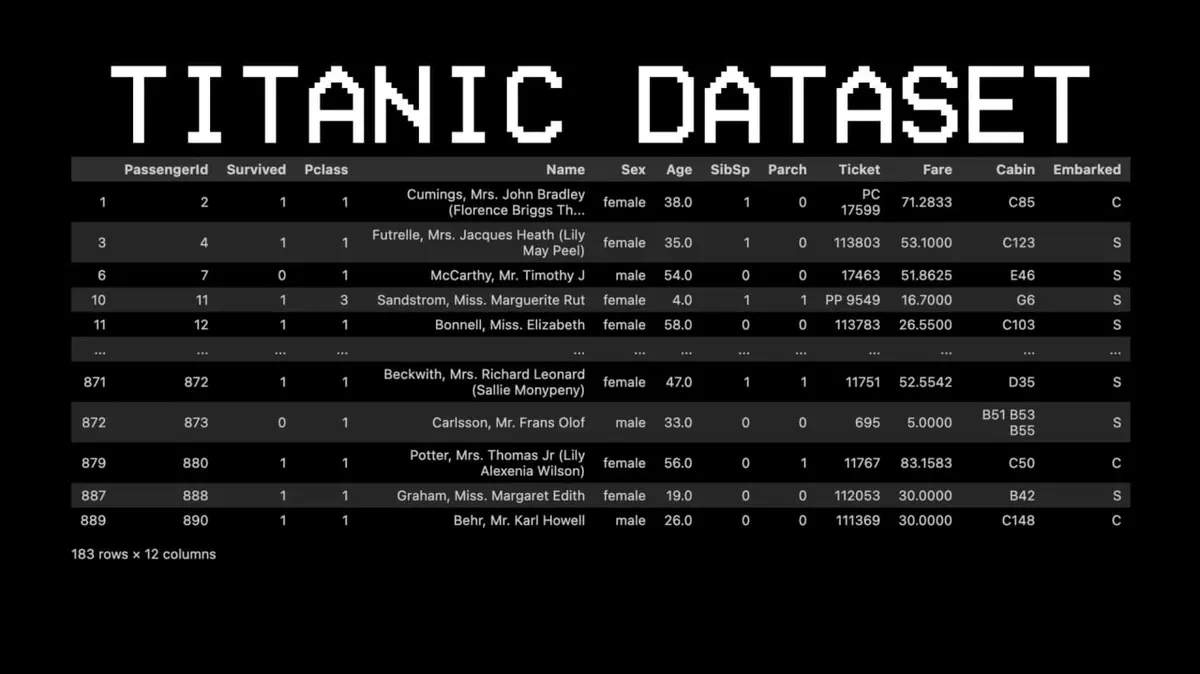
ยกตัวอย่าง: ผู้โดยสารหมายเลข 11 รอดชีวิตไหม?
- คำถามแรก: เขาอยู่ชั้นหนึ่งไหม? → ใช่
- คำถามสอง: เขาเป็นผู้หญิงไหม? → ใช่
- ผลทำนาย: รอดชีวิต
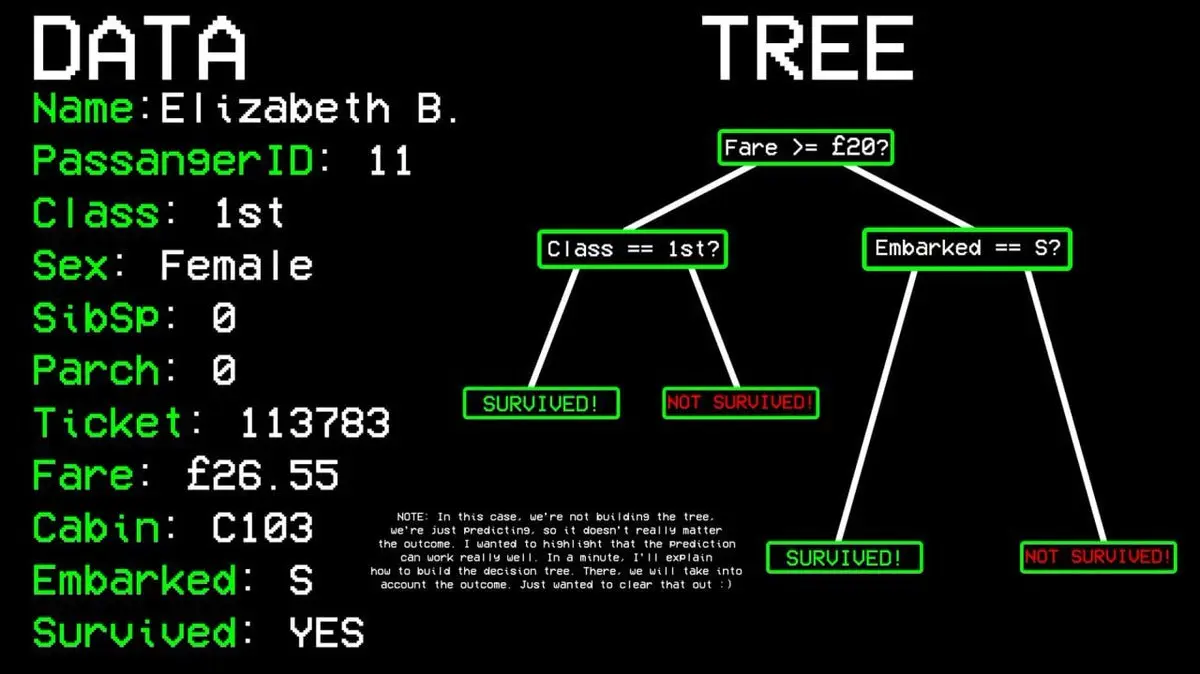
อัลกอริทึมตัดสินใจถามคำถามอย่างไร?
เริ่มจากข้อมูลทั้งหมด ค้นหาตัวแปรเดียวที่สามารถแยกแยะ “รอด” กับ “ไม่รอด” ได้ดีที่สุด ในข้อมูลไททานิค คำตอบคือ ชั้นโดยสาร ผู้โดยสารชั้นหนึ่งอยู่ฝั่งหนึ่ง ส่วนคนอื่นอีกฝั่งหนึ่ง
แต่ก็ยังมีคนชั้นหนึ่งที่จมน้ำ ตรงนี้จึงยังไม่บริสุทธิ์ อัลกอริทึมจะค้นหาจุดแบ่งที่ดีที่สุดถัดไป เช่น เพศ ผู้โดยสารหญิงในชั้นหนึ่งรอดหมด ทำให้กลายเป็น “โหนดบริสุทธิ์” แล้วหยุดแยก
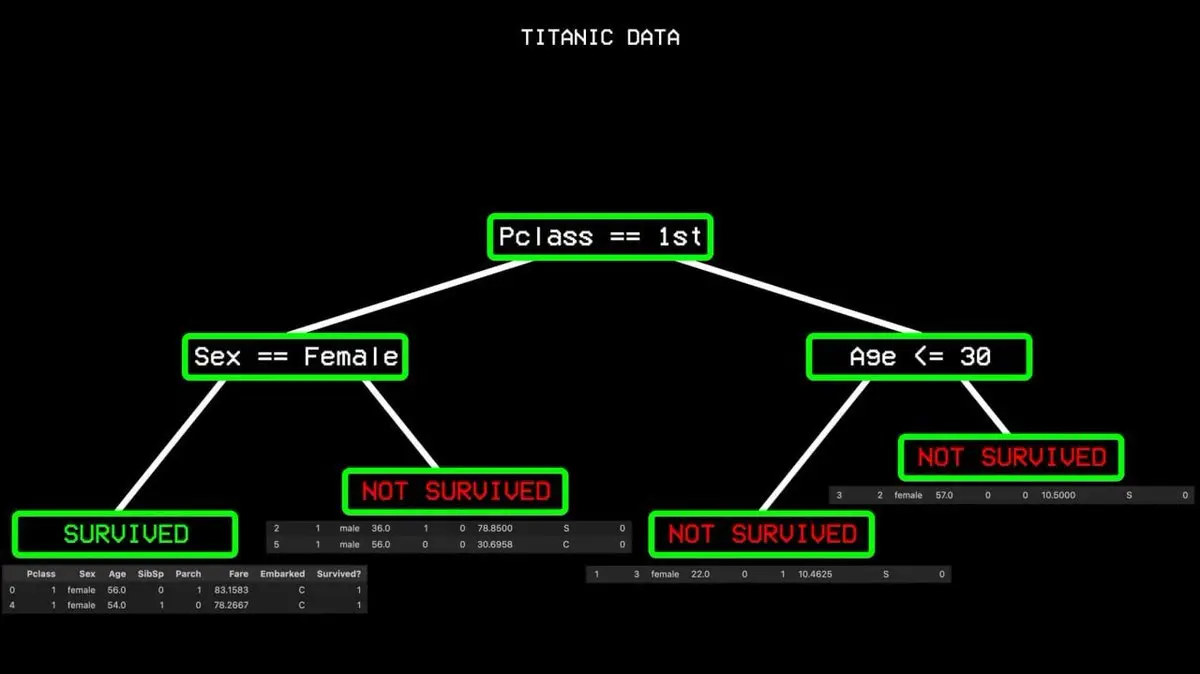
ทำซ้ำขั้นตอนนี้เรื่อยๆ จนสร้างต้นไม้ตัดสินใจที่ครอบคลุมทุกกรณี
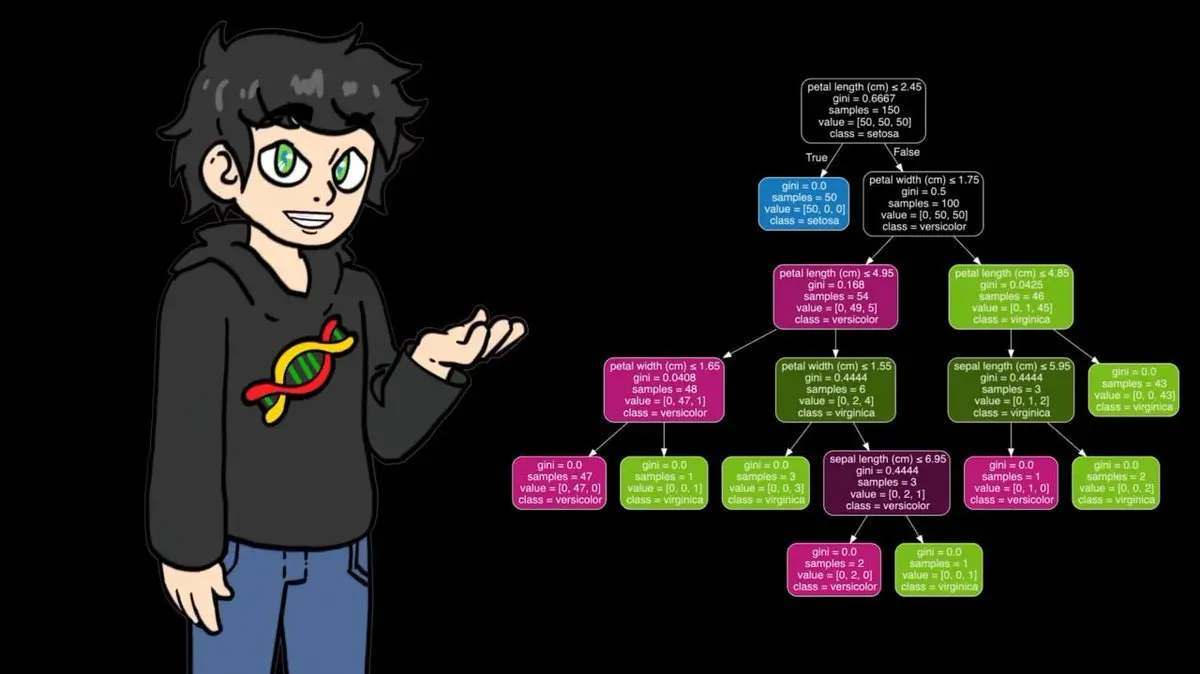
เวอร์ชันเขียนด้วย numpy ของเขา ทำงานดีบนข้อมูลชุดเล็ก แต่เมื่อใช้กับข้อมูลเทนนิส 95,000 รายการ ความเร็วก็ช้าจนค้าง จึงเปลี่ยนมาใช้ sklearn เวอร์ชันที่ปรับแต่งแล้ว ซึ่งเร็วกว่าอย่างมาก
ขั้นตอนที่สาม: ค้นหาตัวแปรสำคัญที่กำหนดผลแพ้ชนะ
ก่อนฝึกโมเดล เขาวาดกราฟ scatter matrix ขนาดใหญ่ด้วย sns pairplot เพื่อหาแนวโน้มที่แยกผู้ชนะกับผู้แพ้ได้

คุณสมบัติส่วนใหญ่เป็นเสียงรบกวน ตัวแปรเช่น ID นักกีฬาไม่ใช่ประโยชน์ อัตราชนะต่างก็มีแนวโน้ม แต่ไม่ชัดเจนพอที่จะสนับสนุนโมเดลที่เชื่อถือได้
มีตัวแปรเดียวที่โดดเด่นมาก: ELO_DIFF (ความต่างคะแนน ELO)
กราฟ scatter ของ ELO_DIFF กับ ELO_SURFACE_DIFF แสดงให้เห็นความแยกชัดเจนระหว่างสองกลุ่ม ไม่มีคุณสมบัติอื่นใกล้เคียง
การค้นพบนี้เป็นแรงผลักดันให้สร้างส่วนสำคัญที่สุดของโปรเจกต์นี้
ขั้นตอนที่สี่: นำระบบคะแนนหมากรุกเข้าสู่เทนนิส
ELO เป็นระบบประเมินระดับฝีมือของนักกีฬา ซึ่งใช้ครั้งแรกในหมากรุก ปัจจุบัน Magnus Carlsen นักหมากรุกอันดับหนึ่งของโลกมีคะแนน 2833

เขาตัดสินใจนำระบบนี้มาประยุกต์ใช้กับเทนนิส:
- คะแนนเริ่มต้นของนักกีฬาแต่ละคน: 1500
- ชนะ: คะแนนเพิ่ม; แพ้: คะแนนลด
กลไกสำคัญ: การได้คะแนนขึ้นอยู่กับความแตกต่างของคะแนนกับคู่แข่ง ชนะคู่แข่งที่มีคะแนนสูงกว่าได้คะแนนมากกว่า แพ้คู่แข่งที่มีคะแนนต่ำกว่าเสียคะแนนมาก
เขาใช้สูตรนี้ในรอบชิงชนะเลิศวิมเบิลดัน 2023: คาร์ลอส อัลการาซ (คะแนน 2063) พบ โนวัค ยอโควิช (คะแนน 2120) อัลการาซพลิกชนะ

แทนค่าด้วยสูตร: อัลการาซ +14 คะแนน, ยอโควิช -14 คะแนน
แม้การคำนวณง่าย แต่เมื่อใช้กับข้อมูล 43 ปี ผลลัพธ์น่าทึ่งมาก
ขั้นตอนที่ห้า: การแสดงภาพความครอบงำของ “สามยักษ์ใหญ่”
เขาวาดกราฟคะแนน ELO ของเฟเดอเรอร์ตลอดอาชีพ ตั้งแต่เริ่มเล่นจนเลิกแข่ง ทุกแมตช์ชัดเจน
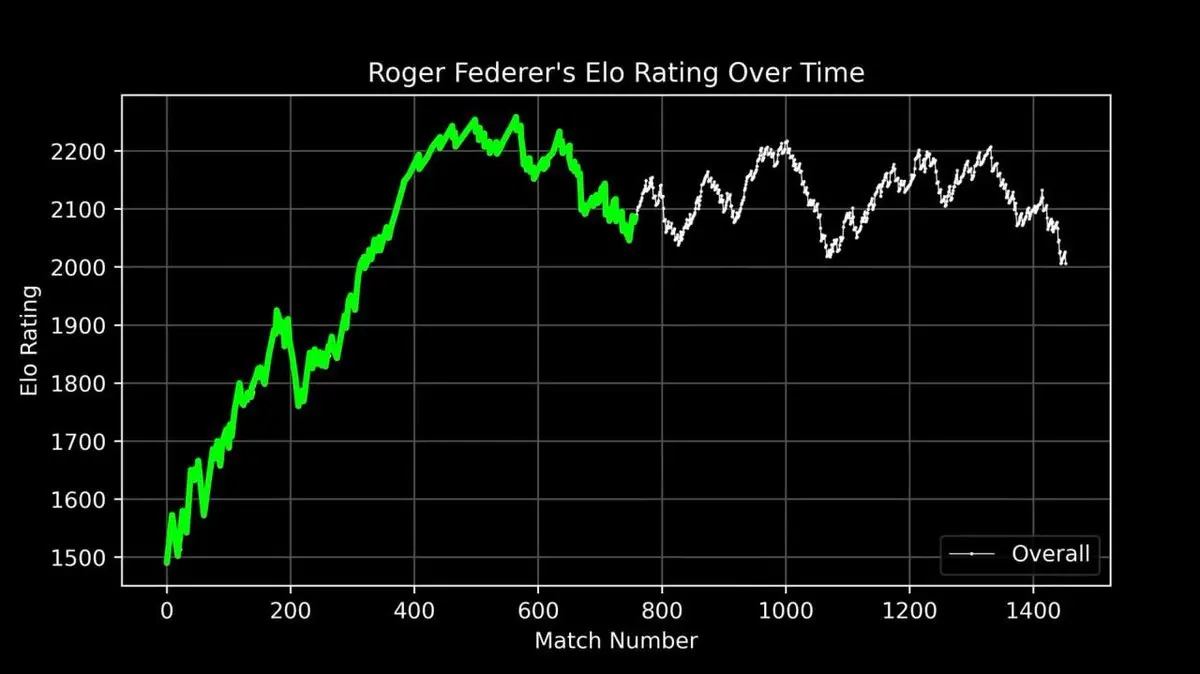
เส้นกราฟนี้แสดงความเป็นตำนาน: การขึ้นสู่จุดสูงสุดในช่วงต้น, ยุคที่ครองอำนาจ (ประมาณหลังแมตช์ที่ 400) และความผันผวนในช่วงปลายอาชีพ
แต่สิ่งที่น่าทึ่งที่สุดคือ เมื่อวางเฟเดอเรอร์ เทียบกับนักเทนนิส ATP ทุกคนตั้งแต่ปี 1985 ลงบนกราฟเดียวกัน:
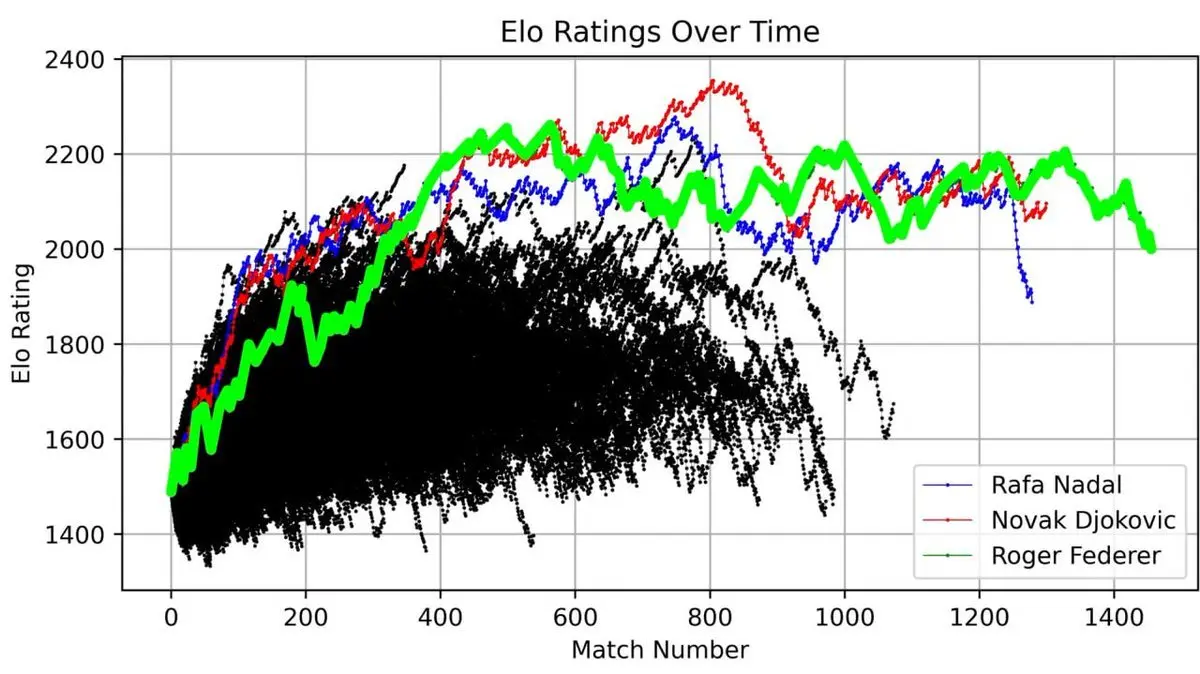
สามเส้นโค้งสูงเด่น เหนือกว่าคนอื่นอย่างชัดเจน — เฟเดอเรอร์ (เขียว), นาดาล (น้ำเงิน), ยอโควิช (แดง)
“สามยักษ์ใหญ่แห่งแกรนด์สแลม” ไม่ใช่แค่คำขนานนาม เมื่อคุณนำข้อมูล 40 ปีมาวิเคราะห์ในเชิงคณิตศาสตร์ ความครอบงำนี้ชัดเจนมาก
ตามระบบ ELO ที่ปรับแต่งเอง ปัจจุบันอันดับหนึ่งของโลกคือ ยานนิค ซินเนอร์ (2176 คะแนน), รองลงมาคือ ยอโควิช (2096), และอัลการาซ (2003)

อย่าลืมว่าซินเนอร์อยู่อันดับหนึ่ง ซึ่งเป็นจุดสำคัญในภายหลัง
ขั้นตอนที่หก: สนามเป็นตัวแปรเปลี่ยนเกม
สนามแข่งเทนนิสมีผลอย่างมากต่อรูปแบบการแข่งขัน:
- ดินแดง: ช้า, กระโดดสูง
- หญ้า: เร็ว, กระโดดต่ำ
- คอนกรีต: กลางๆ
นักกีฬาที่เก่งในสนามหนึ่ง อาจล้มเหลวในอีกสนามหนึ่ง
เขาจึงสร้างคะแนน ELO สำหรับแต่ละสนาม: ดินแดง, หญ้า, คอนกรีต
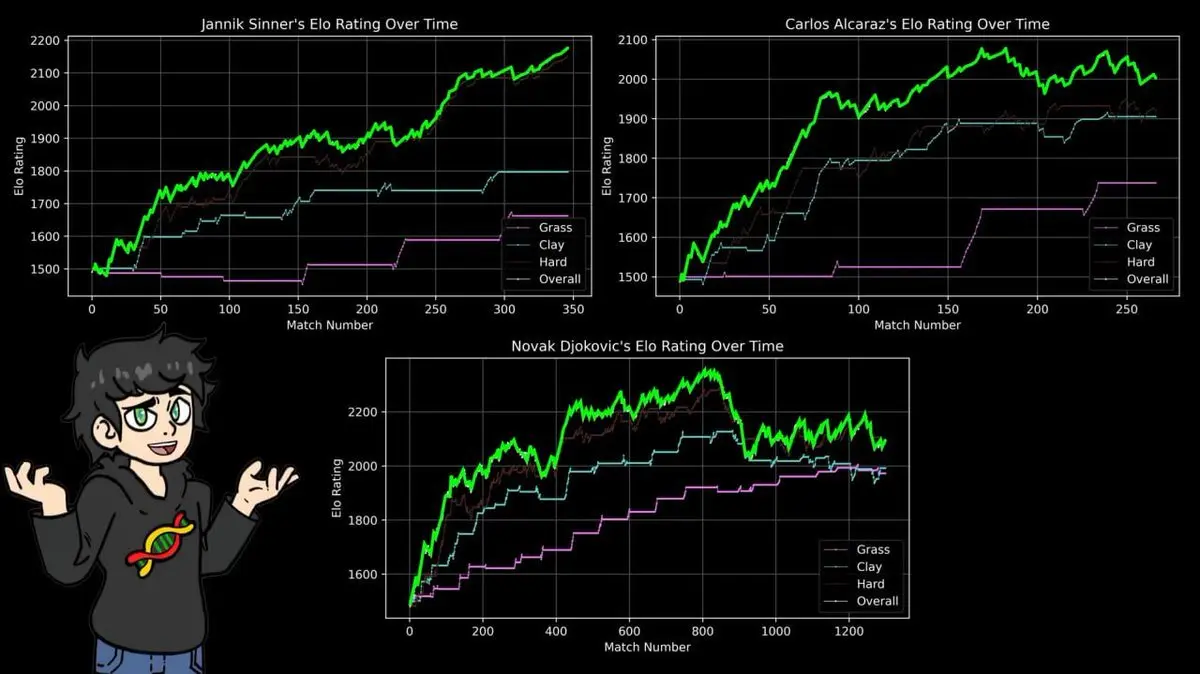
ผลลัพธ์ยืนยันความรู้ทั่วไปของแฟนเทนนิส และใช้ข้อมูล 43 ปีเป็นหลักฐาน:
คะแนนสูงสุดของนาดาลบนดินแดง เกินกว่าคะแนนสูงสุดของเฟเดอเรอร์บนหญ้า, และเกินกว่าคะแนนสูงสุดของยอโควิชบนคอนกรีต รวมถึงสถิติแชมป์เฟรนช์โอเพ่น 14 สมัย ชนะ 112 แพ้ 4 ใน Roland Garros
สูตร ELO ไม่สนเรื่องเล่า ไม่สนชื่อเสียง มันแค่จัดการกับสถิติชนะแพ้ และผลลัพธ์ที่ได้ตรงกับข่าวกีฬา 40 ปีที่ผ่านมาอย่างสมบูรณ์
ขั้นตอนที่เจ็ด: เจอเพดาน
ข้อมูลพร้อม ระบบ ELO พร้อมแล้ว เขาเริ่มฝึกโมเดลจำแนก ผลลัพธ์แสดงให้เห็นความสำคัญของการเลือกอัลกอริทึม
Decision Tree: ความแม่นยำ 74%
ต้นไม้เดียวบนข้อมูลเต็ม ทำได้ 74% ซึ่งฟังดูดี — จนกระทั่งรู้ว่า การใช้ความแตกต่างของคะแนน ELO ทำนายผู้ชนะ ก็ได้ 72% แล้ว
Decision Tree บนระบบคะแนนที่เขาสร้างเองแทบไม่เพิ่มอะไรเลย
Random Forest: ความแม่นยำ 76%
ปัญหาของ Decision Tree คือ “ความแปรปรวนสูง” — มันไวต่อข้อมูลชุดฝึกมาก วิธีแก้คือ Random Forest สร้างต้นไม้หลายสิบหรือร้อยต้น โดยใช้ข้อมูลและคุณสมบัติแบบสุ่ม แล้วโหวตผลสุดท้าย

สร้าง 94 ต้นไม้ที่แตกต่างกัน เพื่อโหวตผลการแข่งขันแต่ละแมตช์

ผลคือ 76% ซึ่งเป็นการพัฒนาเล็กน้อย แต่เขาก็เจอเพดานนี้แล้ว ไม่ว่าจะปรับแต่งพารามิเตอร์ใหม่ หรือเปลี่ยนคุณสมบัติ ก็ไม่สามารถเกิน 77% ได้
ขั้นตอนที่แปด: ทะลุเพดาน
จากนั้น เขาลอง XGBoost ซึ่งเขาเรียกว่า “เวอร์ชันสเตอริโอของรันด์ฟอเรสต์”
ความแตกต่างสำคัญคือ: รันด์ฟอเรสต์สร้างต้นไม้พร้อมกันแล้วเฉลี่ยผลลัพธ์ ขณะที่ XGBoost สร้างต้นไม้แบบต่อเนื่อง — แต่ละต้นใหม่จะปรับปรุงข้อผิดพลาดของต้นก่อนหน้า มีการใช้ regularization เพื่อป้องกัน overfitting และควบคุมขนาดของต้นไม้ให้เล็ก
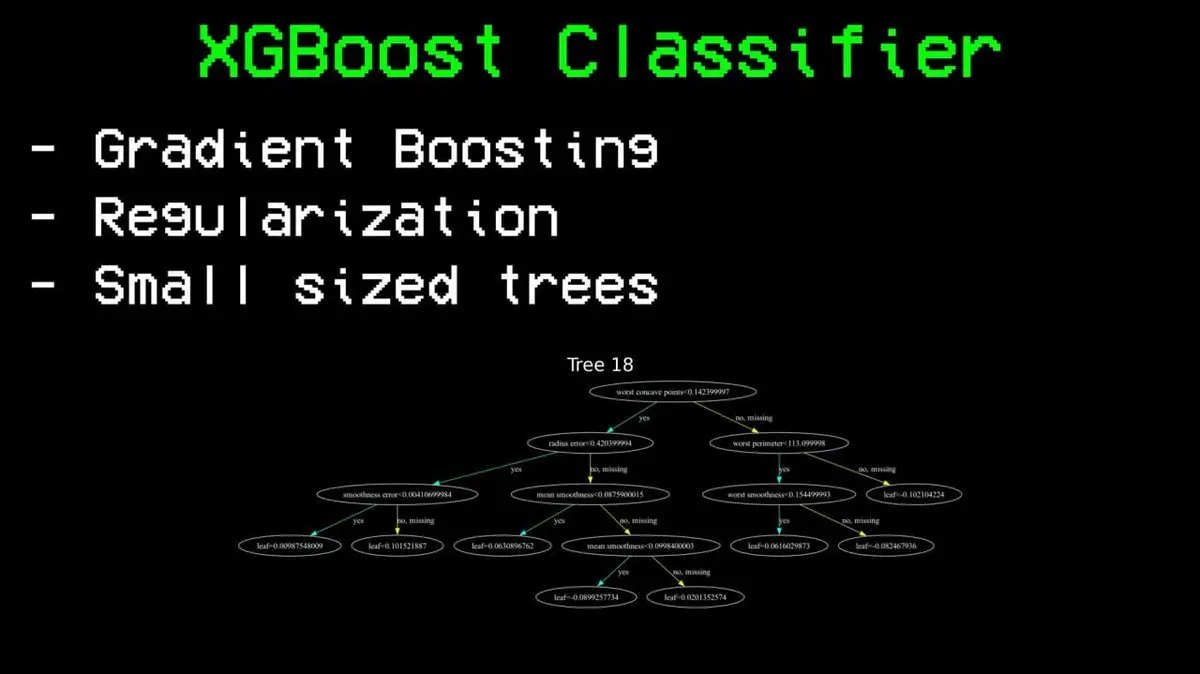
ผลลัพธ์: ความแม่นยำ 85%
ต่างจากเพดาน 76% อย่างมาก นี่คือความก้าวหน้าที่สำคัญ ด้วยข้อมูลเดียวกัน คุณสมบัติเดียวกัน สิ่งที่เปลี่ยนคืออัลกอริทึม
XGBoost ก็พบว่าสามคุณสมบัติที่สำคัญที่สุดคือ: ความต่างคะแนน ELO, ความต่างคะแนนสนามเฉพาะ, คะแนนรวม ELO ระบบนี้จากหมากรุกที่นำมาปรับใช้ในเทนนิส ได้รับการยืนยันว่าเป็นตัวทำนายที่แข็งแกร่งที่สุดใน 81 คอลัมน์
เพื่อเปรียบเทียบ เขาฝึก neural network ด้วยข้อมูลเดียวกัน ความแม่นยำ 83% ก็ยังน้อยกว่า XGBoost ซึ่งชนะในชุดข้อมูลนี้
ขั้นตอนที่เก้า: การตัดสินใจในเวลาสำคัญ — แกรนด์สแลมออสเตรเลีย 2025
ข้อมูลทั้งหมดนี้ ฝึกจนถึงธันวาคม 2024
แต่ Australian Open 2025 ซึ่งจัดในมกราคม ไม่อยู่ในชุดข้อมูลฝึก ทำให้เป็นสนามทดสอบที่สมบูรณ์แบบ: โมเดลเข้าใจแท้จริงของเทนนิสหรือแค่จำรูปแบบในอดีต?

เขาป้อนตารางการแข่งขันทั้งหมดเข้าโมเดล ให้มันทำนายทุกแมตช์
ผลลัพธ์: ทำนายถูก 99 จาก 116 แมตช์ คิดเป็นความแม่นยำ 85.3%
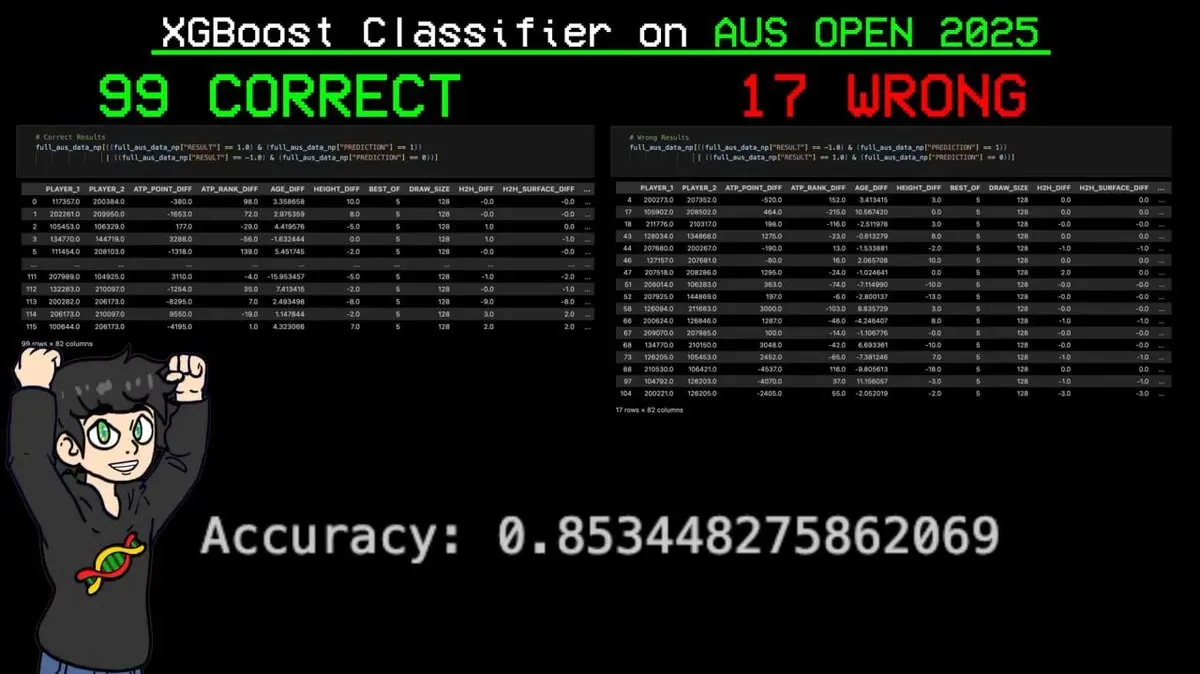
การทำนายที่สำคัญที่สุดคือ โมเดลทำนายถูกทุกแมตช์ที่ซินเนอร์ชนะในทัวร์นาเมนต์นี้ล่วงหน้า
ก่อนลูกแรกตกพื้น AI ก็ทำนายแชมป์แกรนด์สแลมได้แล้ว
สรุป
คนคนเดียว, แล็ปท็อปเครื่องเดียว, ไม่มีข้อมูลเฉพาะตัว, ไม่มีโครงสร้างพื้นฐานราคาแพง, ไม่มีทีมวิจัย — กลับสร้างโมเดลทำนายเทนนิสอาชีพที่แม่นยำถึง 85% และทำนายแชมป์ก่อนการแข่งขันจะเริ่ม
ข้อมูลเทนนิสอยู่บน GitHub พร้อมให้ทำซ้ำได้เต็มที่
สร้างสรรค์สิ่งมหัศจรรย์ ไม่เคยง่ายเท่านี้มาก่อน
ความแตกต่างที่แท้จริงไม่ได้อยู่ที่ทรัพยากร แต่ขึ้นอยู่กับว่าคุณพร้อมจะลงมือทำหรือไม่