ผู้เขียน: CJ_Blockchain
3 กุมภาพันธ์ 2025 โมเดล DeepSeek-R1 ได้เปิดตัวอย่างเงียบๆ บนแพลตฟอร์มอินเทอร์เน็ตซูเปอร์คอมพิวเตอร์แห่งชาติ
ในหนึ่งเดือนถัดมา ด้วยประสิทธิภาพที่เทียบเท่ากับโมเดลปิดระดับท็อป และต้นทุนการฝึกที่เทียบได้กับ “ราคาถูกสุดๆ” ก็ได้กลายเป็นปรากฏการณ์ทั่วโลก
เป็นจุดเริ่มต้นของการร่วงลงของหุ้น AI ในตลาดหุ้นอเมริกา และเปิดยุค “DeepSeek” ของ AI จีน
10 มีนาคม 2026 Bittensor’s Subnet 3 Templar ประกาศเสร็จสิ้นการฝึกโมเดลภาษาขนาดใหญ่แบบกระจายศูนย์ (LLM) ที่มีขนาดใหญ่ที่สุดในประวัติศาสตร์ — Covenant-72B
นี่คือโมเดลภาษาขนาดใหญ่แบบกระจายศูนย์ที่มีขนาดใหญ่ที่สุดในประวัติศาสตร์:
มีพารามิเตอร์ 7.2 พันล้านตัว บนชุดข้อมูลประมาณ 1.1 ล้านล้านโทเคน ทำงานผ่านเครือข่ายของ Bittensor Subnet 3 โดยไม่ต้องอนุญาต ให้โหนดอิสระมากกว่า 70 ตัวเข้าร่วมได้อย่างอิสระ
Bittensor ได้เข้าสู่ยุค DeepSeek ของตัวเองแล้ว
1. Templar (SN3): จากการเก็บข้อมูลสู่การเปลี่ยนแปลงแนวทางการฝึกหลัก
Templar เดิมคือ SN3 ที่ดำเนินการโดย Omega Labs ซึ่งเน้นการเก็บและขุดข้อมูลแบบมัลติโมดัล ในช่วงแรก ด้วยกลไกของ Bittensor ได้พัฒนาไปสู่การเปลี่ยนจาก “คนขนส่งข้อมูล” สู่ “ผู้สร้างโมเดล” อย่างเต็มตัว
ปัจจุบัน Templar เป็นโครงสร้างพื้นฐานสำหรับการฝึกโมเดลขนาดใหญ่แบบกระจายศูนย์ทั่วโลก โดยใช้กลไกจูงใจเพื่อรวบรวมพลังคำนวณจากทั่วโลกที่เป็นเครือข่ายแบบ heterogeneous ซึ่งมุ่งแก้ปัญหาค่าใช้จ่ายสูงในการฝึกโมเดลขนาดใหญ่และปัญหาการตรวจสอบแบบรวมศูนย์ ความสำเร็จของ Covenant-72B ยืนยันความ成熟ของโมเดลการผลิตแบบกระจายศูนย์นี้แล้ว
2. Covenant-72B: ทำลายขีดจำกัดของการฝึกแบบกระจายศูนย์ที่มีขนาดใหญ่ที่สุด
Covenant-72B เป็นผลงานสำคัญของ Templar และเป็นโมเดล pretraining ขนาดใหญ่ที่สุดในเครือข่ายแบบกระจายศูนย์ในปัจจุบัน
- พารามิเตอร์หลัก: มี 72 พันล้านพารามิเตอร์ ฝึกบนชุดข้อมูล DCLM ที่มีประสิทธิภาพสูง
- เปรียบเทียบประสิทธิภาพ: ในการทดสอบโมเดลพื้นฐาน ผลลัพธ์ใกล้เคียงกับ Llama-2-70B ของ Meta
- การปรับแต่งคำสั่ง: Covenant-72B-Chat ที่ผ่านการ fine-tune แล้ว มีความสามารถสูงในด้าน IFEval (การปฏิบัติตามคำสั่ง) และ MATH (ตรรกะคณิตศาสตร์) และบางดัชนีเหนือกว่าโมเดลปิดขนาดเท่ากัน
- ประสิทธิภาพการคำนวณ: ทำได้สูงสุด 450 โทเคนต่อวินาที ช่วยแก้ปัญหาความล่าช้าในการตอบสนองของโมเดลขนาดใหญ่ในแอปพลิเคชันจริง
3. อัลกอริทึม SparseLoCo: เครื่องยนต์พื้นฐานของการฝึกแบบกระจายศูนย์
การฝึกโมเดลขนาด 72B ในสภาพแวดล้อมอินเทอร์เน็ตทั่วไปเป็นความท้าทายที่ใหญ่ที่สุดคือแบนด์วิดธ์ระหว่างโหนด Templar ใช้เทคนิคหลัก SparseLoCo เพื่อให้เกิดความก้าวหน้าที่สำคัญ:
- การบีบอัดสูง: เลือกเฉพาะ 1-3% ของ gradient ที่สำคัญเท่านั้นในการส่งข้อมูล และทำให้ข้อมูลเป็น 2 บิต ลดความต้องการแบนด์วิดธ์อย่างมาก
- การซิงโครไนซ์แบบต่ำ: ต่างจากคลัสเตอร์แบบดั้งเดิมที่ซิงโครไนซ์ทุกขั้นตอน SparseLoCo อนุญาตให้โหนดทำงานใน local iteration 15-250 ครั้งก่อนซิงโครไนซ์แบบทั่วโลก
- การชดเชยข้อผิดพลาด: ด้วยกลไกสะสม gradient ในเครื่อง ทำให้แม้จะสูญเสียข้อมูลมากกว่า 97% ก็ยังคงรักษาความแม่นยำในการ converge ได้
เทคนิคนี้พิสูจน์ให้เห็นว่า แม้ไม่มีเครือข่ายเฉพาะทางอย่าง InfiniBand ก็สามารถสร้าง AI ชั้นนำได้ด้วยเครือข่ายทั่วไปทั่วโลก
4. การประเมินและปฏิกิริยาของอุตสาหกรรม
ความสำเร็จของ Templar ได้รับความสนใจจากวงการ AI และตลาดทุน:
- การยอมรับจากผู้เชี่ยวชาญ:
Jack Clark ผู้ร่วมก่อตั้ง Anthropic ระบุในรายงานวิเคราะห์ว่า Templar เป็นเครือข่ายการฝึกแบบกระจายศูนย์ที่ใหญ่ที่สุดในโลก และอัตราการพัฒนานั้นเกินกว่าที่อุตสาหกรรมคาดหวัง
Jason Calacanis (พิธีกร All-In Podcast และนักลงทุนใน Silicon Valley) เขียนบล็อกเชิงลึกเกี่ยวกับกลไกของ Bittensor และแนะนำให้คนซื้อ
Grayscale ยังคงถือครอง TAO เพิ่มขึ้นอย่างต่อเนื่อง และมองว่าเป็นสินทรัพย์หลักในเส้นทาง AI แบบกระจายศูนย์
DCG ก่อตั้ง Yuma เพื่อเร่งพัฒนา Bittensor (TAO) ซึ่งถือเป็นการลงทุนใน AI แบบกระจายศูนย์ที่ใหญ่ที่สุดและตรงที่สุดของ DCG
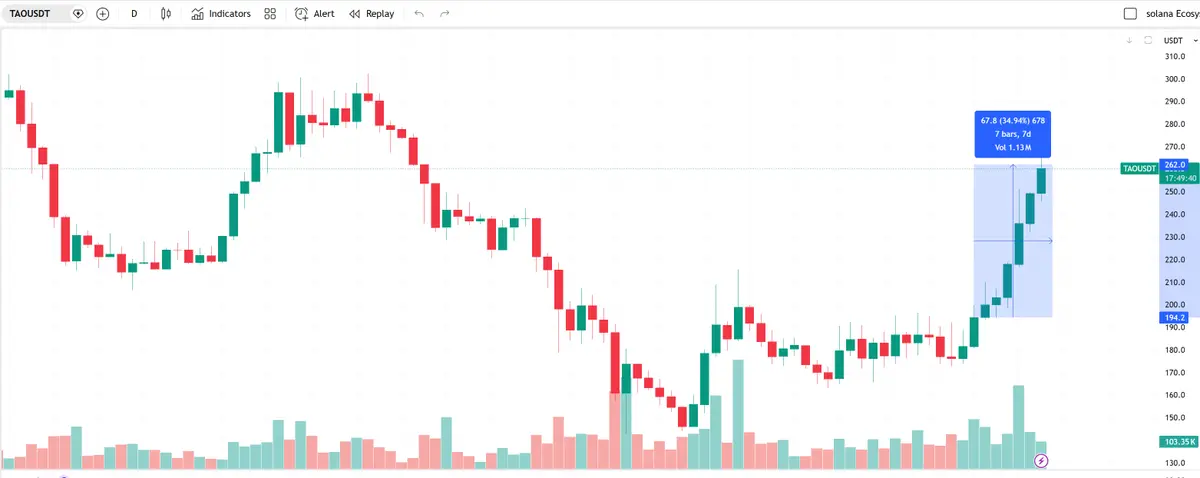
$TAO: หลังจาก Templar ประกาศเสร็จสิ้นการฝึกโมเดล 72B TAO ก็ปรับตัวขึ้นกว่า 30% ในช่วงที่ราคาบิตคอยน์ผันผวน แสดงความแข็งแกร่งอย่างชัดเจน
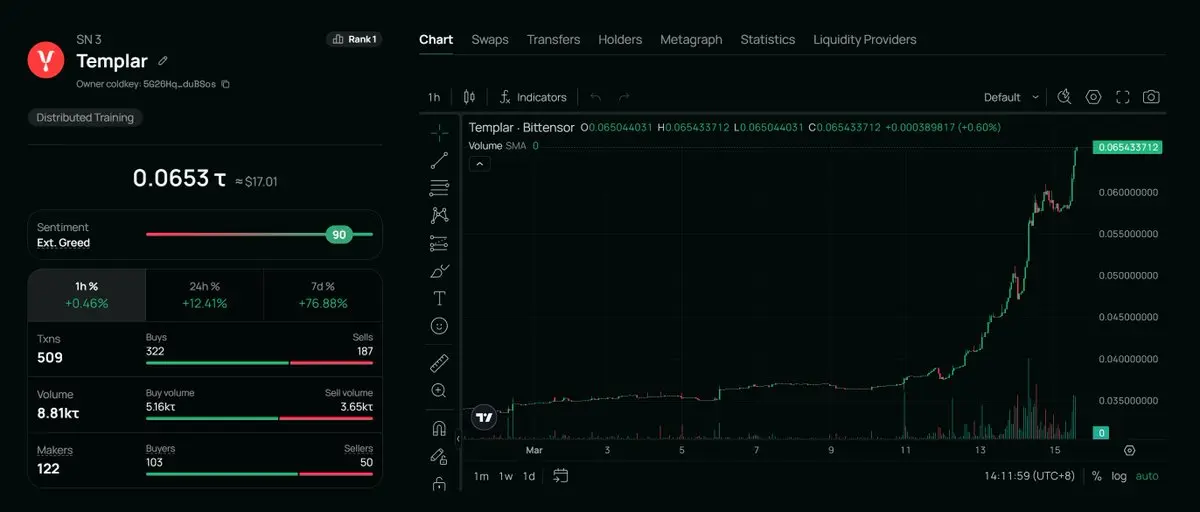
$Templar (SN-3): Templar เพิ่มขึ้น 75% ใน 7 วัน เป็นที่รู้จักกันว่าเป็น “มังกร” ของการปล่อย emission ของ Bittensor ปัจจุบัน Market Cap อยู่ที่ประมาณ 70 ล้านดอลลาร์
5. ศักยภาพการลงทุนใน Subnet และเพดานของระบบนิเวศ
ความสำเร็จของ Templar เปิดมุมมองใหม่ให้กับระบบนิเวศ Bittensor:
-
การเปิดเพดานมูลค่า: ช่วงเวลายาวนานที่สาธารณชนสงสัยว่า Bittensor เป็นแค่ “แรงจูงใจแบบอากาศ” Templar พิสูจน์ว่าโปรโตคอลนี้สามารถสร้างเครื่องมือที่มีความสามารถในการแข่งขันทางธุรกิจได้ ทำให้มูลค่าของ TAO เปลี่ยนจาก “การเล่าเรื่อง” เป็น “ผลิตภัณฑ์”
-
ศักยภาพของพลังคำนวณแบบ heterogeneous: ด้วยการพัฒนา “SparseLoCo แบบ heterogeneous” ในอนาคต กราฟิกการ์ดสำหรับผู้บริโภค เช่น RTX 4090 จะสามารถเข้าร่วมในการฝึกโมเดลพันล้านพารามิเตอร์ได้โดยตรง ทำให้ทรัพยากรคำนวณเท่าเทียมกัน
-
โอกาสใน Subnet: ภายใต้กลไก dTAO โหนดที่มีเทคโนโลยีแนวหน้าที่สามารถสร้างโมเดลคุณภาพสูงอย่าง Templar จะมีมูลค่าการถือครองระยะยาวสูงมาก
Templar ปัจจุบัน MC=75m, FDV=350m
ในขณะที่บริษัทโมเดลขนาดใหญ่ในปัจจุบัน เช่น OpenAI มีมูลค่าประมาณ 840 พันล้าน, Anthropic 350 พันล้าน, Minimax 45 พันล้าน
ไม่ได้หมายความว่า Templar จะเทียบเท่ากับบริษัทเหล่านี้ แต่ในยุคที่เรื่องราวความเป็นไปได้ของเทคโนโลยีหายาก ความสนใจลดลง และผู้คนไม่เชื่อในแนวทางแบบกระจายศูนย์ การปรากฏตัวของ Templar เป็นแรงใจสำคัญให้ AI แบบกระจายศูนย์
สรุป
Templar ได้พิสูจน์ให้เห็นว่าสภาพแวดล้อมแบบกระจายศูนย์ไม่เพียงแต่เก็บข้อมูลได้ แต่ยังสามารถสร้างปัญญาได้ Covenant-72B เป็นเพียงจุดเริ่มต้น เมื่อรวมกับ SN3 (การฝึก pretraining), SN39 (พลังคำนวณ) และ SN81 (การเรียนรู้เชิงลึกแบบเสริม) ระบบนิเวศนี้จะกลายเป็นต้นแบบของ OpenAI ที่ทำงานบนบล็อกเชน
อุตสาหกรรม Crypto ตั้งแต่ก่อตั้งจนถึงวันนี้ ได้พิสูจน์แล้วว่าหลายแนวคิดล้มเหลวไปแล้ว ทั้งการเก็บข้อมูลแบบกระจายศูนย์ การคำนวณแบบกระจายศูนย์ และคอมพิวเตอร์แบบกระจายศูนย์ ก็ล้วนดูเหมือนจะล้มเหลว แต่ก็ยังมีโครงการที่เดินหน้าต่อไปอย่างมั่นคงและสร้างผลงาน
ความสำเร็จของ Templar ไม่เพียงแต่เป็น DeepSeek ของ Bittensor แต่ยังอาจเป็น DeepSeek ของ Crypto ด้วย
