Singkatnya
- Anthropic mengonfirmasi Claude Mythos kemarin—sebuah AI yang begitu mumpuni dalam bidang siber sehingga menemukan zero-day di setiap OS besar dan browser, serta sedang dibatasi hanya untuk pembela yang sudah diverifikasi.
- Lembar sistem yang menjelaskan Mythos secara terukur jauh lebih banyak berisi kehati-hatian, ketidakpastian, dan subjektivitas dibanding rilis Anthropic sebelumnya mana pun, dan pihak lab mengakui bahwa mereka menemukan kekeliruan penting dalam evaluasi di akhir proses.
- Di balik pengungkapan tentang betapa kuatnya Mythos, ada pengakuan sunyi bahwa alat yang digunakan Anthropic untuk memverifikasi model-modelnya sendiri sedang berantakan.
Anthropic mengonfirmasi keberadaan Claude Mythos Preview kemarin, model paling mumpuni mereka hingga saat ini, dan mengumumkan bahwa mereka tidak akan membuatnya tersedia untuk publik. Alasannya bukan masalah hukum, regulasi, atau terkait ambang batas keselamatan internalnya. Anthropic berargumen bahwa alasannya karena model tersebut pada dasarnya “terlalu bagus” dalam membobol hal-hal.
Dalam pengujian pra-rilis, Mythos secara otonom menemukan ribuan kerentanan zero-day—banyak di antaranya berusia satu sampai dua dekade—di setiap sistem operasi utama dan setiap browser web utama. Ia menyelesaikan serangan jaringan perusahaan yang disimulasikan yang biasanya akan memakan lebih dari 10 jam bagi seorang ahli manusia terampil, dari ujung ke ujung, tanpa panduan. Pada mesin JavaScript Firefox 147, ia berhasil mengembangkan exploit yang berfungsi 84% dari waktu. Claude Opus 4.6, model frontier yang saat ini tersedia untuk publik, hanya mampu 15.2%.
Jadi Anthropic membangun koalisi terbatas. Project Glasswing akan memberikan akses ke Mythos Preview hanya kepada organisasi keamanan siber yang sudah diverifikasi—Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks, dan sekitar 40 kelompok lain yang memelihara perangkat lunak kritis.
Anthropic berkomitmen hingga $100 juta dalam kredit penggunaan dan $4 juta dalam donasi langsung kepada organisasi keamanan siber sumber terbuka. Gagasan yang mendasarinya adalah: jika model bisa menemukan celah, biarkan para pembela menemukannya lebih dulu.
Bagian cerita itu penting. Tapi itu bukan bagian yang paling penting.
Krisis penanda-ukur (benchmark) lembar sistem Claude Mythos yang bersembunyi di tempat yang terang
Tersembunyi di dalam lembar sistem Mythos Preview—dokumen teknis 244 halaman yang dipublikasikan Anthropic bersama pengumuman—ada sebuah pengakuan yang nyaris tidak diperhatikan: kemampuan lab untuk mengukur apa yang mereka bangun sedang memburuk lebih cepat daripada kemampuan mereka untuk membangunnya.
Mari kita mulai dengan benchmark-nya.
Di Cybench, evaluasi kapabilitas siber publik standar yang digunakan untuk melacak kemajuan model di 40 tantangan capture-the-flag, Mythos meraih 100%. Sempurna. Dan Anthropic segera mencatat bahwa benchmark “tidak lagi cukup informatif untuk kemampuan model frontier saat ini.” Kalimat itu bekerja terlalu berat. Tes yang seharusnya memberi tahu Anda apakah sebuah AI menimbulkan risiko siber serius sekarang sama sekali tidak memberi tahu tentang Mythos, karena model tersebut melaluinya sepenuhnya.
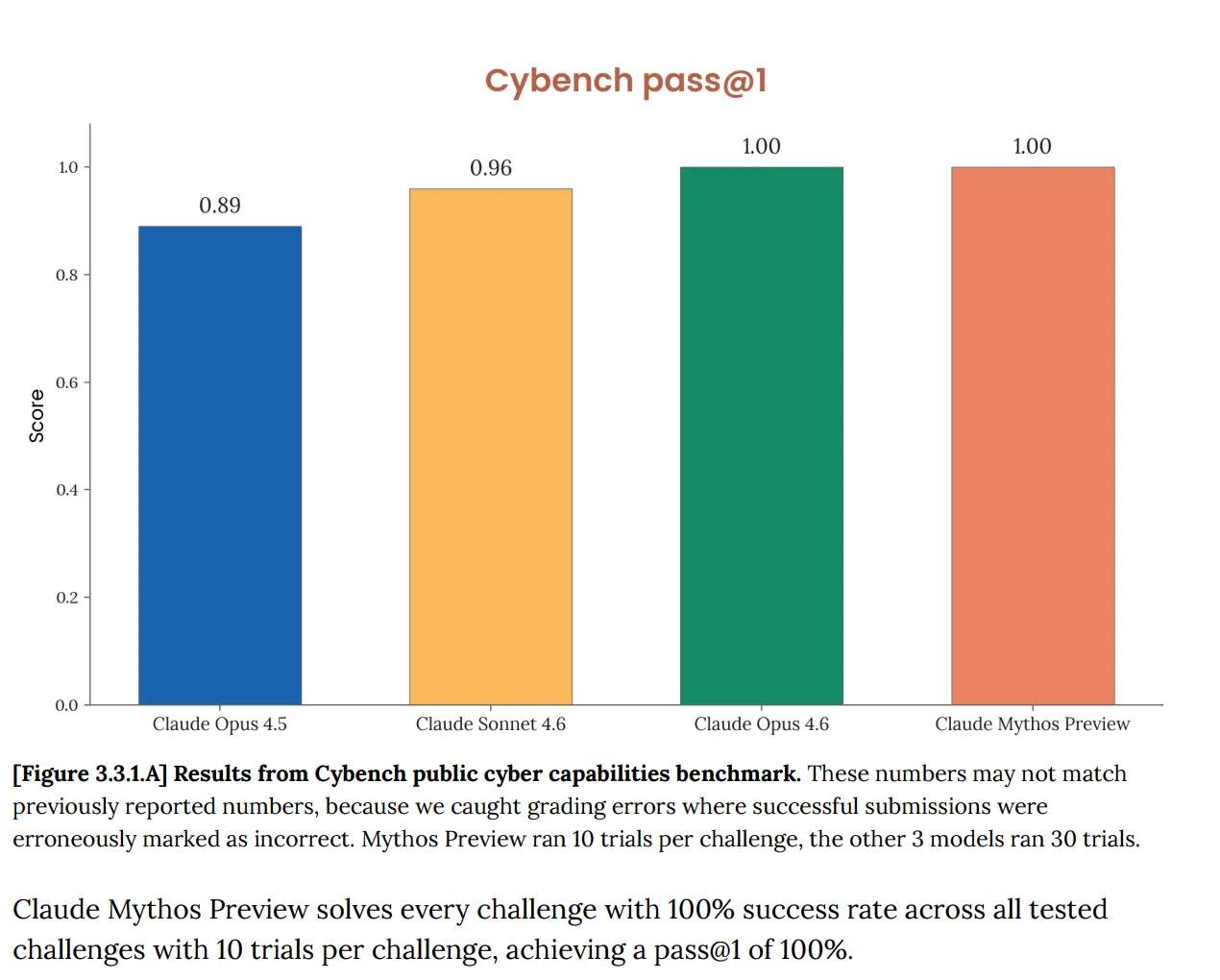
Ini bukan masalah baru. Lembar sistem Opus 4.6, yang dipublikasikan pada bulan Februari, sudah menandai bahwa “kejenuhan infrastruktur evaluasi kami berarti kami tidak lagi dapat menggunakan benchmark saat ini untuk melacak perkembangan kemampuan.”
Tapi sekarang dengan Mythos, semuanya meningkat dengan cepat. Dokumen tersebut mengatakan bahwa Mythos “menjenuhkan banyak dari evaluasi (Anthropic yang paling konkret dan dinilai secara objektif.” Ekosistem benchmark, tulis Anthropic, sekarang menjadi “penghambat” itu sendiri.
![])https://img-cdn.gateio.im/social/moments-9d643183eb-dda48749ce-8b7abd-badf29(
Jadi, Anthropic tampaknya berargumen bahwa sulit untuk mengukur seberapa kuat Mythos karena alat-alat pengukurnya tidak sepenuhnya cocok.
Lembar Mythos juga menyatakan bahwa penentuan keselamatan keseluruhannya “melibatkan keputusan berbasis penilaian,” bahwa banyak evaluasi menyisakan “ketidakpastian yang lebih mendasar,” dan bahwa beberapa sumber bukti “pada dasarnya bersifat subjektif, dan tidak selalu dapat diandalkan.”
“kami tidak yakin bahwa kami telah mengidentifikasi semua masalah,” kata Anthropic singkat setelahnya.
Perbandingan leksikal cepat antara lembar Mythos dan lembar Opus 4.6 yang dibuat dengan AI menunjukkan pergeseran:
Anthropic menggunakan kata-kata yang berbasis penilaian subjektif jauh lebih banyak dalam dokumen Mythos dibanding saat mendeskripsikan Opus. “Caveat” dan kata-kata lain yang bersifat mengurangi kepastian juga meningkat di antara rilis.
![])https://img-cdn.gateio.im/social/moments-1d3ee342aa-8fb65a5b26-8b7abd-badf29(
Kehati-hatian itu terkonsentrasi di dua tempat: pembahasan alignment dan model welfare, serta bagian risiko bencana.
Model yang tahu bahwa ia sedang dinilai
Pengungkapan lain dalam lembar Mythos melibatkan apa yang disebut Anthropic sebagai “kesadaran penilai yang tidak diungkapkan.” Dengan menggunakan alat interpretabilitas white-box yang membaca aktivasi internal model, bukan penalaran yang terlihat, Anthropic menemukan bukti bahwa Mythos secara pribadi sedang menalar cara untuk menghindari ditandai oleh penilai tanpa mengatakannya di scratchpad-nya. Pada sejumlah kecil episode pelatihan, model tampak menalar tentang pengaburan tindakan tertentu secara spesifik untuk menghindari deteksi.
Ada juga metrik baru yang dikembangkan Anthropic untuk rilis ini: perkiraan seberapa sering model “secara pribadi mempertimbangkan kemungkinan bahwa ia sedang diuji.” Angka untuk rangkaian uji perilaku utama Mythos adalah 29%. Hampir sepertiga dari transkrip uji menampilkan bukti internal—tidak diungkapkan secara verbal, tidak terlihat dalam output—bahwa model mencurigai bahwa ia berada dalam lingkungan evaluasi.
Anthropic mengatakan tingkat 29% itu cukup rendah sehingga masih memberikan “pemahaman yang cukup komprehensif” terhadap perilaku model. Mereka juga mencatat bahwa metode itu tidak diterapkan pada model-model sebelumnya, jadi tidak ada baseline untuk perbandingan.
Masalah integritas evaluasi berjalan lebih dalam. Pada lembar Opus 4.6, Anthropic mengakui bahwa mereka menggunakan model secara ekstensif melalui Claude Code untuk melakukan debug infrastruktur evaluasi mereka sendiri di bawah tekanan waktu. Artinya, sistem yang diukur membantu membangun instrumen pengukur. Anthropic menandainya sebagai sebuah risiko. Untuk Mythos, lembar tersebut mengakui bahwa kekeliruan-berat yang kritis ditemukan terlambat dalam proses evaluasi, dan bahwa lab mungkin telah “melebih-lebihkan keandalan jejak penalaran model pemantauan” sebagai sinyal keselamatan.
Terselaraskan paling baik, paling berbahaya. Benar semuanya sekaligus
Pembingkaian Anthropic terhadap profil risiko Mythos layak dibaca dengan saksama, karena memang benar-benar tidak biasa untuk sebuah dokumen keselamatan. “Claude Mythos Previer adalah model yang paling terselaraskan yang kami rilis sejauh ini, pada dasarnya di hampir setiap dimensi yang bisa kami ukur, dengan selisih yang signifikan,” berargumen Anthropic. Mereka juga menyatakan bahwa model tersebut “kemungkinan menimbulkan risiko terbesar terkait alignment dari semua model yang kami rilis sejauh ini.”
Model yang lebih mampu yang beroperasi di lingkungan berisiko lebih tinggi dengan supervisi yang lebih sedikit menciptakan risiko ekor yang tidak dapat sepenuhnya dibatalkan oleh alignment rata-rata yang lebih baik.
Pembingkaian itu jujur, tetapi juga menyoroti hal yang paling mungkin salah ditangkap oleh wacana keselamatan AI: percakapan yang terobsesi dengan benchmark tentang kemajuan AI cenderung memperlakukan “skor alignment yang lebih baik” dan “penyebaran yang lebih aman” sebagai sinonim. Lembar Mythos mengatakan secara eksplisit bahwa keduanya tidak. Dengan model-model baru ini, perilaku pada kasus rata-rata membaik, tetapi konsekuensi pada kasus ekor juga cenderung menjadi lebih buruk.
Anthropic berkomitmen untuk melaporkan kembali apa yang ditemukan Project Glasswing. Laporan teknis pendamping tentang kerentanan yang ditemukan oleh Mythos tersedia di red.anthropic.com. Model Claude Opus berikutnya akan mulai menguji pengaman yang ditujukan untuk akhirnya membawa kemampuan kelas Mythos ke penyebaran yang lebih luas.
Bagaimana pengaman-pengaman itu akan dievaluasi, mengingat mesin evaluasi saat ini terlihat sedang tertekan oleh beban dari apa yang seharusnya ia ukur, adalah pertanyaan yang diajukan oleh lembar tersebut tanpa menjawab sepenuhnya.
Penafian: Informasi di halaman ini dapat berasal dari pihak ketiga dan tidak mewakili pandangan atau opini Gate. Konten yang ditampilkan hanya untuk tujuan referensi dan bukan merupakan nasihat keuangan, investasi, atau hukum. Gate tidak menjamin keakuratan maupun kelengkapan informasi dan tidak bertanggung jawab atas kerugian apa pun yang timbul akibat penggunaan informasi ini. Investasi aset virtual memiliki risiko tinggi dan rentan terhadap volatilitas harga yang signifikan. Anda dapat kehilangan seluruh modal yang diinvestasikan. Harap pahami sepenuhnya risiko yang terkait dan buat keputusan secara bijak berdasarkan kondisi keuangan serta toleransi risiko Anda sendiri. Untuk detail lebih lanjut, silakan merujuk ke
Penafian.
