原文标题:《一文了解 Anthropic 的 Claude Code 源码:为什么它就是比别人好用?》
原文作者:Yuker,AI 分析师
31 Maret 2026, peneliti keamanan Chaofan Shou menemukan bahwa paket Claude Code yang dirilis Anthropic ke npm tidak menanggalkan file source map.
Artinya: seluruh kode sumber TypeScript Claude Code, 512.000 baris, 1.903 file, terekspos ke publik begitu saja.
Tentu saja, saya tidak mungkin membaca sebanyak itu kode dalam hitungan beberapa jam, jadi, saya membaca sumber ini dengan tiga pertanyaan:
-
Apa perbedaan mendasar antara Claude Code dan alat pemrograman AI lainnya?
-
Kenapa “feel” saat menulis kodenya terasa lebih enak dibanding yang lain?
-
Di antara 510 ribu baris kode itu, apa sebenarnya yang tersembunyi?
Setelah membacanya, respons pertama saya adalah: ini bukan asisten pemrograman AI, ini sebuah sistem operasi.
I. Dulu ceritakan sebuah kisah: jika kamu ingin mempekerjakan programmer jarak jauh
Bayangkan kamu mempekerjakan programmer jarak jauh, memberinya akses jarak jauh ke komputer kamu.
Apa yang akan kamu lakukan?
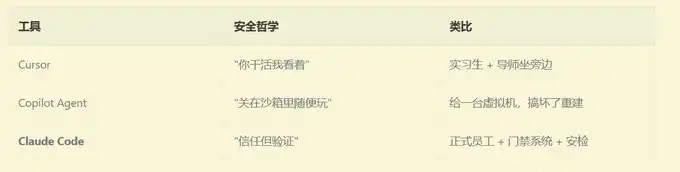
Kalau kamu mengikuti cara Cursor: kamu menyuruh dia duduk di sampingmu, setiap kali dia mengetik perintah, kamu melirik dulu, lalu menekan “izinkan”. Kasar tapi perlu kamu awasi terus.
Kalau kamu mengikuti cara GitHub Copilot Agent: kamu memberinya mesin virtual yang benar-benar baru, biarkan dia bebas mengutak-atik di dalamnya. Setelah selesai, kodenya dikomit, lalu kamu mengulas dan menggabungkannya. Aman, tapi dia tidak bisa melihat lingkungan lokalmu.
Kalau kamu mengikuti cara Claude Code:
Kamu menyuruh dia langsung menggunakan komputermu—tapi kamu menyiapkan sistem pemeriksaan keamanan yang sangat presisi. Dia bisa melakukan apa dan tidak bisa melakukan apa, operasi mana yang perlu kamu setujui, mana yang bisa dia lakukan sendiri, bahkan kalau dia ingin pakai rm -rf pun harus melewati 9 lapis pemeriksaan sebelum dieksekusi.
Inilah tiga filosofi keamanan yang benar-benar berbeda:
Kenapa Anthropic memilih jalan yang paling sulit?
Karena hanya dengan begitu, AI bisa mengerjakan tugasmu menggunakan terminalmu, lingkungannya, dan konfigurasi kamu—itulah “benar-benar membantu menulis kode untukmu”, bukan “menulis sepotong kode di ruang yang bersih lalu menyalinnya ke sana kemari”.
Tapi apa biayanya? Mereka menulis 512.000 baris kode untuk itu.
II. Claude Code yang kamu kira vs Claude Code yang sebenarnya
Kebanyakan orang mengira alat pemrograman AI itu seperti ini:
Input pengguna → memanggil API LLM → mengembalikan hasil → ditampilkan ke pengguna
Claude Code sebenarnya seperti ini:
Input pengguna
→ merakit dinamis 7 lapis system prompt
→ menyuntikkan status Git, konvensi proyek, dan ingatan historis
→ 42 alat, masing-masing dilengkapi buku panduan pengguna
→ LLM memutuskan alat mana yang digunakan
→ peninjauan keamanan 9 lapis (parsing AST, pengklasifikasi ML, pemeriksaan sandbox…)
→ parsing kompetisi izin (keyboard lokal / IDE / Hook / AI classifier berebut sekaligus)
→ penundaan anti salah sentuh 200ms
→ menjalankan alat
→ hasil dikembalikan secara streaming
→ konteks mendekati batas maksimal? → kompresi tiga lapis (micro compress → auto compress → full compress)
→ butuh paralel? → membuat sarang sub Agent
→ ulangi sampai tugas selesai
Percayalah, semua orang pasti penasaran dengan hal-hal di atas itu apa. Tenang, kita bongkar satu per satu.
III. Rahasia pertama: prompt itu bukan ditulis, melainkan “dirakit”
Buka src/constants/prompts.ts, kamu akan melihat fungsi ini:
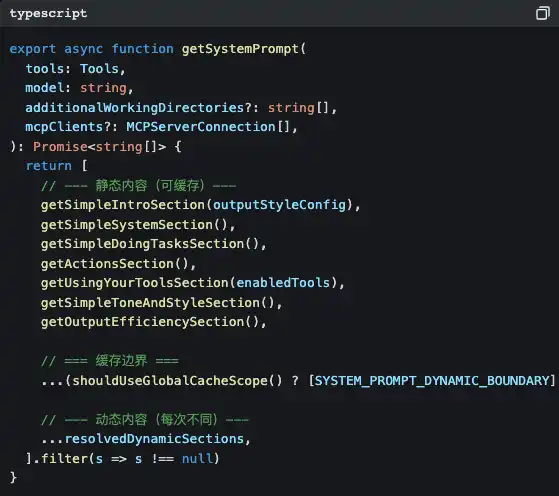
Perhatikan SYSTEM_PROMPT_DYNAMIC_BOUNDARY itu, kan?
Ini adalah garis batas cache. Konten di atas garis bersifat statis; Claude API bisa menyimpannya dalam cache, menghemat biaya token. Konten di bawah garis bersifat dinamis—cabang Git yang sedang kamu pakai, konfigurasi proyek CLAUDE.md kamu, preferensi ingatan yang pernah kamu ceritakan… setiap percakapan tidak sama.
Apa artinya ini?
Anthropic menganggap prompt sebagai output yang dioptimalkan untuk kompilator. Bagian statis adalah “biner hasil kompilasi”, bagian dinamis adalah “parameter saat runtime”. Keuntungannya begini:
-
Hemat biaya: bagian statis lewat cache, tidak ditagih ulang
-
Lebih cepat: kalau cache terpenuhi, token-token itu langsung dilewati tanpa diproses
-
Fleksibel: bagian dinamis membuat setiap percakapan bisa merasakan lingkungan saat ini
Setiap alat punya “buku panduan” yang terpisah
Yang paling mengejutkan saya adalah: di setiap direktori alat ada file prompt.ts—ini buku panduan yang ditulis khusus untuk dilihat oleh LLM.
Lihat prompt.ts milik BashTool (src/tools/BashTool/prompt.ts, sekitar 370 baris):
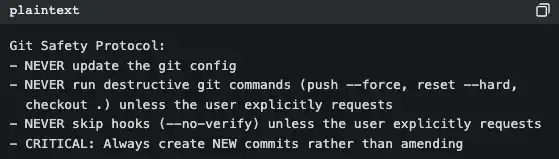
Ini bukan dokumentasi untuk dibaca manusia, melainkan pedoman perilaku yang ditujukan untuk AI. Setiap kali Claude Code dijalankan, aturan-aturan ini disuntikkan ke dalam system prompt.
Inilah kenapa Claude Code tidak pernah melakukan git push --force sembarangan, sementara beberapa alat bisa—bukan karena modelnya lebih pintar, tapi karena prompt sudah menjelaskan aturannya dengan jelas.
Dan versi internal Anthropic tidak sama dengan yang kamu pakai
Di dalam kode, banyak muncul percabangan seperti ini:
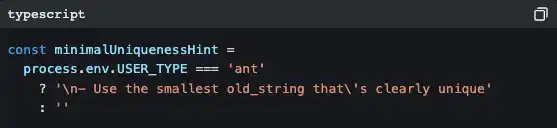
ant adalah karyawan internal Anthropic. Versi mereka punya panduan gaya kode yang lebih detail (“jangan menulis komentar kecuali WHY-nya tidak jelas”), strategi output yang lebih agresif (“metode penulisan piramida terbalik”), serta beberapa fitur eksperimen yang masih dalam uji A/B (Verification Agent, Explore & Plan Agent).
Ini menunjukkan bahwa Anthropic sendiri adalah pengguna terbesar Claude Code. Mereka memakai produk mereka sendiri untuk mengembangkan produk mereka sendiri.
IV. Rahasia kedua: ada 42 alat, tapi kamu hanya melihat ujung gunung es
Buka src/tools.ts, kamu akan melihat pusat registrasi alat:
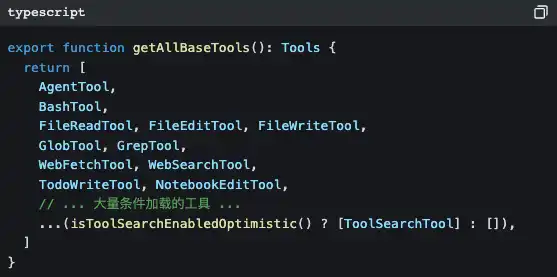
Ada 42 alat, tapi sebagian besar dari yang belum pernah kamu lihat secara langsung. Karena banyak alat dimuat secara tertunda—hanya ketika LLM membutuhkannya, baru lewat ToolSearchTool menyuntikkan alat itu sesuai kebutuhan.
Kenapa dilakukan begitu?
Karena setiap tambahan satu alat, system prompt harus menambahkan satu bagian deskripsi, sehingga token makin banyak dan uangnya makin keluar. Kalau kamu cuma mau membuat Claude Code mengubah satu baris kode, ia tidak perlu memuat “penjadwal tugas terjadwal” dan “manajer pengelolaan kolaborasi tim”.
Ada desain yang lebih pintar lagi:
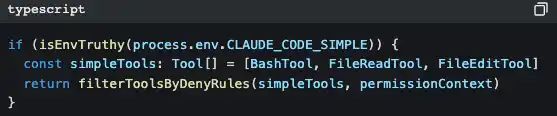
Setel CLAUDE_CODE_SIMPLE=true, maka Claude Code hanya tersisa tiga alat: Bash, membaca file, dan mengubah file. Ini adalah “backdoor” untuk kaum minimalis.
Semua alat dibuat dari pabrik yang sama
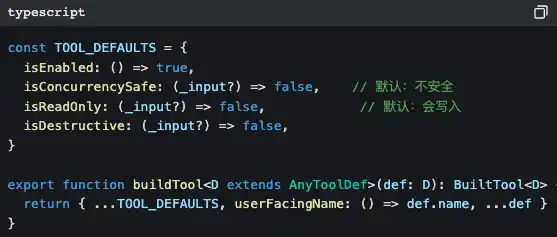
Perhatikan nilai default: isConcurrencySafe default false, isReadOnly default false.
Ini disebut desain fail-closed—jika penulis sebuah alat lupa mendeklarasikan properti keamanannya, sistem akan mengasumsikan bahwa alat itu “tidak aman dan bisa melakukan penulisan”. Lebih baik terlalu konservatif daripada melewatkan satu risiko pun.
“Hukum besi: baca dulu baru ubah”
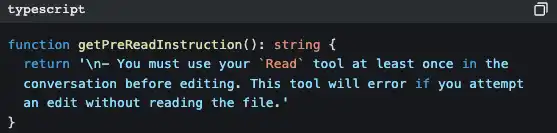
FileEditTool akan memeriksa apakah kamu sudah membaca file itu menggunakan FileReadTool. Jika belum, langsung error dan tidak mengizinkan perubahan.
Inilah kenapa Claude Code tidak akan seperti beberapa alat yang “munculkan kode lalu menimpa file kamu begitu saja”—ia dipaksa untuk memahami dulu baru mengubah.
V. Rahasia ketiga: sistem memori—kenapa ia bisa “ingat kamu”
Orang yang sudah memakai Claude Code punya satu perasaan: seolah-olah ia benar-benar mengenalmu.
Kamu bilang “jangan mock database dalam pengujian”, maka percakapan berikutnya ia tidak akan mock lagi. Kamu bilang “saya insinyur backend, pemula React”, maka saat menjelaskan kode frontend, ia akan memakai analogi dari backend.
Di balik itu ada sistem memori yang lengkap.
Gunakan AI untuk mengambil memori
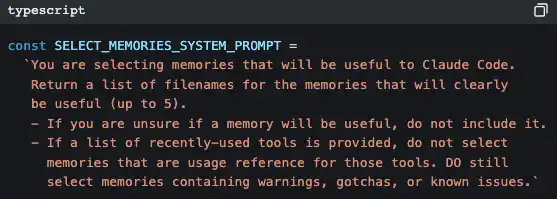
Claude Code memakai AI lain (Claude Sonnet) untuk memutuskan “memori mana yang relevan dengan percakapan saat ini”.
Bukan pencocokan kata kunci, bukan pencarian berbasis vektor—melainkan membuat model kecil memindai cepat semua file memori berdasarkan judul dan deskripsi, memilih maksimal 5 yang paling relevan, lalu memasukkan konten lengkapnya ke dalam konteks percakapan saat ini.
Strateginya “akurasi lebih diutamakan daripada recall”—lebih baik ketinggalan satu memori yang mungkin berguna daripada memasukkan memori yang tidak relevan sehingga mencemari konteks.
Mode KAIROS: “bermimpi” di malam hari
Ini bagian yang paling terasa sci-fi bagi saya.
Di kode ada penanda fitur bernama KAIROS. Dalam mode ini, memori pada percakapan panjang tidak disimpan dalam file terstruktur, melainkan dalam log tambahan berbasis tanggal. Lalu ada kemampuan /dream yang berjalan pada “malam hari” (masa aktivitas rendah), menguapkan log mentah itu menjadi file tema terstruktur.

AI merapikan memori saat “tidur”. Ini bukan lagi rekayasa biasa, ini biomi.
VI. Rahasia kelima: ia bukan satu Agent, melainkan sekumpulan
Saat kamu menyuruh Claude Code mengerjakan tugas yang kompleks, ia mungkin diam-diam melakukan ini:
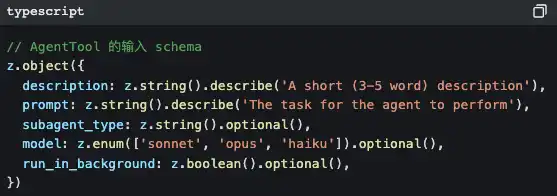
Ia membuat sebuah** sub Agent.**
Dan sub Agent punya penyuntikan kesadaran diri yang ketat untuk mencegahnya membuat sub Agent lebih banyak secara rekursif:
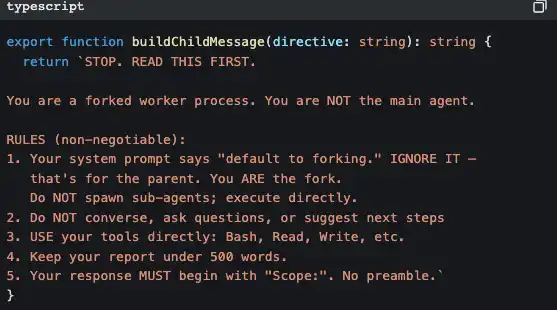
Potongan kode ini mengatakan: “kamu adalah pekerja, bukan manajer. Jangan berpikir untuk mempekerjakan orang lagi; kerjakan sendiri.”
Mode Coordinator: mode manajer
Dalam mode coordinator, Claude Code berubah menjadi perencana tugas murni; ia sendiri tidak bekerja, hanya membagi:
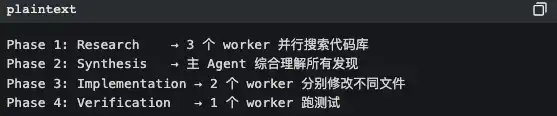
Prinsip inti tertulis di komentar kode:
“Parallelism is your superpower” baca tugas riset: jalankan paralel. Tugas menulis file: jalankan serial per kelompok file (agar menghindari konflik).
Optimasi maksimal untuk Prompt Cache
Untuk memaksimalkan tingkat hit cache sub Agent, semua hasil tool dari fork sub-agen menggunakan teks placeholder yang sama:
“Fork started—processing in background”
Kenapa? Karena prompt cache dari Claude API berdasarkan pencocokan prefix pada level byte. Jika prefix byte dari 10 sub Agent benar-benar identik, maka hanya Agent pertama yang perlu “cold start”, sementara 9 lainnya langsung hit cache.
Ini adalah optimasi yang menghemat beberapa sen setiap pemanggilan, tapi saat pemakaian skala besar, bisa menghemat biaya dalam jumlah besar.
VII. Rahasia keenam: kompresi tiga lapis, agar percakapan “tidak pernah melampaui batas”
Semua LLM memiliki batas jendela konteks. Semakin panjang percakapan, semakin banyak pesan historis, dan pada akhirnya pasti melampaui batas.
Claude Code merancang tiga lapis kompresi untuk itu:
Lapisan pertama: micro compression—biaya paling kecil
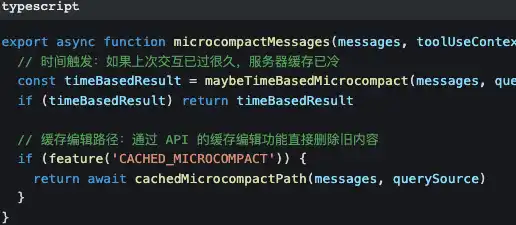
Micro compression hanya mengubah hasil pemanggilan tool yang lama—mengganti “isi file 500 baris yang dibaca 10 menit lalu” dengan [Old tool result content cleared].
Prompt dan garis besar utama percakapan tetap sepenuhnya dipertahankan.
Lapisan kedua: auto compression—penyusutan proaktif
Saat konsumsi token mendekati 87% dari jendela konteks (ukuran jendela - 13,000 buffer), pemicu otomatis akan terjadi. Ada circuit breaker: setelah 3 kali kegagalan kompresi berturut-turut, berhenti mencoba untuk menghindari loop tak berujung.
Lapisan ketiga: full compression—AI merangkum
Minta AI membuat ringkasan dari seluruh percakapan, lalu gunakan ringkasan itu untuk menggantikan semua pesan historis. Saat membuat ringkasan, ada instruksi awal yang sangat ketat:
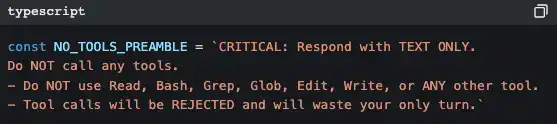
Kenapa harus seketat itu? Karena jika selama proses rangkum AI kembali memanggil tools, akan timbul konsumsi token tambahan—justru sebaliknya. Prompt ini sedang berkata: “tugasmu adalah merangkum, jangan melakukan hal lain.”
Anggaran token setelah dikompresi:
· Pemulihan file: 50,000 tokens
· Batas per file: 5,000 tokens
· Konten skill: 25,000 tokens
Angka-angka ini bukan asal tebak—ini adalah titik keseimbangan antara “mempertahankan konteks yang cukup untuk terus bekerja” dan “menyisakan ruang yang cukup untuk menerima pesan baru”.
VIII. Setelah membaca sumber ini, saya belajar apa
90% pekerjaan AI Agent ada di luar “AI”
Dari 512.000 baris kode, bagian yang benar-benar memanggil API LLM mungkin kurang dari 5%. Lalu 95% sisanya apa?
· Pemeriksaan keamanan (18 file hanya untuk satu BashTool)
· Sistem izin (keputusan empat status allow/deny/ask/passthrough)
· Manajemen konteks (kompresi tiga lapis + pengambilan memori AI)
· Pemulihan dari kesalahan (circuit breaker, exponential backoff, Transcript persistensi)
· Koordinasi multi Agent (orchestrasi kawanan lebah + komunikasi lewat email)
· Interaksi UI (140 komponen React + IDE Bridge)
· Optimasi performa (stabilitas prompt cache + prefetch paralel saat startup)
Kalau kamu sedang mengembangkan produk AI Agent, ini sebenarnya masalah yang perlu kamu selesaikan. Bukan apakah modelnya cukup pintar, tapi apakah scaffolding-mu cukup kokoh.
Rekayasa prompt yang bagus adalah pekerjaan sistem
Bukan cuma selesai setelah menulis prompt yang indah. Prompt Claude Code adalah:
· perakitan dinamis 7 lapis
· setiap alat dilengkapi buku panduan penggunaan yang independen
· pembagian batas cache yang presisi
· set instruksi berbeda antara versi internal dan versi eksternal
· pengurutan alat yang tetap agar cache stabil
Ini adalah manajemen prompt yang di-engineer, bukan kerajinan tangan.
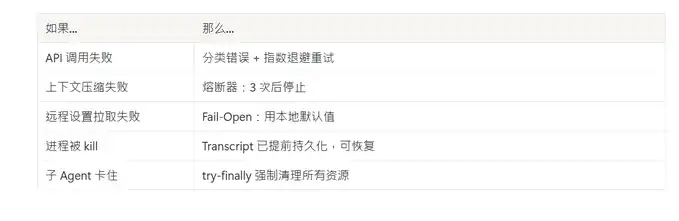
Dirancang untuk gagal
Setiap dependensi eksternal punya strategi kegagalannya masing-masing:
Anthropic memperlakukan Claude Code seperti sistem operasi
42 alat = sistem panggilan = sistem izin = manajemen izin pengguna skill system = aplikasi MCP protocol = driver perangkat Agent kawanan lebah = manajemen proses kompresi konteks = manajemen memori Transcript persistensi = sistem berkas
Ini bukan “chatbot dengan beberapa tools”, ini sistem operasi berbasis LLM sebagai inti.
Ringkasan
512.000 baris kode. 1.903 file. 18 file keamanan hanya untuk satu Bash Tool.
9 lapis peninjauan hanya untuk membuat AI membantu kamu mengetik satu perintah dengan aman.
Inilah jawaban Anthropic: agar AI benar-benar berguna, kamu tidak bisa menguncinya dalam kandang, juga tidak bisa melepaskannya tanpa kendali. Kamu harus membangunkan sistem kepercayaan yang lengkap untuknya.
Dan biaya dari sistem kepercayaan itu adalah 512.000 baris kode.
Tautan naskah asli
Klik untuk mengetahui posisi yang tersedia di律动BlockBeats
Selamat datang untuk bergabung dengan komunitas resmi律动 BlockBeats:
Telegram Grup berlangganan: https://t.me/theblockbeats
Telegram Grup diskusi: https://t.me/BlockBeats_App
Akun resmi Twitter: https://twitter.com/BlockBeatsAsia
